



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

みなさんこんにちは。アナリティクスコンサルティングユニットの崎山です。
2022年にChatGPTが登場して以来、LLM(Large Language Models、大規模言語モデル)、およびGenerative AI(生成AI)に関する技術革新が日々進み、それを取り巻く社会情勢もめまぐるしく変化しています。
これらの技術の社会実装に向けた取り組みや企業への支援を強化するため、ブレインパッドでもLLM/生成AIに関する技術調査プロジェクトが進行しており、最新トレンドの継続的なキャッチアップと情報共有を実施しています。
本連載では、毎週の勉強会で出てくるトピックのうち個人的に面白いなと思った事例・技術・ニュースをピックアップしてご紹介していきます。
※本記事は2024/7/19時点の情報をもとに記載しています
【関連記事】
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

7月18日、OpenAI社からGPT-4o mini が発表されました。こちらはコスト効率の良い小型モデルで、以下のような特徴があります。
*出典:https://openai.com/api/pricing/
GPT-4o mini は1Mトークンあたり入力が0.150$、出力が0.600$と非常に安価です。これは同社のLLMであるGPT-3.5の約1/3の価格で利用できるということです。(GPT-3.5は1Mトークンあたり入力が0.50$、出力が1.5$)
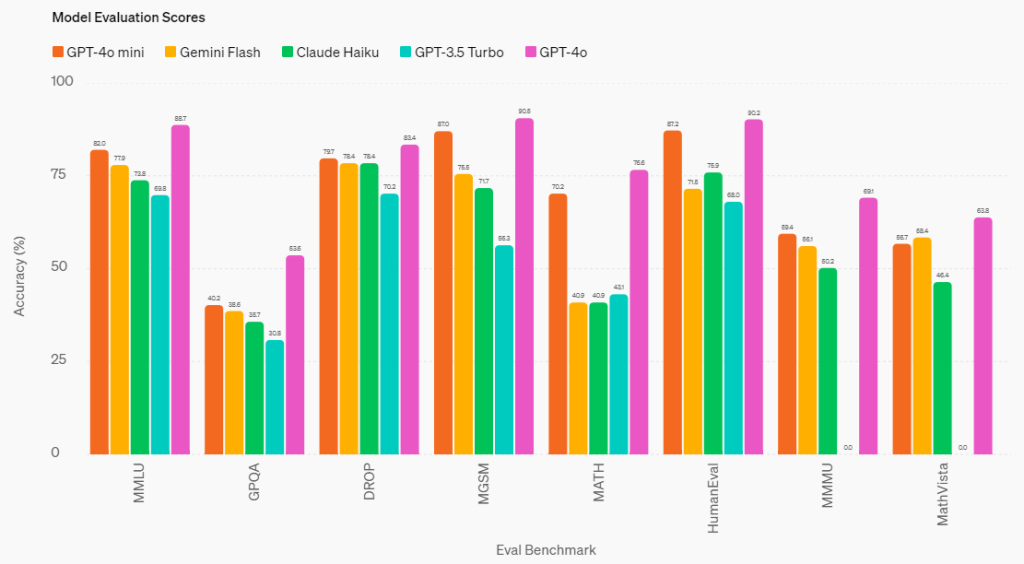
また、図の一番左にあるMMLUというベンチマークが近年モデルの比較によく使われるのですが、GPT-4o mini のパフォーマンスは他のクローズドな軽量モデル(Gemini 1.5 Flash, Claude 3 Haiku)よりも高く、MMLUで82%というスコアを叩き出しています。記事内では精度がGPT-4に並ぶ旨記載されていました。
これらの情報から、とにかくコストパフォーマンスに優れたバランスの良いモデルだということがわかります。
一定の精度を保ちながら安価に利用できるモデルということで、そこまで高度な推論や複雑なタスクが必要でない利用場面ではどんどん GPT-4o mini のような軽量モデルが活用されていくのではないでしょうか。
GPTだけでなく他社モデルの最新動向にも注目したいですね。
出典:https://openai.com/index/gpt-4o-mini-advancing-cost-efficient-intelligence/
みなさんはGoogleのスプレッドシートやMicrosoft Excelを使ったことはありますか?アカウントさえあれば誰でも無料で利用でき、データの共有も簡単にできるということで、おそらく世界中で使われているツールの1つなのではないかと思います。
非常に便利なためデータ管理に広く使用されているようですが、一方で自由度が高いがゆえにレイアウトや書式の理解が従来のLLMにとっては困難だったそうです。
今回ご紹介する論文では、スプレッドシートデータを効率的に処理し、LLMの能力を最大限に引き出すための革新的なフレームワーク SpreadsheetLLM と、その中核になるエンコーディング手法 SheetCompressor について提案しています。以下概要です。
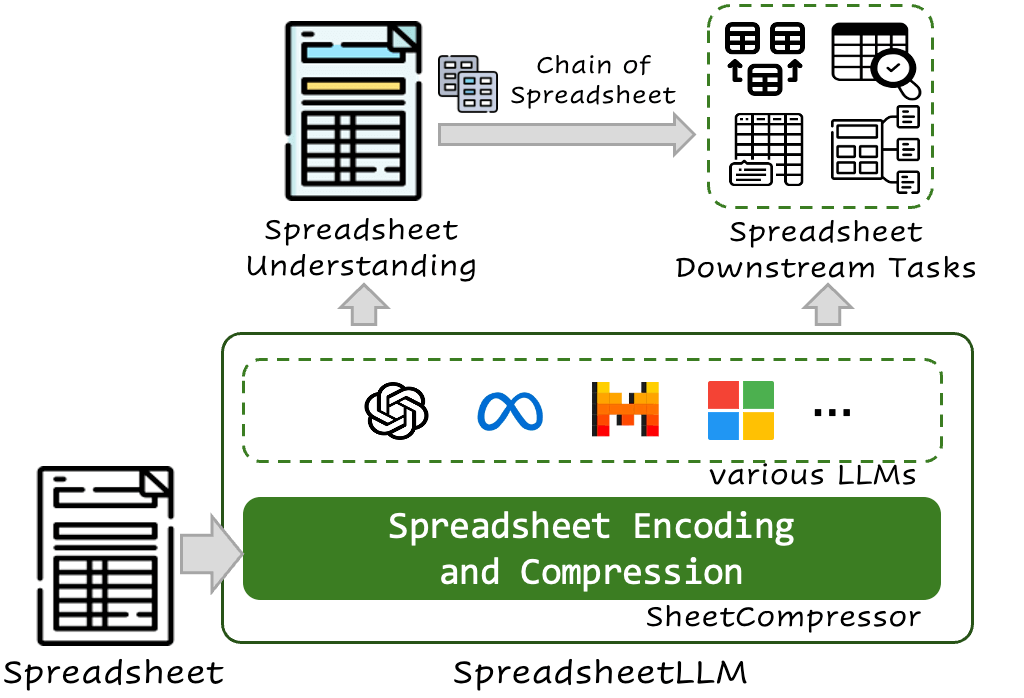
スプレッドシートをLLMに読み込ませる取り組みは今までにも行われており、中でも最初に出てきたのがシリアル化手法(データ構造やオブジェクトを一連のバイト列(テキスト形式が一般的)に変換するプロセス)です。
こちらはセルのアドレスや値、形式をデータに含めるものでしたが、LLMが扱えるトークン数※の制約によって実用性に欠けることが課題でした。
※トークン数:テキストデータに対してモデルが認識する最小限度の言葉の塊のことを指します。例えば”volleyball”という単語は”vol””ley””ball”の3トークンに分けられます。
これに対処するために開発されたのが SheetCompressor というエンコーディングフレームワークです。

こちらは表計算データをLLMが処理しやすいよう圧縮する手法で、以下のような特徴があります。
SheetCompressor を使うことにより、トークン数を25倍にまで圧縮、さらに表検出タスクやQAタスクにおいて従来のシリアル化手法のスコアを12.3%上回りました。
SpreadsheetLLM がさまざまなスプレッドシートタスクで効果的であることがわかります。
出典:https://arxiv.org/abs/2407.09025
Chatbot Arena というプラットフォームをご存じでしょうか。
世の中に多数登場する生成AIを用いたチャットボットの性能を簡単に比較できるように用意されたプラットフォームです。誰でもアクセスできるのでご興味があればぜひ覗いてみてください。
【参考】Chatbot Arena
こちらはLLMの評価ベンチマークであり、評価を行うのはユーザー自身です。というのも、ユーザーはランダムに選択された2つのモデルに対してプロンプトを入力し、どのLLMが回答しているか明かされない状態で、どちらが優れているかを選択するのです。
その結果をもとにモデル同士を戦わせて評価するので、まさに“競技場”です。
Chatbot Arena ではユーザー(=人間)にとってより好ましいモデルが上位ランクに来るため、「人間に好まれる」というなかなか数値化しづらい評価指標でモデルを評価できるのが魅力的なベンチマークであり、この指標を取り込んだモデルの精度が良くなりそうなのはなんとなく予想がつくかと思います。
ただし逆に言えば、大量のユーザーの投票によってこの指標は成り立っており、当然評価には多くの人手と時間がかかっています。このため、意図的にモデル学習に活用させるためには向かない指標でもありました。
今回ご紹介する論文はMicrosoft社による論文で、Chatbot Arena をシミュレートしてオフラインでのモデル学習に組み込む Arena Learning という手法を紹介するものです。

これの何がすごいかというと、「LLMの回答に対する人間の嗜好」を Chatbot Arena から学習し、それをモデル学習に生かせることです。
Arena Learning は「人間が評価するならきっとこちらを好むだろう」と判断するAIシミュレーション Wizard Arena を用い、そこでのシミュレーション結果をLLMの事後学習に使用することで Chatbot Arena と同等のフィードバックをモデル学習に活用できるようにしました。
Arena Learning を用いて学習させたモデル WizardLM-β は、大幅なパフォーマンス向上がみられたそうです。
人間の嗜好をモデルに反映させることで強化学習を行うRLHFという手法がありますが、人間の嗜好をモデル自身が予想できるようになれば飛躍的にモデルの学習が進むと考えられます。今後の発展に期待です。
【関連記事】ざっくりわかるRLHF(人間からのフィードバックを用いた強化学習)
出典:https://arxiv.org/pdf/2407.10627
AIが事実に基づかない情報を生成する現象のことを「ハルシネーション」といいます。このハルシネーションという問題を軽減する方法の1つとして、RAGという技術が使われ始めています。RAGとは、外部データから関連情報を検索・取得し、その検索結果をもとに回答を生成する技術です。
【関連記事】プロンプトエンジニアリング手法 外部データ接続・RAG編
RAGの検索対象は任意に設定することができるため、RAGを用いることで最新の情報や企業の内部ドキュメントなどを反映した回答生成が可能になります。
ただし、ただのRAGでは厳密にはハルシネーションの軽減にはつながらないというのもわかってきており、様々な研究でRAGのデメリットを補完しLLMの精度を上げる取り組みが行われています。
今回ご紹介する論文では、モデルによる出力までの過程に評価モデルによる判断を挟むことで回答精度を向上させることを試みた Speculative RAG について提案しています。これについて、いくつかの種類のRAGと比較しながら簡単にご紹介します。
RAGの強みは検索に基づいた生成が行えることですが、この作用がマイナスに働くことがあります。従来のRAGはあらゆる入力に対して検索を使って答えを出そうとするという挙動が確認されています。
例えば検索の全く必要ない「おはよう」のような入力に対しても検索で答えを出そうとするのです。
これにより、回答の精度が下がってしまうほか、検索結果をすべてプロンプトに取り込んでしまう分、遅くなり、さらに利用料もかさんでしまいます。
これを解決するために、いわゆる「Agentic RAG」つまりRAGに情報ソースを参照するかを自分で判断させるフレームワークがいくつか提案されています。特徴として、検索の実行の判断や検索した資料が正しいかを判定させる等、従来のRAGの弱点をカバーするような仕組みになっています。
今回のメインとなる Speculative RAG のほか、よく比較されるSelf-RAGとCRAGという2種類のRAGと比較しながら特徴を見ていきましょう。
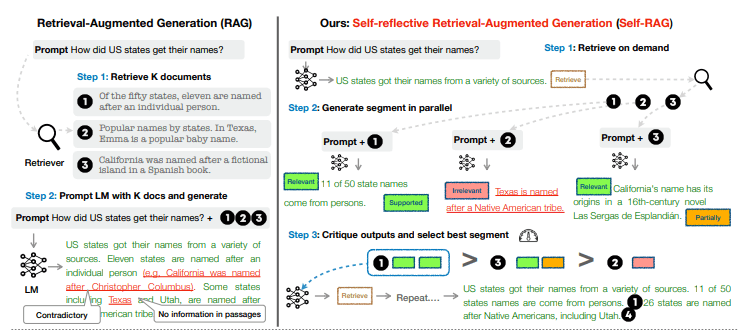
Self-RAGとは、検索した外部情報を「関連しているか」や「役立つか」を判断したうえで、検索した情報を生成に利用するかを決める仕組みです。
RAGは、
という2段階に分かれるのですが、1.のあとに判断のフェーズを挟むのがSelf-RAGです。
これにより、無理に検索した結果を使って生成を行うということがなくなり、精度低下を防ぐことができています。
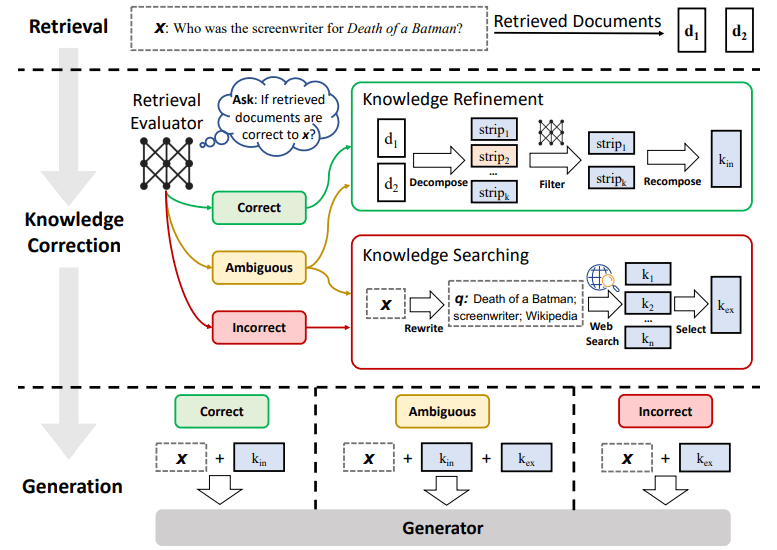
CRAG(Corrective RAG)はSelf-RAGを発展させたもので、外部情報を利用するかどうかが曖昧なときにWEB検索などの外部ソースを参照できるようにしたものです。
検索で誤ったデータを取得した際に修正したり、完全に誤っている場合はWeb検索に切替えたりと、Web検索を組み合わせた 検索を行います。
これにより、RAGにおいて誤った検索が行われると生成がうまく行かないという問題を解決することができます。
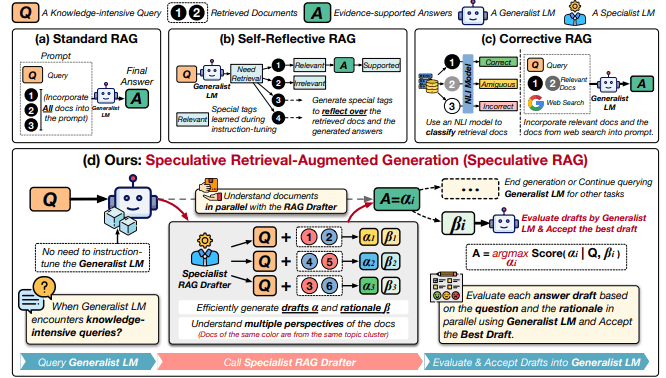
Speculative RAG は小さいRAGのそれぞれに回答ドラフトを生成させ、その結果を評価用LLMが評価し、最も良いものをユーザーの入力に対する出力結果として出すような仕組みのRAGです。
という2段階にタスクを分解することで、高品質な応答を迅速に生成できるのが強みです。
Speculative RAG は従来のRAGシステムと比較して、最大12.97%の精度向上と51%のレイテンシ削減を達成しました。
ただし、Speculative RAG の実現には小さいモデルのそれぞれをトレーニングする必要があります。トレーニングコストは高くないものの、構成としては複雑なものになることには留意が必要です。
RAGの弱点をカバーするために、RAG自身に判断を行わせる Agentic RAG の考え方に基づいていくつもの手法が提案されています。
文献を使うか否かの判断を行うSelf-RAGから、文献とWeb検索結果のどちらを使うかを選択し文献を修正できるCRAGと発展し、今回紹介した Speculative RAG は文献から作成された回答ドラフトをLLMが選ぶという仕組みにまで発展しました。
RAGの弱点を克服し、より精度を向上させるための今後の取り組みに期待ができます。
出典:https://arxiv.org/pdf/2407.08223
最後まで読んでいただきありがとうございます。
今回は、GPT-4o mini 登場、スプレッドシートの構造の読み取りに特化したフレームワーク SheetCompressor、人間がどのモデルの回答を好むかをモデルに学習させる手法 Arena Learning、RAGの進化と Speculative RAG の4つのトピックをご紹介しました。
ブレインパッドは、LLM/Generative AIに関する研究プロジェクトの活動を通じて、企業のDXパートナーとして新たな技術の検証を進め企業のDXの推進を支援してまいります。
次回の連載でも最新情報を紹介いたします。お楽しみに!
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説
















