



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

みなさんこんにちは。アナリティクスコンサルティングユニットの崎山です。
2022年にChatGPTが登場して以来、LLM(LargeLanguageModels、大規模言語モデル)、およびGenerativeAI(生成AI)に関する技術革新が日々進み、それを取り巻く社会情勢もめまぐるしく変化しています。
これらの技術の社会実装に向けた取り組みや企業への支援を強化するため、ブレインパッドでもLLM/生成AIに関する技術調査プロジェクトが進行しており、最新トレンドの継続的なキャッチアップと情報共有を実施しています。
本連載では、毎週の勉強会で出てくるトピックのうち個人的に面白いなと思った事例・技術・ニュースをピックアップしてご紹介していきます。
※本記事は2024/7/4時点の情報をもとに記載しています
【関連記事】
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

技術の進歩により、LLMやRAG(Retrieval-Augmented Generation、検索拡張生成。LLMによるテキスト生成に外部情報の検索を組み合わせるシステム)は現在数百万トークンもの文字を処理できる能力を持っています。
一方で、LLMに長い文章を入力した際の出力性能には未だ限界があります。入力コンテキストから必要情報を見つけ、それを用いて質問に答えるタスクにおいて、実は長文コンテキストの真ん中に重要情報が位置する場合にこれを逃してしまうことが多いのだそうです。これをLost in the middle問題といい、2023年頃にスタンフォード大学から論文が出て大きな話題になりました。
当該調査論文では、LLMが長い入力コンテキストをどのように利用して出力を行うかを検証しており、その結果、質問に対する関連情報(答えを含む文書)が入力コンテキストの最初または最後に置かれていると高い精度で情報を拾えるが、中央に関連情報を配置すると著しく精度が落ちることが分かりました。
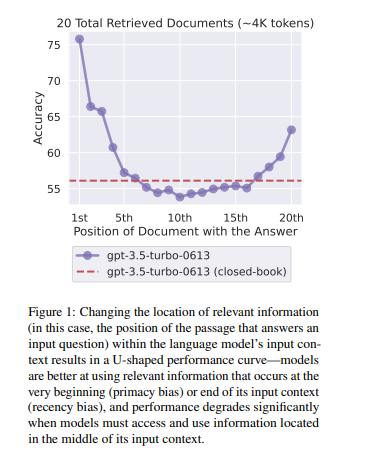
LLMは人間がこれまでに作り出した大量の文章を学習データソースとして構築されているわけですが、人間の文章は最初と最後に重要な記述がなされることが多い傾向があります。ニュースでも論文でも最初に全体のサマリが書かれていたり、ニュースの最後にこれまでの主張を締めくくるための結論パートが設けられていたりすることが多いというのは感覚的にも理解いただけるのではないでしょうか。この文章の記述傾向を LLMが学習しているためにLost in the middle問題が発生したと言われています。
従来はこのLost in the middle問題の評価が十分にできていたわけではありませんでした。というのも従来の評価指標は、今の最先端モデルにとっては簡単すぎたのです。
さて、本題に移ります。今回ご紹介する論文では、このLost in the middle問題にどれだけ対応できているかを調査するための評価ベンチマークSummary of a Haystack(SummHay)を提案しています。簡単に概要をご説明します。
まず、Haystackとは干し草の山という意味です。英語のことわざにIt’s like looking for a needle in the haystack.(干し草の中から針を探す:見つかる当てのないものを探して無駄骨を折ること、の意)というのがありますが、長文コンテキストを干し草に例えているわけです。
そしてSummHayは長文コンテキストに対するLLMやRAGシステムの出力性能の評価を目的としたタスクです。LLMにHaystacksの要約を作成させ、LLMがその要約を適切に引用できているかを評価します。
SummHayを用いて10種類のLLM、50種類のRAGシステムに対して調査を行ったところ、結果として以下のことがわかりました。
長文から正しく質問に回答できる情報を探し出すタスクにおいては、まだまだ人間の方が強いということが分かりました。
このあたりが実務でRAGを活用したいけれどもまだまだ期待するレベルに達していないという感触を生んでいる原因なのかもしれませんね。
出典:https://arxiv.org/pdf/2407.01370
機械学習モデルの精度を上げるために、強化学習といって繰り返しモデルに正解を学ばせてアップデートしていく手法が存在します。
中でもLLMの場合は既存のモデルを人間の価値基準をAIに反映させるかたちで学習させるRLHF(Reinforcement Learning from Human Feedback、人間からのフィードバックを用いた強化学習)という手法を用い、モデルの精度が改善されていくようなプロセスを取ることが多いです。
【関連記事】ざっくりわかるRLHF(人間からのフィードバックを用いた強化学習)
ところが近年、LLMの出力性能が上がるにつれ、分かりやすいミスが減り人間が誤りに気付きにくくなってきました。こうなると、いくらモデルを改善したくても誰も誤りに気づけず、RLHFを用いた改善プロセスを回すことができません。
そこでOpenAI社が作ったのが、GPT-4のプログラミングミスをLLMに指摘させるというものです。(※指摘のみで、自動修正などは行わない)
CriticGPTと名付けられたこのモデルは、人間よりも多くのバグを発見し、その回答は全体的に高評価を得たそうです。
ではもう人間によるフィードバックはやめて全てこのCriticGPTに任せてしまおう!と思ってしまいそうですが、現時点ではまだいくつか越えなければならない課題があります。
今は課題が大きいですが、今後対象範囲の拡大やモデルのより効果的なチューニング方法の確立などを通じてうまくスケールすれば、今後の生成AIの学習方法を大きく変えていくのではないでしょうか。
人間の能力不足によってモデルの改善プロセスが滞った結果生まれたのがこちらの手法だと考えると、所謂2045年問題(技術的特異点と呼ばれる、AIが人間の知能を超える転換点が2045年であるという予測)が少し現実味を帯びてきたように思います。
【関連記事】2045年問題とは?シンギュラリティの意味や仕事への影響を解説
出典:https://openai.com/index/finding-gpt4s-mistakes-with-gpt-4/
LLMの学習や訓練には莫大な量の多様かつ良質なデータが必要ですが、2026年にはインターネット上から良質なデータが枯渇するという「2026年問題」が指摘されています。※1
この問題への対処法の1つが「合成データ (Synthetic Data) 」です。
※1【参考】https://arxiv.org/pdf/2211.04325
合成データとは、現実世界のデータの特性やパターンを模倣しアルゴリズムを用いて人工的に生成されたデータです。合成データを用いることで、大量かつバラエティに富んだデータを簡単に生成できます。
とはいえ、合成データの「多様性」には実は限界があるそうです。今回ご紹介する論文では、この多様性の限界を突破すべく、10億人ものペルソナデータを使って合成データを作る「Persona Hub」を提唱しています。簡単に概要をご説明します。

従来の合成データ生成方法は大きく2種類あり、ひとつがインスタンス駆動アプローチ(Instance-driven Approach)、もう一つがキーポイント駆動アプローチ(Key-point-driven Approach)です。前者は実データに似たバリエーションを多数生成する手法、後者は実データが持つ要素を網羅的に出して、新たな組み合わせを作る手法です。前者はバリエーションが実データの偏りに依存すること、後者は全ての要素を網羅的に組み合わせるのが現実的でないことがそれぞれデメリットであり、合成データの多様性には課題が残ります。
今回提唱されたPersona Hubは、Web上のテキストデータから多様なペルソナ(特定の視点や経験、興味、専門知識を持つ架空の人格)を自動生成し、または生成されたペルソナからさらに新たなペルソナを生成し、これらをデータ生成のプロンプトに組み込むことで多様な視点からデータを生成するというものです。
例えばテキストデータをもとに「27歳の車好きの看護師」のようなペルソナを生成したとして、そこからさらにその患者や同僚、趣味仲間等のペルソナを導き出します。
このペルソナ1人1人が関心を持つテーマや分野、視点、経験に基づいて多様なユーザーをシミュレートし、大量のシミュレートされたユーザー・LLM間の会話を生成することができます。
例えば上記の看護師の例なら、傷病に関する論理的推論や車に関する数学的問題などを出題させることができます。
また、Persona Hubを用いて、例えば新製品の販売に様々なペルソナがどのような反応をするか?といったシミュレートも可能ですし、ゲームのNPCやツールの開発などにも利用できます。

ここでひとつ重大な注意点として、Persona Hubは短期間で簡単に10億規模の多様な合成データ作成を可能にする手法です。このデータがLLMのクエリ入力として大量に使用されてしまうと、LLMの知識や能力が損なわれてしまうリスクがあります。
というのも、通常我々ユーザーはLLMの能力のほんの一部しか引き出すことができませんが、10億ものペルソナが同時にLLMに別角度からアクセスできるということはPersona HubがLLMの学習データのほぼ全量にアクセスしうるということになります。全量にアクセスできてしまえば当然その学習データをコピーして盗むことができてしまいます。
また、合成データの多用自体にも懸念点が存在します。例えば合成データが汚染されていたりセキュリティが甘かったりするとモデルに悪影響を与えます。例え汚染されていないデータを使ったとしても、何世代にもわたって合成データを使って学習を続けるとデータ汚染によりモデルが崩壊するという報告もありました。※2
※2【参考】https://arxiv.org/pdf/2305.17493
Persona Hubは素晴らしい成果を生むことが期待される反面、誤用を避けて倫理的かつ責任ある使用を徹底する必要があります。
余談ですが、このあたりのAI倫理については日本ではさほど議論されていない一方、グローバルでは非常に重大なトピックであり、製品設計ひとつとってもAI倫理の論点は避けて通れません。生成AI関連の業務に携わる方皆が意識しておく必要があります。
出典:
https://arxiv.org/pdf/2406.20094
https://github.com/tencent-ailab/persona-hub
最後まで読んでいただきありがとうございます。
今回は、LLMが長文を理解できているかを評価するベンチマークSummary of a Haystack、LLMのプログラミングミスを指摘するLLM-CriticGPT、10億人のペルソナデータで作る合成データの3つのトピックをご紹介しました。
ブレインパッドは、LLM/Generative AIに関する研究プロジェクトの活動を通じて、企業のDXパートナーとして新たな技術の検証を進め企業のDXの推進を支援してまいります。
次回の連載でも最新情報を紹介いたします。お楽しみに!
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













