



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

みなさんこんにちは。アナリティクスコンサルティングユニットの崎山です。
2022年にChatGPTが登場して以来、LLM(LargeLanguageModels、大規模言語モデル)、およびGenerativeAI(生成AI)に関する技術革新が日々進み、それを取り巻く社会情勢もめまぐるしく変化しています。
これらの技術の社会実装に向けた取り組みや企業への支援を強化するため、ブレインパッドでもLLM/生成AIに関する技術調査プロジェクトが進行しており、最新トレンドの継続的なキャッチアップと情報共有を実施しています。
本連載では、毎週の勉強会で出てくるトピックのうち個人的に面白いなと思った事例・技術・ニュースをピックアップしてご紹介していきます。
※本記事は2024/5/23時点の情報をもとに記載しています
【関連記事】
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

プロンプト(生成AIの文脈では、ユーザーがAIと対話する際にユーザーが入力する指示や質問のこと)から、物体検出を行えるモデルGrounding DINOの新しいバージョンが発表されました。
Grounding DINOとはどんなモデルか?を簡単にご説明します。
そもそも画像解析の分野では、コンピュータに画像内のオブジェクトの意味を理解させることが難しいという課題がありました(これをシンボルグラウンディング問題といいます)。
例えば「レモン」という言葉を人間が見ると、果物のレモンの概念(例えば黄色い、酸っぱい、など)を簡単に想起できる一方、コンピュータは「レ」「モ」「ン」という文字列でしか認識できません。レモンという記号(今回は文字列)とレモンの概念が結びついていないからです。
この問題を解決する手段はこれまでも様々な手法が提案されていたのですが、先日新たにGrounding DINOというモデルが提案されました。こちらは、GLIP(Grounded Language-Image Pre-training)と呼ばれる画像とテキストの対応関係を学習する手法とDINOというモデルを組みあわせたモデルで、自然言語と画像の対応関係をとるのに長けています。
今回のアップデートでは、モデルのサイズとモデルの訓練用データセットの両方を大きくすることによって、画像や動画からより正確に、しかもリアルタイムでオブジェクトを理解し検出できるようになりました。さらに何を検知してほしいのかを自然言語で指示することができます。
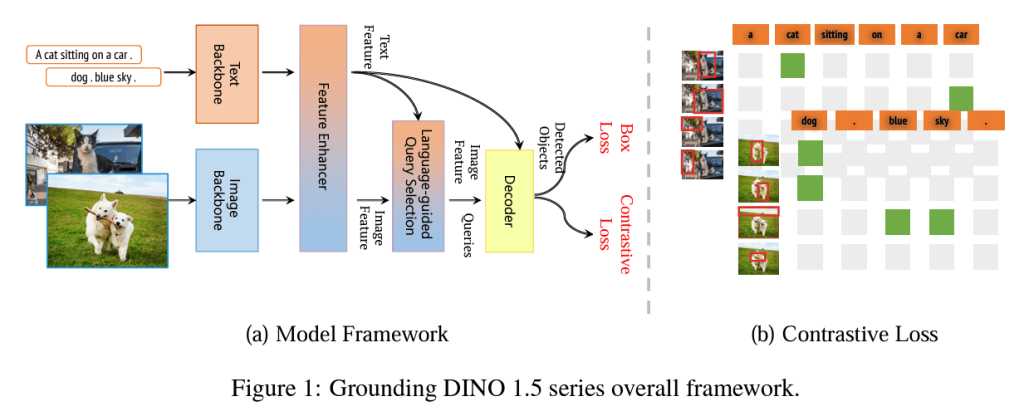
オブジェクトを検出するだけでなく、画像から長文でキャプションを付与できるようになったり、密集したオブジェクトの検知をより精度高くできるようになるなど、予測精度が向上したのがわかります。


例えば自動運転や防犯カメラの解析、医療、工場における異常検知などに応用されてきた「物体個々を認識する」検知のシステムが「全体として何が起こっているのか」を表現できるようになってきたため、複雑な状況を認識したり特殊な状況を検知したりすることに役立てる可能性が広がってきていると考えられます。
出典:
https://deepdataspace.com/blog/Grounding-DINO-1.5-Pro
https://arxiv.org/abs/2405.10300
AIが事実に基づかない情報を生成する現象のことを「ハルシネーション」といいます。このハルシネーションという問題を軽減する方法の1つとして、RAGという技術が使われ始めています。
【関連記事】プロンプトエンジニアリング手法 外部データ接続・RAG編
RAGの検索対象は任意に設定することができるため、RAGを用いることで最新の情報や企業の内部ドキュメントなどを反映した回答生成が可能になります。一方で、実はRAGの堅牢性に関する既存研究にはまだ十分に検討されつくしていない部分があることを指摘した論文が発表されています。簡単にご紹介します。
RAGは大きく2つの機能で構成されています。外部知識として用意した文献から必要な部分を検索する機能(リトリーバー)と、検索した文献と質問から回答を生成する機能(リーダー)です。
従来の研究ではこのそれぞれに対して焦点を当てた評価を行っていたものの、本来相互作用を持つはずのリトリーバーとリーダー両方に対する堅牢性の評価は行われてきませんでした。そして、実際のデータベース上で蔓延しているちょっとしたテキストエラー(タイプミス等)がRAGに引き起こす脅威についても見落としてきたのだそうです。
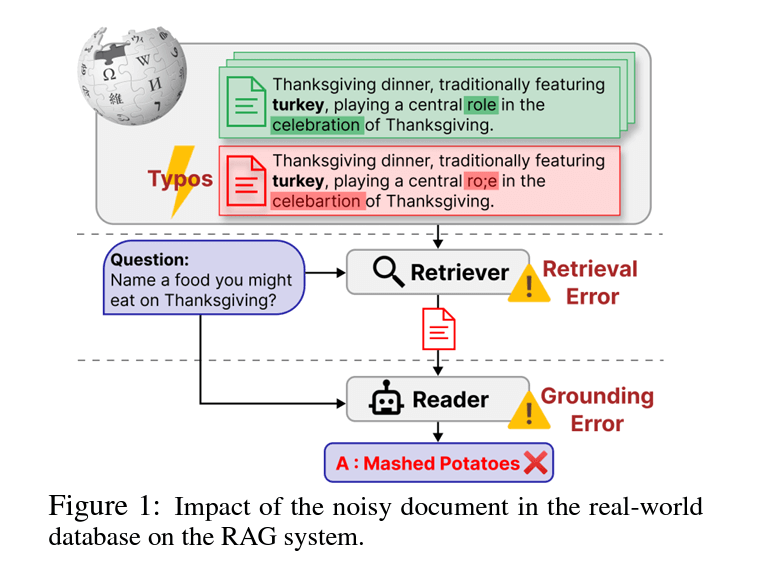
本論文では、GARAG(Genetic Attack on RAG)という新しい敵対的攻撃手法を使って、その攻撃がRAGにどのような影響を及ぼすのかを調査しました。
ここでいう敵対的攻撃とは、元のデータに人間にはわからないようなわずかなノイズを加えて、機械学習モデルの認識を混乱させる攻撃手法を指します。
GARAGは、元の文献に意図的にちょっとしたノイズ(タイプミスや不自然な句読点等)を混ぜ込むことで、現実世界のデータのノイズに近い形でシミュレートを行います。これにより、リトリーバーが正しい文献を検索することや、リーダーが適切に答えを見つけることを妨げることを期待しました。
調査の結果、GARAGがRAGシステムのパフォーマンスを著しく低下させることが分かりました。
現実世界のデータベースに存在する可能性のある些細なテキストエラーは、RAGシステムの全体的なパフォーマンスを著しく低下させる可能性があり、堅牢なRAGシステムの構築には、リトリーバーとリーダーの両方の堅牢性を考慮した対策が必要であるということがわかりました。
出典:https://arxiv.org/pdf/2404.13948
企業においてLLMを活用したい場合に、特定の目的を達成できるようにモデルをカスタマイズしたい…という要望をお持ちの方も多いのではないでしょうか。
生成AIをカスタマイズする際、本記事の2つ目のトピックにも出てきたRAGを用いるアプローチの他に、「ファインチューニング」という手法を用いてモデル自体を訓練し直すやり方があります。
【関連記事】OpenCALM-7Bにファインチューニングを実施してポジネガ分析に関して賢くなるかを確認してみた
大きなメリットを持つ反面導入ハードルや再学習のコストが高いのですが、近年はファインチューニング用のパッケージが随所で公開され、以前よりは導入ハードルが低くなってきました。
さて、「モデルが知らない新たな情報を付け加える」というカスタマイズを行いたい場合には、多くの場合RAGが用いられます。しかしファインチューニングを使うことはできないのでしょうか?
今回ご紹介する論文では、新しいデータセットから学べる内容とLLMが元々持っていた知識が矛盾していた場合、モデルの学習や生成の際にどのような挙動を起こすのかを調査しています。概要をご説明します。
今回の研究では、ファインチューニングに用いたデータセット内の新しい知識がファインチューニング後のLLMの性能にどのような影響を与えるかを調査するべく、筆者たちは以下のようなアプローチで実験を行いました。
※ 通常モデルの学習のためにはひとつのデータセットを何周も学習させる必要があります。
何周学習したか?という数を「エポック数」と呼び、たとえば「10エポック」ならひとつのデータセットを10周学習したことになります。
その結果、以下のような事実が明らかになりました。
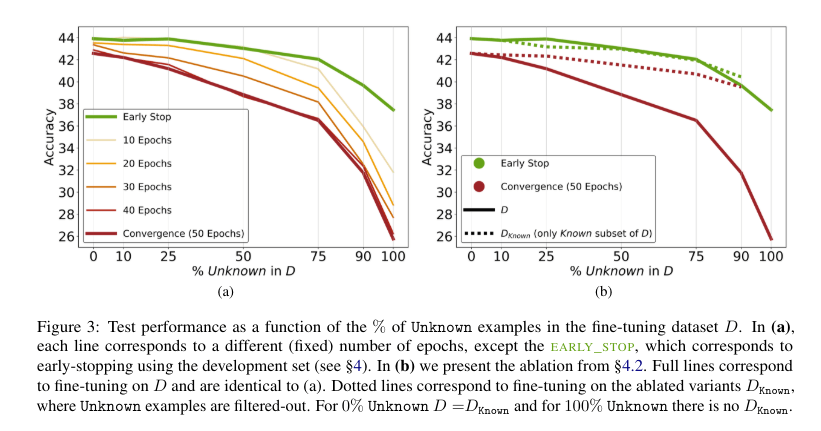
以上の結果を踏まえると、ファインチューニングは特定のドメインの知識を再学習する手法として注目されている一方で、モデルにとって未知の知識を正しく獲得することが得意ではないアプローチであるといえそうです。
出典:https://arxiv.org/pdf/2405.05904
最後まで読んでいただきありがとうございます。
今回は、Grounding DINO 1.5 Pro/Edge公開、RAGの脆弱性について学ぶ、LLMはファインチューニングによって新しい情報を得ることができるか?の3つのトピックをご紹介しました。
ブレインパッドは、LLM/Generative AIに関する研究プロジェクトの活動を通じて、企業のDXパートナーとして新たな技術の検証を進め企業のDXの推進を支援してまいります。
次回の連載でも最新情報を紹介いたします。お楽しみに!
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説
















