



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

みなさんこんにちは。アナリティクスコンサルティングユニットの崎山です。
2022年にChatGPTが登場して以来、LLM(Large Language Models、大規模言語モデル)、およびGenerative AI(生成AI)に関する技術革新が日々進み、それを取り巻く社会情勢もめまぐるしく変化しています。
これらの技術の社会実装に向けた取り組みや企業への支援を強化するため、ブレインパッドでもLLM/生成AIに関する技術調査プロジェクトが進行しており、最新トレンドの継続的なキャッチアップと情報共有を実施しています。
本連載では、毎週の勉強会で出てくるトピックのうち個人的に面白いなと思った事例・技術・ニュースをピックアップしてご紹介していきます。
※本記事は2024/9/19時点の情報をもとに記載しています
【関連記事】
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

OpenAIが2024年9月12日、推論能力に長けた新たなAIモデル「OpenAI o1」および「OpenAI o1-mini」を発表しました。OpenAI o1の初期版であるo1-previewとo1-miniにはChatGPTの有料会員であればアクセスできるそうです。ぜひこの機会にお試しください。
【参考】OpenAI | https://chatgpt.com/
このモデルの特徴は、Chain of Thought※1プロセスを挟むことで推論制度を高めていることです。
※1:Chain of Thought(CoT、思考の連鎖)とは:複雑なタスクを複数のステップに分解し、逐次的に解かせる考え方や方法論のこと。
これにより推論能力が大幅に向上しており、OpenAIのリリースによると物理学や化学、生物学のベンチマークタスクで博士課程の学生と同等のパフォーマンスを発揮し、数学やコーディングでも優れた能力を見せているそうです。
また、同リリースでは、ChatGPT上でモデルをユーザーが選ばずとも入力プロンプトから自動で適切なモデルを判断できるように取り組んでいるとの記載もあり、こちらの機能にも期待が持てます。
ChatGPT上で利用できる他、MicrosoftがGitHub CopilotにOpenAI o1-preview/o1-miniを順次導入する※2ことを発表しており、徐々に利用できるプラットフォームが増えていくことが予想されます。
※2:https://github.blog/news-insights/product-news/openai-o1-in-github-copilot/
ただしこの利便性の反面、OpenAI o1の思考過程は公表されていません。
上述のように、OpenAI o1はCoTを用いて推論精度を向上させていますが、その思考の具体的な過程は非公開です。ユーザーが思考の過程を尋ねても、生の推論過程を教えてくれるのではなく、第二のAIモデルによって作成されたフィルタリングされた解釈を提示するのだそうです。
利用に伴う解釈可能性や透明性の担保のために、あるいは単なる好奇心で、ハッカーやレッドチームがあの手この手でo1の思考の過程を明らかにしようとしていますが、彼らにはOpenAIからの警告が表示されたと記事では述べられています。
リスクを正しく理解し、上手く付き合っていくことが肝要そうです。 OpenAIに限らず、市場全体の動向に今後も注目したいですね。
出典:
https://openai.com/index/introducing-openai-o1-preview
https://arstechnica.com/information-technology/2024/09/openai-threatens-bans-for-probing-new-ai-models-reasoning-process
AIが事実に基づかない情報を生成する現象のことを「ハルシネーション」といいます。
【関連記事】生成AIをビジネス活用する上で押さえるべき8つの評価観点
一部の論文※3ではハルシネーションがLLMの数学的な論理構造に起因するため、根絶は不可能であると論じられています。
※3:https://arxiv.org/abs/2409.05746 など
とはいえ業務利用するにあたって、回答の正確性が求められるようなユースケースではLLMのハルシネーションはリスクになりますよね。
うまくハルシネーションと付き合うためには出力結果の評価が不可欠なのですが、理想を言えばLLMが出力する前に自分で誤りを見つけて直してくれると評価側も楽ではないでしょうか。
実はいくつかの研究※4において、LLMには自己検証の能力があることが示されています。
※4:https://arxiv.org/pdf/2303.17651 など
みなさんも試していただきたいのですが、LLMの生成内容に対して例えば「どこが間違っていると思いますか?」などと尋ねると、LLMは自分で誤りを見つけることができます。
このことからLLMはハルシネーションに気づく能力があると言えますが、文章を生成している最中にその誤りを訂正することはありません。ではなぜ誤りを生成中に正さないのでしょうか?
今回ご紹介する論文では、LLMは自分でミスを修正するという行為を学習していないのではないか?という仮説に基づき、LLMが文章の生成中にハルシネーションを自己修正するよう事前に訓練しておくことを試みました。以下で概要をご説明します。
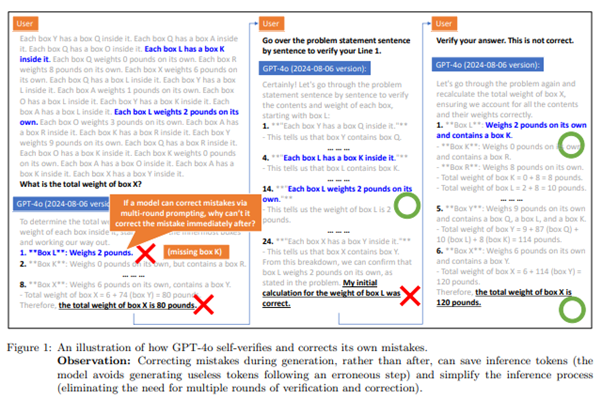
論文では、小学校レベルの算数の問題をミスを訂正しつつ解く合成データを生成し、こちらのデータを用いてLLMを事前学習しました。
ミスのない算数のデータのみで事前学習を行ったモデルと比較したところ、ミスを訂正するよう事前学習されたモデルは精度が良いことがわかりました。
これにより、LLMはミスを見つけることはできても、ミスを自己修正することは事前に学習していないと実行できない可能性が高いとわかりました。
ワークフローにLLMを組み込む際は間違いを訂正させるようなプロンプトを組み込むなどの工夫を行うと、手間なくモデルの挙動を変えることができそうです。
出典: https://www.arxiv.org/pdf/2408.16293
LLM(特に対話型の生成AI)を活用する際に、「入力時にガイドとして思考の過程を与える」「思考の過程を考えるよう指示する」というプロンプト入力のテクニックを聞いたことはないでしょうか。
このように複雑なタスクを複数のステップに分解し、逐次的に解かせる考え方をCoT(Chain-of-Thought)といい、特に数学的な問題や論理的な問題を解く際に望む解を得やすくなります。
例えば例題と答えのセットを与えることや、過程を数式で表現すること、もっと簡単な例だと「ステップバイステップで考えてみましょう」等と指示するだけでも回答精度が上がることがあります。ぜひ試してみてください。
便利なCoTですが、実は従来のCoTは推論の一貫性や精度に課題があるそうです。
今回ご紹介する論文ではこのCoTを発展させたStrategic Chain-of-Thought(戦略的CoT, SCoT)により、従来のCoTよりも推論精度を向上させることを試みています。概要をご説明します。
おさらいですが、CoTとは複雑なタスクを複数のステップに分解し、逐次的に推論させる手法です。
タスクを小さく分解して精度を向上させるという方向性が効果的であるということ自体は複数の論文でも言われています。
ただし、CoTは段階を踏んで推論を行う以上、前のステップに誤りがあれば以降のステップにも当然影響が発生します。各段階の精度が必ずしも一定でないため、最終的な結果に誤りが発生する可能性が残り、これが先述のCoTの課題です。
従来もCoTの課題を解決するためにいくつかの手法が編み出されています。いずれも有用である一方大きなリソースを必要とします。金銭的なコストだけでなく人間の専門家が必要になるケースもあり、実用化にはまだ課題が残っています。例えば以下のような手法が挙げられていました。
これらの課題を解決するために、本論文で提案されているのがSCoT(Strategic Chain-of-Thought)です。
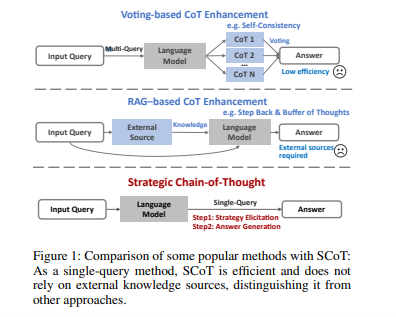
SCoTは、以下の2段階のステップで推論を行うのが特徴です。
1ではモデルが問題を分析した上で、複数の問題解決戦略の中から最も効果的なものを指導的な戦略的知識として獲得します。なお、ここでいう戦略的知識というのは、同様のタイプの問題全般に適用できる汎用的な解決方法のことです。問題を解くための汎用的な知識体系と考えると分かりやすいかもしれません。
2ではこの獲得した戦略的知識をもとに推論を行います。
つまりSCoTは、戦略を立ててから実際の推論と回答生成に移らせることで精度を高めようとするアプローチです。
SCoTを用いて様々な推論タスクを解かせたところ、ほとんどのタスクで従来のCoTアプローチを上回る性能を示しました。特にGSM8k(算数の問題を8000個集めたデータセット)ではLlama3-8bでAccuracy+21.05%、Tracking Objects(連続する画像データを入力とし、動画像中で変化・移動する物体を追跡するテスト)で+24.13%という顕著な精度向上がみられています。
この結果より、ScoTがLLMの推論精度向上に有用であることがわかります。
最後に、アプローチが類似している研究として、Plan-and-Solve (PS) Promptingという手法をご紹介します。
【参考】https://arxiv.org/abs/2305.04091
簡単にご説明すると、こちらはタスクを小さく分割する計画を立ててから実行し答えを導き出す手法のことで、以下の2段階のステップで推論を行うものです。
SCOTとPlan-and-Solveはどちらも計画を立ててから実行するという点では共通しています。トピック1で出てきたOpenAI o1もそうですが、質問に対して即座に沢山の回答を出すのではなく、順序だてて考えて答えを出すと精度が上がるというのはかなり人間の思考過程に似ていますね。
出典:https://arxiv.org/pdf/2409.03271v1
AIが自律的に思考し動けるようになってきたことに伴い、生成AIをキャラクターの行動や消費者行動などのシミュレーションに使うことができるようになってきました。
【関連記事】自律型AIエージェントのご紹介
Alteraでは、Minecraft上に1000を超える自律型AI Agentを配置し、数日間にわたって政治や経済、社会規範等の社会生活シミュレーションを行わせるProject Sidというプロジェクトを実施しました。以下概要です。

Project Sidにおいて、Agentたちは協力してアイテムを収集し、宝石を通貨として売買します。自律的に市場が確立され、中では宗教的な儀式や民主主義の形成など、Agent同士で高度な社会行動を行えることが観察できたそうです。
(最も多い取引は村人に賄賂を渡して資源を回収させた司祭だったのだとか…)
技術的な話で言うと、Agent同士が関係性や以前の会話記録等に基づいたリアルな会話や会話に基づく行動を行えるよう設計し、また目標と社会的な影響や動機にも注意を払わせることで、柔軟で動的な協力タスクをもこなさせることができました。
逆に、個々のAgentが小さな間違いを犯すと下流の社会的階層に影響を及ぼすことも見えてきたそうです。例えばタスクの伝達にミスがあると、タスクを請け負うグループのタスク成功率に影響を及ぼすことが挙げられていました。
これらの内容から、AI Agentは自己組織化して複雑な社会を形成できることが示されました。現実の人間社会のシミュレートにどんどん使っていけそうです。
さらに技術が発展すれば、オンライン空間においてAgentと人間がひとつの社会で生活する未来も実はそう遠くないのかもしれませんね。
出典: https://digitalhumanity.substack.com/p/project-sid
最後まで読んでいただきありがとうございます。
今回は①OpenAIが 最新モデル「OpenAI o1」および「OpenAI o1-mini」を発表 ②LLMに自身のハルシネーションを修正させる③戦略的CoTで推論の精度を上げる ④Minecraft上でAI Agentによる社会生活シミュレーションを行うProject Sidの4つのトピックをご紹介しました。
ブレインパッドは、LLM/Generative AIに関する研究プロジェクトの活動を通じて、企業のDXパートナーとして新たな技術の検証を進め企業のDXの推進を支援してまいります。
次回の連載でも最新情報を紹介いたします。お楽しみに!
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説















