



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

3月23日に開催した「DOORS-BrainPad DX Conference2022」。
3000人を超える視聴申し込みをいただいた本イベントの内容をお届けいたします。
今回は、
株式会社ブレインパッド アナリティクス本部 アナリティクスサービス部 魚井 英生
による、材料開発(MI:マテリアルズインフォマティクス)のデータサイエンス実践事例と題したテーマについて解説していきます。
マテリアルズインフォマティクスプロジェクトとは、食品・製品開発における必要な値を再現するためにスムーズに実験を計画するというもの。概要からAIプロジェクトとの違い、数理最適化を用いた特性値の取得などといった内容についてみていきましょう。

今回はマテリアルズインフォマティクスの適用事例について解説いたします。まずは、MIプロジェクトの概要からお話しします。
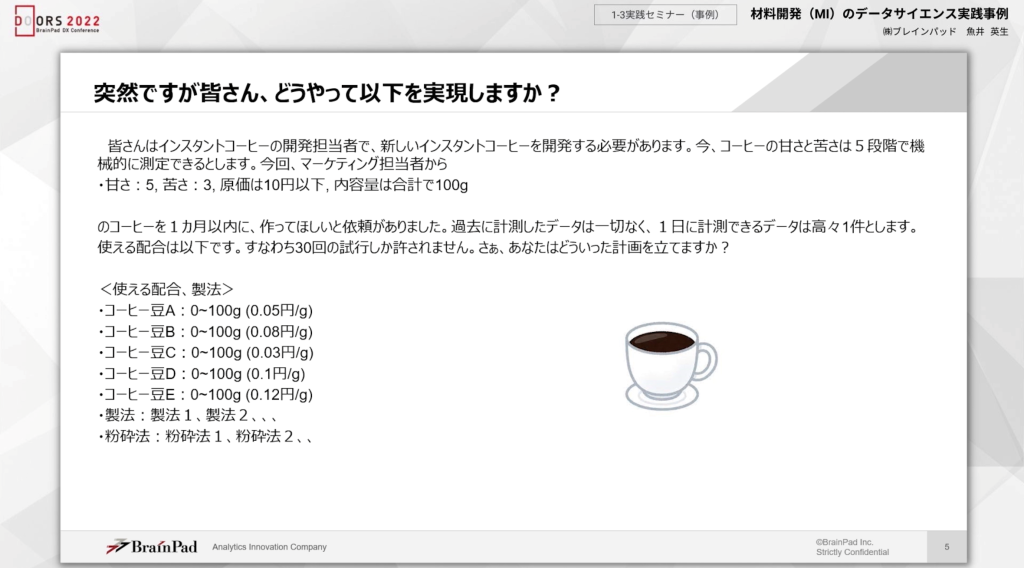
さて、以上のようなコーヒーの問題に対して皆さんはどのように対応しますか?
この条件では過去のデータはなく、1日に計測できるのは最大でも1件。使える配合や製法も限られているという状態にあります。
MI(マテリアルズインフォマティクス)プロジェクトはまさにこういった課題を解決するためにあるものです。実験そのものを計画していくことがプロジェクトのキーになります。
また、MIプロジェクトとは、食品・製品開発における必要な値を再現するためにスムーズに実験を計画するというものです。注目される3つの理由についてよりみていきましょう。
まずは、市場ニーズの多様性です。コーヒーに限らず、人の好みはより多様化してきています。そのうえで、コーヒーであれば甘さ・苦さ・コストなど、より細かい条件に合わせて調整する必要があります。
次の理由は新型コロナウイルスによる実験現場の人手不足です。実験には、人手が必要であることに加え、実験を行える環境・人材を整えることも難易度が上がっています。そのため、少ない実験回数で成果を出すことが求められる環境に変化してきていますね。
最後の理由は、熟練者の知恵の伝承です。簡単にいえば、属人性が高いということだけでなく、「仮に開発に関わっていた熟練者が退職すれば、知識が全て失われるため、実験を1からスタートする必要がある」状況になってしまうためです。
実際、熟練者の知恵を反映できれば、今回のコーヒーに限らず様々な製品における実験をよりスムーズに進められます。
需要予測のAIプロジェクトとMIプロジェクトは以下のように大きな違いがあります。

ここからは、図表の内容をさらに細かくして、AIプロジェクトからみていきましょう。データが溜まる速度は、1日数百万件です。KPIは余剰在庫の削減、核となる技術は機械学習による未来予測です。データサイエンティストが価値を発揮するのは、データが溜まったあとになります。
対して、MIプロジェクトではデータが溜まる速度は1日1件程度の規模です。KPIは実験作業の人件費の削減、核となる技術も数理最適化による実験計画が大切といえます。データサイエンティストが価値を発揮するのは、データをどのようにして溜めるかという計画の段階です。候補となる項目を洗い出す作業がポイントとなります。
それぞれの内容の違いをふまえたうえで、プロジェクトの進め方もみていきましょう。
AI プロジェクトでは、データの倉庫となるDWHの導入が大切になるものの、MIプロジェクトは目標値を設定することがポイントになることから、DWHは不要です。加えて、制約条件を決めるタイミングで熟練者のノウハウを反映させていきます。
さらに詳しくみていきましょう。AIプロジェクトは、「基盤構築からスタートし、社会的インパクトを予想し、実験を行ったうえで仕組みづくりを行う」という流れです。対してMIプロジェクトは、「目的とする特性値の配合を設定することからスタート。制約条件の段階で、これまでの知恵やノウハウを反映し、段階的に実験を繰り返して結果を導きだす」という流れとなります。
ビジネスインパクトの違いもみていきましょう。MIプロジェクトも含めた全てのプロジェクトは、インパクトが大切だと私は考えています。
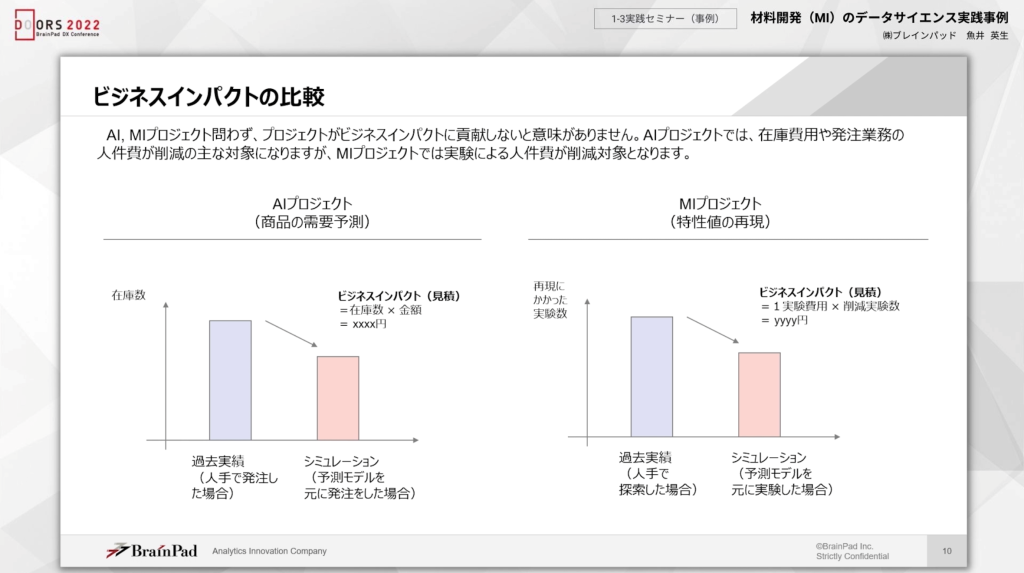
AIプロジェクトが目的の対象とするのは在庫費用や発注業務の人件費です。過去の実績に対して、予測モデルによるシミュレーションで比較します。対して、MIプロジェクトでは、1回の実験のコストと人件費がどのぐらい減少したかを比較することになります。
どちらもコストを比較していることは変わらないものの、対象となる項目が異なるといえるでしょう。
データサイエンティストの役割も大きく異なるため、解説していきます。AIプロジェクトは、データが蓄積されたあとにデータサイエンティストがデータを分析し、予測モデルを作っていきます。
MIプロジェクトの場合は、そもそもデータがないため、候補となりえる特性値を洗い出す段階でデータサイエンティストがサポートを行い、その後実験に移行するという流れです。

予測モデルにおいても、データバリエーションの多さに圧倒的な違いがあります。そのため、AIプロジェクトとMIプロジェクトでは予測精度の意味が大きく異なってくる点は大切なポイントです。データは大きく分けて、観測される領域である観測領域と観測されない非観測領域に分かれます。
AIプロジェクトの場合はデータが多いことから観測領域に該当するものが多く、過去に経験しているデータと被ってくるものもあるため予測が可能です。例えば、予測精度が80%などと表示された場合、モデルとしては全く問題ありません。
対して、MIプロジェクトは精度が高かったとしてもコーヒーなどの場合、甘さや苦さなど特定の項目に該当するかどうかはわかるものの、正確な値を観測できないといえます。そのため、MIプロジェクトは冒頭の課題を解決する場合、非観測領域を効率よく埋める実験を繰り返していく必要があります。
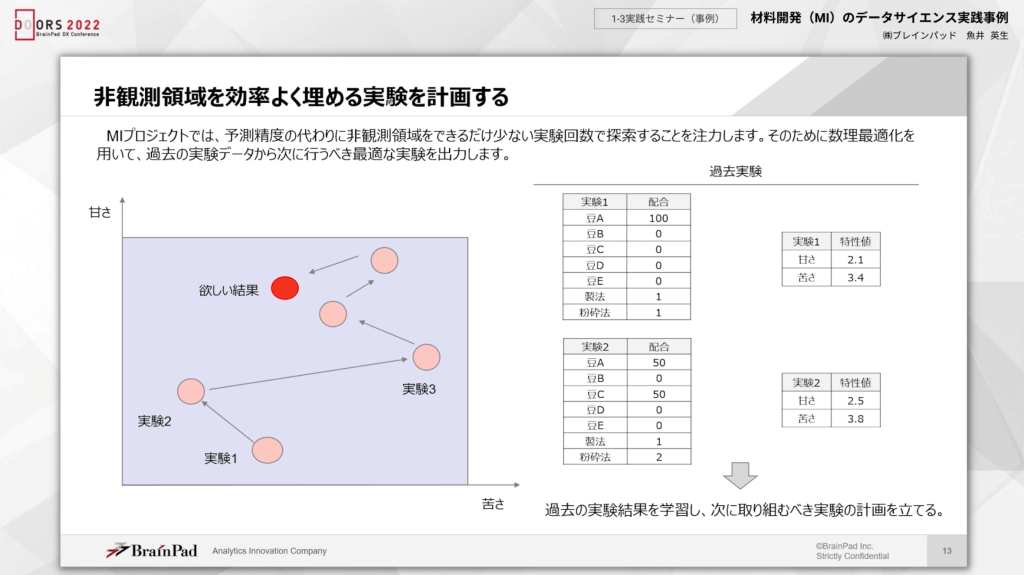
MIプロジェクトでは、予測精度を高めてもほぼ意味はありません。それよりも非観測領域をできるだけ少ない実験回数で効率的に観測していくことがポイントといえます。また、考え方として過去の実験結果から、数理最適化を用いて、次に取り組む実験の計画を立てることが大切です。
実験をやみくもに繰り返すのではなく、実験結果から機械的に計算していくものだといえます。
ここからは、冒頭の「あなたはインスタントコーヒーの開発担当者であり、新しいインスタントコーヒーを開発しなければなりません。また、コーヒーの甘さと苦さは5段階で測定できることから、マーケティング担当より、甘さ:5・苦さ3、原価は10円以下、内容量は合計で100グラムのコーヒーを一カ月で開発してくれと依頼された」という問いに対する答えをみていきましょう。
例えば、豆Eだけで実験すると、制約条件である原価10円を超えてしまうのでNGとなります。各種コーヒー豆を上手く混ぜ合わせなければならないことに加え、数多くの組み合わせがあっても全ての組み合わせの実験はできません。
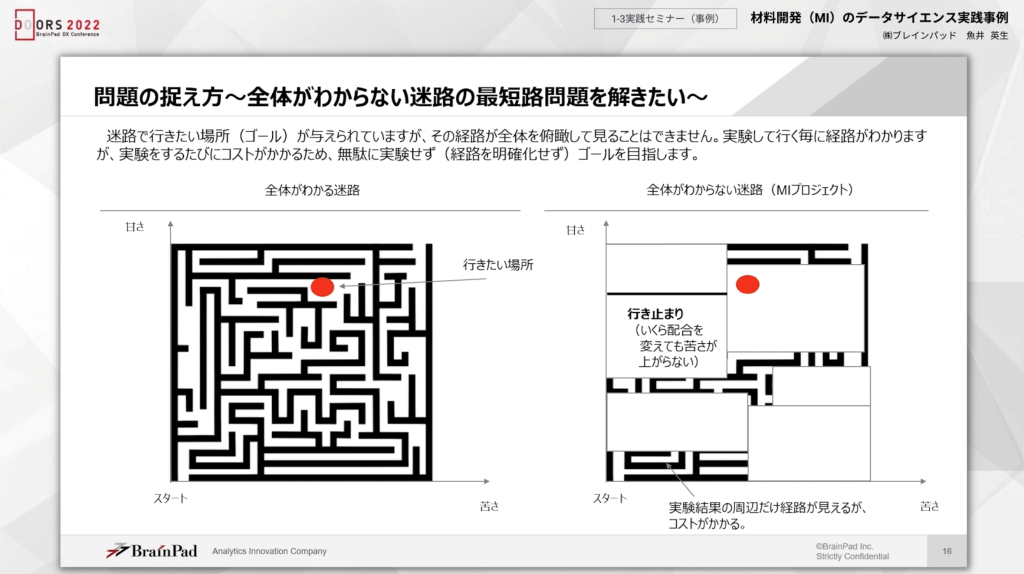
ここからは、問題の捉え方について少し違った側面からみていきましょう。今回の問題は迷路に置きかえると、全体を俯瞰してみることはできないものの、ゴールは把握できています。そのため、実験によってゴールに近づいていく作業が必要です。
さらに詳しくいうと、コーヒーの味として、甘さ3:苦さ5がゴールだとすれば、MIプロジェクトを迷路に例えると全体像はみえないものの、実験によって迷路の一部分は明らかにできます。例えば、配合を変えても甘さや苦さが変わらない場合は現実としてありえますが、全体像を明らかにしなくてもゴールにたどり着ければ問題ありません。
数理最適化は、与えられた条件の中から、最も良い結果を導くための計画を立てる方法のことです。今回の場合であれば、熟練者の知識を制約条件に反映させれば、目的に合わせた計画を効率よく立てることが可能です。

数理最適化には、目的関数と制約条件というものがあります。今回の場合だと、Xの値は、変数として豆AからEまでを合計して100グラム、原価10円も単純な掛け算で算出可能です。ここで、過去の経験から熟練者の豆Cと豆Dの特性が反発するといった知識を反映したうえで、配合すれば、目的とする味や選択すべき製法や配合が見えてきます。
どちらか片方しか入れない論理制約もここで使用できます。そのため、次に行うべき実験は機械的に考えることが可能となります。
制約条件を洗い出した後には、配合のばらつき具合を最大化する目的関数を設定しましょう。そして、目的関数に対して、制約条件の効果推定に効率的なD最適計画法を用いてデータのバリエーションを幅広く取っていくことが計画スタート時の大切な要素となります。
例えば、上記の図表では、豆A・B・D・Eはありますが、Cは一回も使用していません。条件を満たした配合を複数で行い、どのような数値が出るのかを比較することを意識しましょう。
ここからは、機械学習が関係してきます。ステップ2で取得したデータを学習することで、非観測領域の確率分布が作成できるようになるでしょう。今回のケースでは、甘さや苦さが欲しい特性値に近くなるように考えていくことで実現確率を高めていきます。
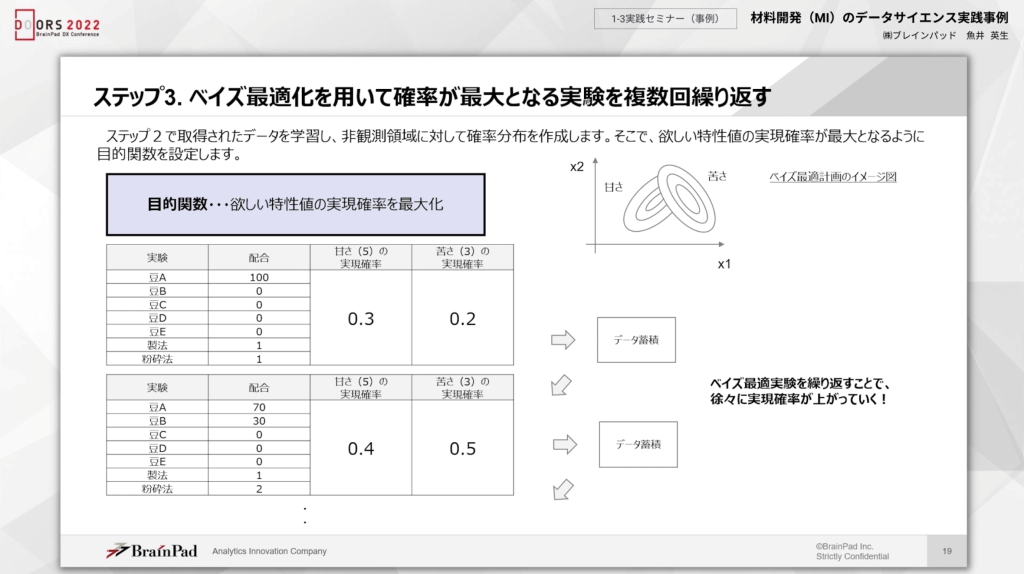
確率は実験ごとに上昇し、目的の特性値がでるまで繰り返されるため、最短で解答にたどり着くことが可能です。
上記の図表では、豆Aのみでは実現確率は低かったものの、豆Bを混ぜることで数値が改善しています。このような流れで目的の数値を満たすまで繰り返していくことになるでしょう。
結論として、D最適実験とベイズ最適化による最短路を実現できるといえます。D最適実験の段階では幅広くデータを取得することが目的です。その後、データを学習し実験を繰り返すことで、ベイズ最適化の確率を上げられるため、1カ月などの短い期間で欲しい特性値が再現可能となるでしょう。
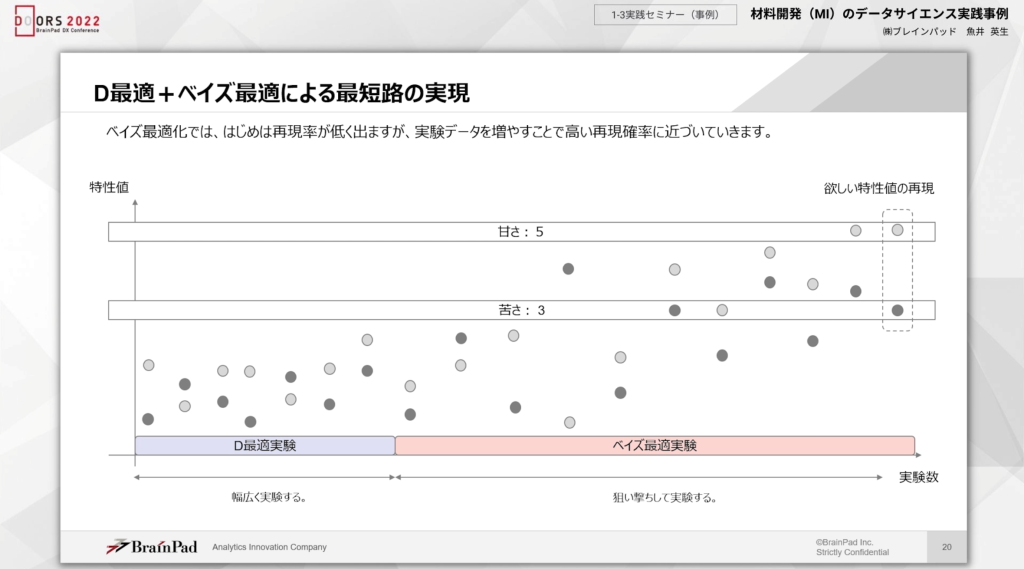
冒頭に述べた問題の解答は、以上になります。ベイズ最適化では、再現率が低く出たとしても、徐々に高めていくことができるが可能です。
ここからは、マテリアルズインフォマティクスを現場でどのように活用するのかについて事例をみていきましょう。最近の傾向として、データ分析の結果を如何に現場に対して、迅速に活用できるかといった点が求められています。従来までの報告では、共有が遅いだけでなく、迅速なデータの反映もできませんでした。
つまり、迅速なデータ分析の結果を反映させるため、データサイエンティストであってもWebアプリケーションを実装する能力が求められているといえる状況になっています。
従来のデータ分析の最大のデメリットは、報告資料によって行われていたため、「欲しい時に欲しいタイミング」で結果を出すことができないというものでした。しかし、Webアプリケーションとして実装できれば、迅速にコミュニケーションが取れるだけでなく、「顧客が欲しいタイミングで結果を出す」ことが可能となります。
そのため、 Webアプリケーションによる情報の共有がより重要な意味を持つようになりました。今回であれば、1画面で結果を取得できる以下のようなWebアプリケーションをクラウド上で作っています。

構造は非常に簡潔であるものの、PythonのWebフレームワークを用いることで、データサイエンティストのみでプロジェクトを進めることができるようになっています。要件定義やWebデザインの必要もありません。
また、私の視点からすると、以下のような制約条件のON/OFFは重要なポイントですね。
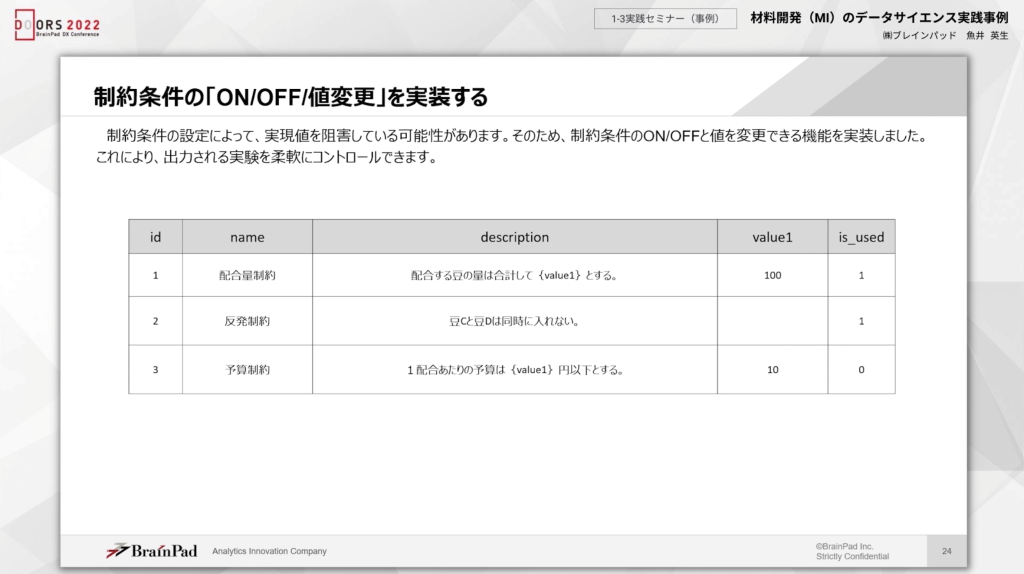
場合によって、「満たしたい制約条件の値を顧客が変化させられるような設計」を意識しています。例えば、上記の図表であれば配合量から予算に至るまで細かく設定可能です。
さらに詳細に分解すれば、3番目の条件は今10となっているものの、20にしたい場合、顧客が自由に制約条件を変えられるようにするといった工夫を意識しています。そもそも、「今の材料で目標にたどり着くのかを検証する」場合、制約条件そのものが必要ないケースもあるでしょう。
とくに予算に関しては、制約することで特性値を満たせないだけでなく、実験のバリエーションも減少するため注意が必要。総じて、アプリケーションを作成する際は「制約条件を適用するかどうかの判断を顧客の意思によって、できるようにする」ことが大切です。
これまでの解説をまとめると以下の3点がポイントになります。
それぞれを詳しくみていきましょう。
MIプロジェクトは予測精度がプロジェクトに与える影響力が小さいといえます。そのため、予測精度を高めるプロジェクトには適しません。目的とする特性値を得るために「データを蓄積することで、無駄な実験を省き、人件費の削減を狙うことが大切」な意識になるといえるでしょう。AIプロジェクトとはそもそも考え方が異なります。
実験結果を機械的に出力するために、数理最適化のフレームワークを使用することになります。また、その際には熟練者の知恵やノウハウを制約条件として取りいれることがポイントです。そのうえで、初期はD最適化計画法を実施し、段階的にベイズ最適計画に移行。目的の特性値が出るまで繰り返していくという進め方が適しています。
実験計画のPDCAを早く実施するためにWebアプリケーションをできる限り早い段階で実装することも1つのポイントになります。その流れであれば、データサイエンティストに頼らずとも顧客が結果を簡単・スムーズに受け取ることが可能です。
では、今後の展望についてもふれていきます。ベイズ最適化は、人が望む値を出すために結果を返していくという方法です。この方法は、マテリアルズインフォマティクスプロジェクトのみでなく、マーケティングにも応用できるかと思っています。
例えば、以下のようなマーケティングの予算配分などにもベイズ最適化の考え方を応用できます。
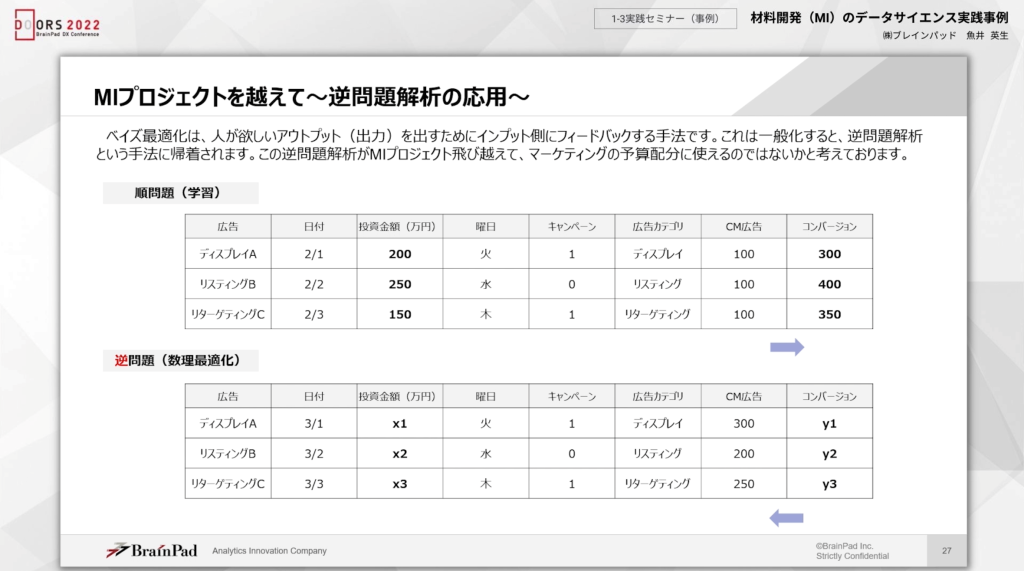
結果から要因を検討する逆問題解析として検討してみると、「CVを目標値として、投資金額をどのように調整すれば望む結果を導けるのか?」といった予算配分の課題に活用できるでしょう。
上記の図表からすれば、準問題ではいくつかの広告媒体に投資を行い、結果(CV)もあるとします。この場合、機会学習で予測することは簡単です。
対して、マーケティングは「CVを伸ばすために投資金額をどうしたらいいのかを検討しなければならない」ものです。そのため、ベイズ最適化と同様に考えられるといえます。実際のマーケティング支援プロジェクトでは、まだベイズ最適化の考え方は応用できていないものの、活用できる場面は多いと期待しています。
ご清聴ありがとうございました。
▼DXの定義や意味をより深く知りたい方はこちらもご覧ください
「DX=IT活用」ではない!正しく理解したいDX(デジタル・トランスフォーメーション)とは?意義と推進のポイント
【後編】数理最適化の新時代到来~最適化→予測でDXは加速する~
「逆問題解析」~人間が受け入れやすい 、自然な解釈を生む数理最適化の新たな活用法~
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













