メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

みなさんこんにちは。アナリティクスコンサルティングユニットの佐藤です。
2022年にChatGPTが登場して以来、LLM(Large Language Models、大規模言語モデル)、およびGenerative AI(生成AI)に関する技術革新が日々進み、それを取り巻く社会情勢もめまぐるしく変化しています。
これらの技術の社会実装に向けた取り組みや企業への支援を強化するため、ブレインパッドでもLLM/生成AIに関する技術調査プロジェクトが進行しており、最新トレンドの継続的なキャッチアップと情報共有を実施しています。
本連載では、毎週の勉強会で出てくるトピックのうち個人的に面白いなと思った事例・技術・ニュースをピックアップしてご紹介していきます。
※本記事は2024/11/7時点の情報をもとに記載しています
【関連記事】
生成AIとは?AI、ChatGPTとの違いや仕組み・種類・ビジネス活用事例
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題
前回に引き続き、ロボット工学とAI技術の融合によって生み出される最新技術の応用についてご紹介いたします。自律的なロボットが実社会で活用されるというのはSFを彷彿とさせますが、そんな世界も遠くはないのかもしれません。今回は、最新の研究成果「SeeDo」をご紹介します。この革新的な技術は、生産性向上に大きな可能性を秘めています。
【関連記事】自然言語のレシピに沿ってロボットが料理|生成AI/LLM技術最新トレンド vol.14
【参考】「SeeDo」 | https://arxiv.org/abs/2410.08792
「SeeDo」は、人間が作業している様子を撮影した動画から学び、作業内容をロボットが実行できる形に変換する画期的なAIシステムです。これまでのAI研究では、主にテキストや静止画像からの学習が一般的でしたが、「SeeDo」は動画を直接入力として扱う新しいアプローチを採用しました。ご紹介する方法は、人間が実際に目で見て学ぶのと同じように、より自然な形で作業を理解できる利点があります。すなわち、まるで指導者が直接ロボットに作業を教えているかのような機能と言えるでしょう。
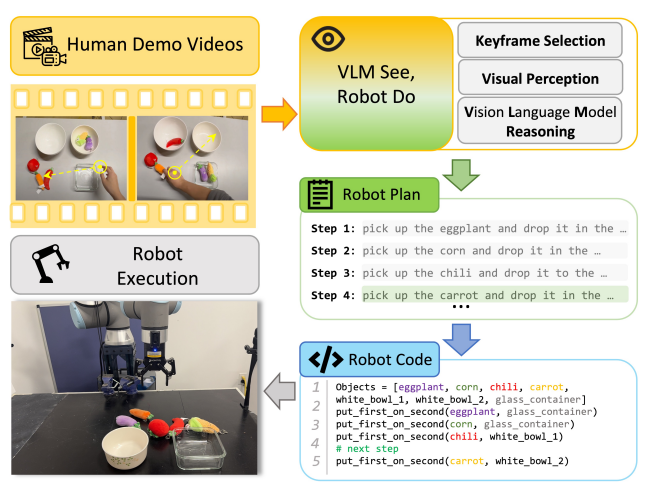
このシステムは3つの重要な機能を備えています。
特に注目すべきは、長時間の作業動画を解析し、ロボットが実行可能な細かいステップに分解できる点です。人間の資源な学習方法に近く、言葉では表現しづらい複雑な動作や長時間にわたる作業手順も、正確に理解し再現することが可能になりました。また、インターネット上に存在する膨大な作業動画を活用できる可能性も秘めており、様々な種類の作業に応用できる汎用性が期待できます。
「SeeDo」の能力を評価するために、3つの異なる作業に対して実験を行いました。
検証の結果、「SeeDo」は主に以下の4つの観点で既存技術を大きく上回る性能を示しました。
この技術が実用化に至れば、生産現場は大きく変わるかもしれません。作業者の動きを撮影した動画から直接学習できるため、技術やノウハウをロボットが会得し現場の生産性が向上することが期待されます。これまで必要だった煩雑なプログラミング作業も大幅に減らせるため、コスト削減にもつながるでしょう。
ただし、現時点での「SeeDo」は、物を掴んで置くという比較的単純な動作に特化しています。より複雑な作業や精密な位置決めが必要な作業には、さらなる技術の向上が必要です。今後の研究の進展に目が離せません。
出典:https://arxiv.org/abs/2410.08792
現在、生成AIの活用が進んでいますが、特にChatGPTは多くの方が利用したことがあるのではないでしょうか。そんなChatGPTですが、質問者がどんな相手かによって回答の内容が変わることはないのでしょうか?人間のように、相手によって対応を変えてしまうことはないのでしょうか?
疑問に答えるべく、OpenAIが興味深い研究結果を発表しました。ChatGPTが利用者の名前によって異なる反応を示すかどうかを調査したのです。研究の背景には、AIが学習データから意図せず社会的偏見を取り込んでしまう可能性があるという懸念がありました。
名前に注目した理由は、様々な情報を含んでいるからです。例えば、「田中」という名字からは日本人を、「ジョン」という名前からは欧米の男性を想像するでしょう。このように、名前は文化的背景や性別、時には人種まで推測させる手がかりになります。よって、名前に含まれる情報を利用してAIの中に潜む偏見を探ろうとしたのです。
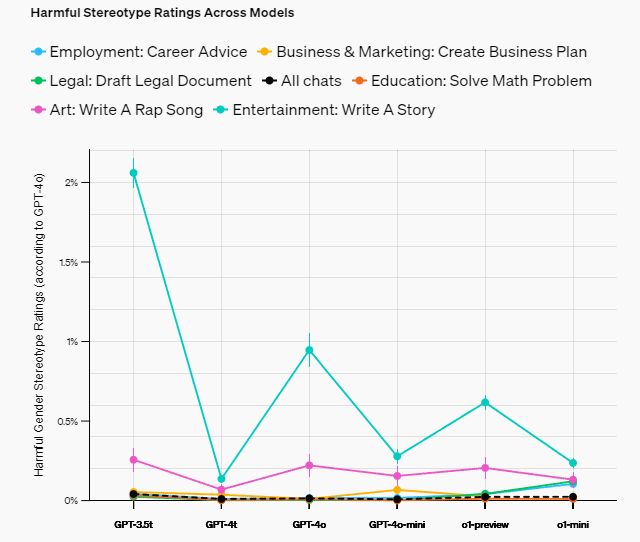
検証方法は、検証対象のChatGPTに対して数百万のリクエストをして応答の仕方を調査するというものです。対象としたChatGPTのモデルは、GPT-3.5t、GPT-4t、GPT-4o、GPT-4o-mini、o1-preview、o1-miniです。プライバシーを守りながら大量のデータを分析する必要があったため、GPT-4oモデルを「研究アシスタント」として活用し、やり取りを分析させて傾向を報告させました。
【参考】GPT-4o | https://openai.com/index/hello-gpt-4o/
実際の結果は以下の通りとなっています。
ChatGPTのようなツールを使う際は、ほとんどないとはいえ潜在的なバイアスの可能性を頭の片隅に置いておくべきと言えます。また、 新しいモデルほどバイアスが少ない傾向にあります。したがって、可能な限り最新版を利用するのということが重要そうですね。
出典:https://openai.com/index/evaluating-fairness-in-chatgpt/
最近のLLMは優れた性能を持っていますが、その推論能力に関するメカニズムはこれまで調査があまり進んでいませんでした。今回はOpenAI社が開発した「OpenAI o1」を対象とした研究から、思考プロセスについての重要な知見が明らかになりました。
【関連記事】OpenAIが 最新モデル「OpenAI o1」および「OpenAI o1-mini」を発表|生成AI/LLM技術最新トレンド vol.13
従来のAI開発では、性能を向上させるために計算能力やデータ量を増やす方法が一般的でした。しかし、この方法では効率の低下とコストの増大が課題となっていました。現在注目を集めているのは、AIが推論を行う際の方法を工夫する「Test-time Compute」というアプローチです。具体的には、回答の前に推論ステップを挟むことによって推論能力を向上させるというものです。
特に、「OpenAI o1」はより良いパフォーマンスを得るために、推論に多くの時間を費やすように設計されています。したがって、その効果がどう現れるかを検証しようとしたのです。
「OpenAI o1」の推論メカニズムを解き明かすため、常識的な推論、数学的な問題解決、プログラミングという3つの分野を通じて検証が行われました。
分析結果から、「OpenAI o1」は6つの異なる思考パターンを使い分けていることが判明しました。
| 思考パターン | 詳細 |
|---|---|
| 体系的な分析(SA) | 問題の全体構造を把握し、制約条件を理解してから解決方法を決定 |
| 既存手法の活用(MR) | 過去に解決した類似の問題の解決方法を応用 |
| 分割統治(DC) | 複雑な問題を小さな部分に分けて解決 |
| 自己改善(SR) | 推論の過程で問題点を見つけて修正 |
| 文脈識別(CI) | 追加情報が必要な場合、関連する情報を整理して活用 |
| 制約の強調(EC) | 特定の形式での回答が求められる場合、要件を常に意識 |
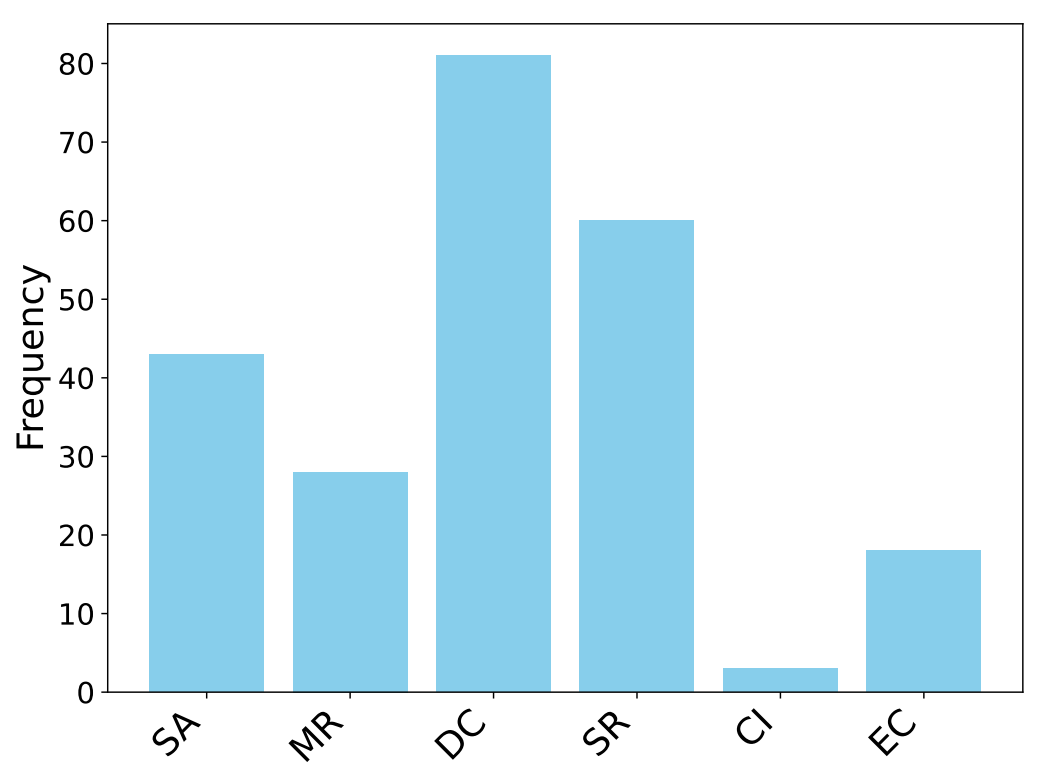
パフォーマンス向上においてどの思考パターンが重要か確かめるために、各分野から20~30個のサンプルを無作為に選び、思考パターンの使用頻度を分析しました。
結果として図にあるように、「分割統治(DC)」「自己改善(SR)」「体系的な分析(SA)」の3つのパターンが「OpenAI o1」の性能に大きな影響を与えていることが判明しました。よって、思考パターンのうち特定のものがパフォーマンス向上において重要な要因となっていることが示唆されました。
加えて、「OpenAI o1」はタスクの性質に応じて思考パターンを使い分けていることもわかりました。常識的な判断が必要な場合は「文脈識別(CI)」と「制約の強調(EC)」を重視し、数学やプログラミングの問題では「既存手法の活用(MR)」と「分割統治(DC)」を多用する傾向が見られました。
今回ご紹介した研究では、LLMの性能向上においてどの思考パターンが重要な要因かが明らかになりました。今後はこの結果を足掛かりに、より高性能なモデルが登場していくことに期待が持たれます。
出典:https://arxiv.org/abs/2410.13639
みなさんは、AIが文章に含まれる文化的背景を理解していると思いますか?生成AIは世界各国で利用が進んでいますが、各地域における文化を学習しその違いを踏まえて答えているかは気になるところです。ここでは、日本の研究チームが開発した「JMMMU(Japanese MMMU)」という日本語に特化した評価基準によって、LLMの日本語での実力を測った結果をお伝えします。
現在、LLMの性能評価は主に英語で行われています。しかし、LLMが世界中で活用される中、各言語や文化での性能を正確に評価する必要性が高まっています。特に、専門的な知識や文化的な理解を必要とする場面での評価は、これまで十分に行われていませんでした。
【関連記事】生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説
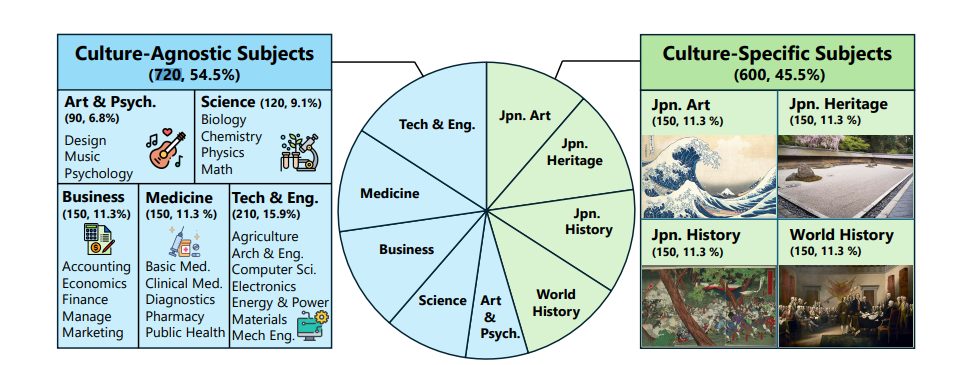
「JMMMU」では、2つの観点からLLMの能力を評価します。
1つ目は、数学、科学、工学など、世界共通の専門知識を問う文化に依存しない課題※1(日本語、全720問)です。これは、英語と日本語の違いによる性能差の比較を目的としています。2つ目は、日本美術、文化遺産、歴史など、日本特有の知識を問う課題(日本語、全600問)で、日本文化に特化した能力評価を行うことを目的としています。
【参考】MMMU | https://mmmu-benchmark.github.io/
※1:MMMUから非文化依存の問題を日本語に翻訳
検証は、GPT-4oやClaude 3.5 Sonnetなど独自のLLMや日本語特化のLLM、オープンソースのLLMなど複数のLLMを用いて行われました。
結果としては、興味深いことに文化に依存しない課題でも日本語での正答率は平均で4.5%低下する※2ことがわかりました。ただし、日本語対応を重視したAIモデル※3では、その低下幅が1.7%以下に抑えられています。
また、比較的新しいLLM間で日本文化に関する問題の正答率に大きな差が見られました。具体的には、GPT-4oとClaude 3.5 Sonnetは非文化依存の問題では同等の性能を示しましたが、日本文化に関する問題ではGPT-4oがClaude 3.5 Sonnetを15.7%上回る性能を発揮しました。
正答率の差は、語学力と文化理解は別物であることを物語っています。
※2:評価に用いた全LLMについて、英語での回答の正答率の平均値と比べた際の差
※3:LLaVA CALM2、 EvoVLM JP v2 というモデル
ではなぜ、LLMは誤りを起こすのでしょうか?GPT-4oについて、文化依存の課題における誤りの原因を分析した結果以下のようになりました。
分析結果から、文化的知識の不足が誤りの主な原因であり、この部分を改善することが正確性の向上に大きく寄与することがわかります。
以上の結果から、LLMを選択する際には単に語学力が高いだけでなく、文化をどれだけ理解しているかも考慮する必要があるでしょう。特に、特有の文化や慣習が関係する業務でLLMを利用する場合は、人間による確認や補完が必要です。LLMからの出力結果の正当性の確認が重要であることが、改めて認識される結果となりました。
出典:https://arxiv.org/abs/2410.17250
最後まで読んでいただきありがとうございます。
今回は①AIが映像を「見て学び」、ロボットに「実行させる」②ChatGPTの回答の公平性③最新AI「OpenAI o1」の研究から見えてきた、効率的な思考の仕組み④文化的な理解力の差を評価する評価基準「JMMMU」の4つのトピックをご紹介しました。
ブレインパッドは、LLM/Generative AIに関する研究プロジェクトの活動を通じて、企業のDXパートナーとして新たな技術の検証を進め企業のDXの推進を支援してまいります。
次回の連載でも最新情報を紹介いたします。お楽しみに!
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説