メルマガ登録
ベストなDXへの入り口が見つかるメディア


-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
ベストなDXへの入り口が見つかるメディア
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

みなさんこんにちは。アナリティクスコンサルティングユニットの崎山です。
2022年にChatGPTが登場して以来、LLM(LargeLanguageModels、大規模言語モデル)、およびGenerativeAI(生成AI)に関する技術革新が日々進み、それを取り巻く社会情勢もめまぐるしく変化しています。
これらの技術の社会実装に向けた取り組みや企業への支援を強化するため、ブレインパッドでもLLM/生成AIに関する技術調査プロジェクトが進行しており、最新トレンドの継続的なキャッチアップと情報共有を実施しています。
本連載では、毎週の勉強会で出てくるトピックのうち個人的に面白いなと思った事例・技術・ニュースをピックアップしてご紹介していきます。
※本記事は2024/6/20時点の情報をもとに記載しています
【関連記事】
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

6月19日に開催された「Google for Japan 2024」にて、GoogleからAIを活用した新たな取り組みが発表されました。
その中で、東京大学の松尾・岩澤研究室(松尾研)とパートナーシップを締結し、2027年までに47都道府県における地域課題の解決をサポートする生成AIモデルの実装と、AI人材の育成を支援する取り組みを発表しました。
取り組みの第一弾として大阪府における雇用マッチングに生成AIを活用する取り組みが紹介されているほか、今後広島県から取り組みを始めるとのことです。
少子高齢化・労働人口減少が進む近年、限られた労働者1人1人の生産性向上やそれらを通じた企業の競争力向上が日本社会における喫緊の課題になってきています。
こういった課題に対し、日本のAI研究最先端の研究室と最高峰のテック企業、地方自治体が産官学で連携して取り組んでいくというのは明るいニュースだと思います。続報に期待です。
出典:https://blog.google/intl/ja-jp/company-news/technology/ai-google-for-japan-2024/
NVIDIAは6月14日、Nemotron-4 340B という新しいオープンソースのLLMモデルを発表しました。これは、人工知能(AI)をトレーニングするための合成データを作成するためのモデルです。
ここで述べられている合成データとは、現実世界のデータの特性やパターンを模倣しアルゴリズムを用いて人工的に生成されたデータです。
AIのトレーニングには大量の良質かつ堅牢なデータが必要ですが、これらを実データだけで集めきるには非常に時間やコストがかかります。合成データを用いることで、大量かつバラエティに富んだデータを簡単に生成でき、また実データではないためプライバシーの懸念なども軽減できます。
【関連記事】合成データでLLMを学習する際のベストプラクティス発表
Nemotron-4 340B の良いところは、単に高品質で多様な合成データを合成できるところだけではありません。
Nemotron-4 340B は、生成された合成データの品質を評価し、助けになるか・正確さ・一貫性・複雑さ・冗長さの5つの観点でフィルタリングします。これにより、データの品質を向上させることができるのも利点の一つです。
また、ライセンスは「NVIDIA Open Model License Agreement」ですが、基本的にOSSと同等の許容度で、このモデルを用いて作成された合成データを他のLLM開発に使っても良いという太っ腹っぷりです。
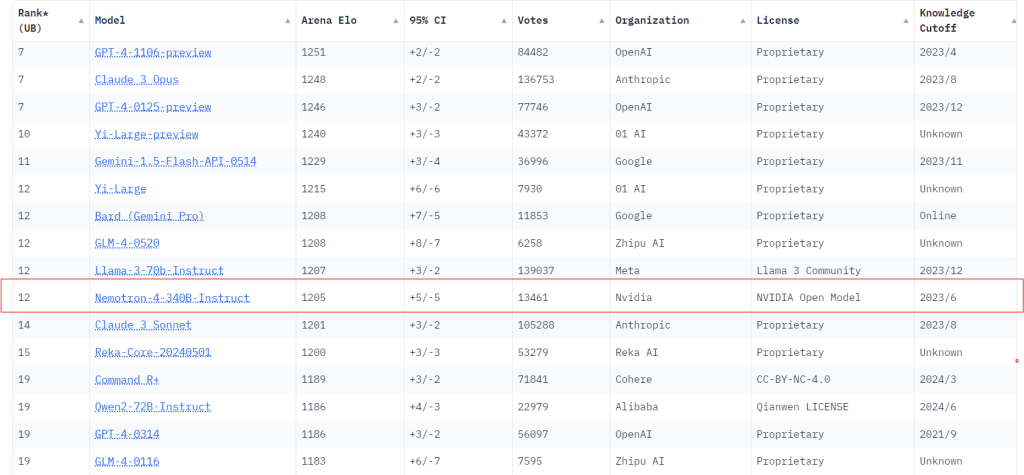
モデル自体の性能評価も高く、モデルの性能比較サイト「Chatbot Arena」ではMeta社のオープンソースモデル LLaMA-3 70B-Instruct と同等の性能を発揮していることがわかります。
モデルはオープンソースで公開されており、すでにHugging Face上でアクセスすることができます。興味がある方はぜひご覧ください。
【参考】Nemotron 4 340B
出典:https://blogs.nvidia.com/blog/nemotron-4-synthetic-data-generation-llm-training/
AIが事実に基づかない情報を生成する現象のことを「ハルシネーション」といいます。
このハルシネーションの軽減のために、RAG(検索拡張生成、Retrieval Augmented Generation)などの既存手法では外部の知識を参照させることで対応させようとしていました。
【関連記事】プロンプトエンジニアリング手法 外部データ接続・RAG編
RAGを用いたハルシネーションの抑制は手軽かつ安価に始められる反面、精度が検索の性能に左右されることや、実際にはハルシネーション自体の抑制には不十分であることが指摘されています。
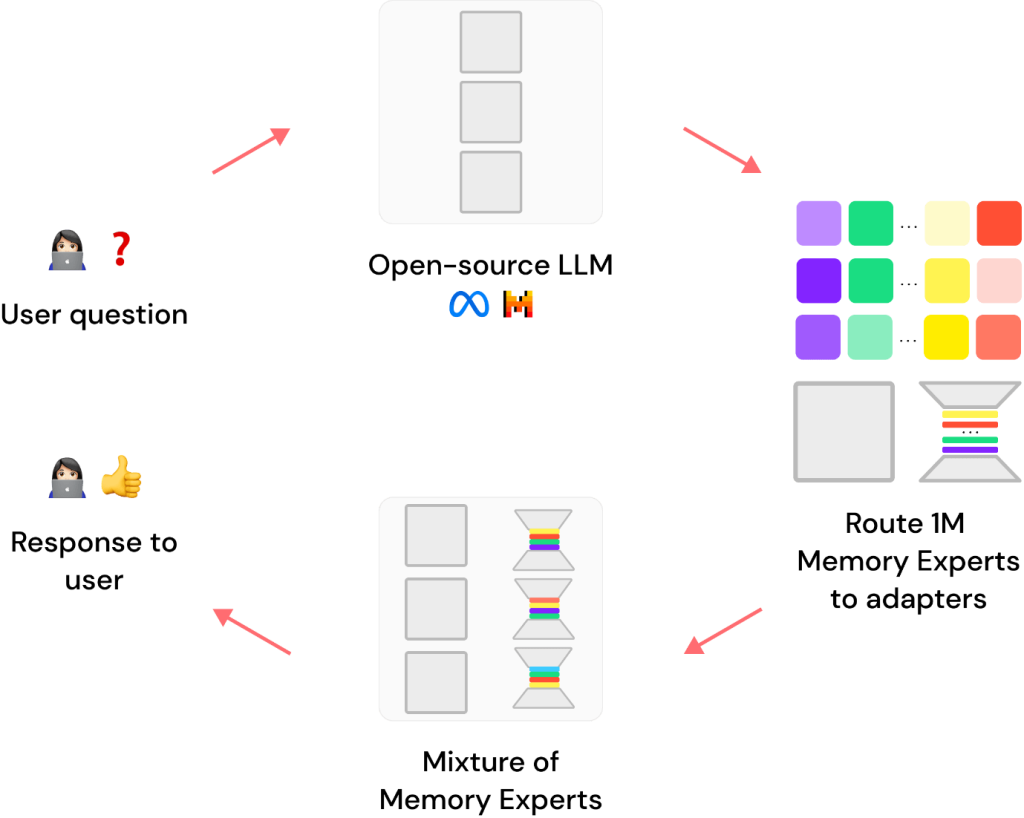
今回ご紹介する「Lamini Memory Tuning」は、RAGを使わずにハルシネーション発生率をRAGの1/10にまで抑えたファインチューニングベースの手法となります。概要をご紹介します。
今回Laminiが提案する Lamini Memory Tuning は、既存のLLMを LoRA* という専門アダプタを用いてチューニングし、モデルが推論する際にはその巨大なメモリエキスパートの混合(Mixture of Memory Experts。以降MoMEと呼称)の中から最も関連性の高いエキスパートを選択するという方法で生成を行います。
*LoRA(Low-Rank Adaptation)とは:ファインチューニングの手法のひとつで、元のモデルのパラメータを直接変更するのではなく低ランクの行列を導入してパラメータを変更するような手法です。
これにより、AIに対してより少ない計算量で効率よく追加学習ができるのがメリットです。特に画像生成モデルStable Diffusionのチューニングで話題になった手法だそうです。
例えばローマ帝国についてモデルから正確な事実を把握したいのであれば、Lamini Memory Tuning は「カエサル」「水道橋」「軍団」等ローマ帝国に関するエキスパートを選択します。
選択したエキスパートを使ってモデルは特定の事実(今回はローマ帝国)を記憶するために学習します。モデルの推論時には必要なエキスパートのみを用いて出力を行います。
結果として、以下のようなユースケースに活用されています。
また、一部の例ではモデルの出力の精度が50%から95%に向上したとの報告もありました。
この研究の面白い点は2点あります。
1つはハルシネーションの発生率がRAGの1/10にまで抑えられている点です。
2つ目はアダプタ(LoRA)を付けて過学習させているアイディアです。これにより、モデル全体の汎化性能は落とさないまま特定領域に詳しくすることが可能になっています。
今後は Lamini Memomry Tuning を用いたチューニングが一般的になっていくのかもしれませんね。
全ての領域に対して100%正答させることはまだできませんが、特定領域に特化させるには十分な性能を発揮できているように思います。
出典:
https://www.lamini.ai/blog/lamini-memory-tuning
https://github.com/lamini-ai/Lamini-Memory-Tuning/blob/main/research-paper.pdf
最後まで読んでいただきありがとうございます。
今回は、47都道府県の課題を生成AIで解決するGoogle・松尾研の構想、NVIDIAが大規模言語モデルのトレーニング用合成データ生成パイプラインをリリース、ハルシネーション発生率をRAGの1/10に抑えるファインチューニングベースの手法の提案の3つのトピックをご紹介しました。
ブレインパッドは、LLM/Generative AIに関する研究プロジェクトの活動を通じて、企業のDXパートナーとして新たな技術の検証を進め企業のDXの推進を支援してまいります。
次回の連載でも最新情報を紹介いたします。お楽しみに!
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説