

メルマガ登録
ベストなDXへの入り口が見つかるメディア


-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
ベストなDXへの入り口が見つかるメディア
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

こんにちは。株式会社ブレインパッドでデータサイエンティストを務める辻です。
本記事では、LLM(Large Language Model:大規模言語モデル)について基礎的な内容から応用領域まで網羅的に解説します。具体的には以下の内容です。
下の目次の気になる箇所から読んでみてください。見出しの冒頭に【発展内容】と記載がある内容はより専門的な内容になっているので、難しい場合は読み飛ばしていただいても構いません。
※生成AIやLLMの台頭により激動となった2023年において、ビジネスパーソンによく読まれた記事ランキングを以下の記事にまとめました。よろしければこちらもご覧ください。
2023年にもっとも注目された生成AI&DX記事

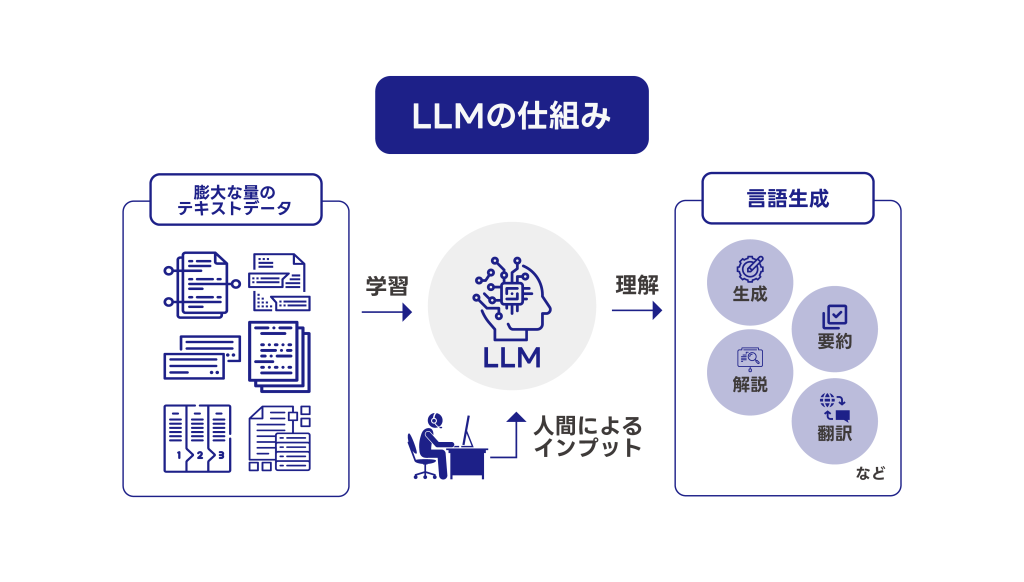
LLM(大規模言語モデル)は、自然言語処理(NLP)の分野で使用される深層学習モデルの一種であり、その主な目的は、膨大な量のテキストデータを学習し、人間のような自然な言語生成や理解を実現することです。
技術的な側面からもう少しお話すると、LLMは深層学習の技術を用いた複雑なモデルで、その基盤となるのはニューラルネットワークと呼ばれる人間の脳のニューロンの働きを模倣する計算モデルです。
このニューラルネットワークは、複数の層からなる構造で入力データを受け取り、パターンを学習して予測や分類を行うことができます。特に、LLMは巨大なテキストデータを入力とし、大量のパラメータを調整しながら言語構造を学習させています。
代表的なLLMの例として
などがあります。
PaLMやChatGPTやLlamaは、人間の文章とほぼ同レベルの流暢さと論理性を持ったテキストを自動的に生成できるモデルです。これらのモデルは数十億ものパラメータから成る巨大なニューラルネットワークで、膨大な量のテキストデータから学習を行っています。
【関連記事】
ChatGPTとは?使い方・始め方・仕組み・最新の活用事例を一挙ご紹介!
LLMは機械翻訳やテキスト要約、対話システムなどの自然言語処理の主要なタスクに向いており、近年では人間並みの性能を発揮できるレベルに到達してきています。
LLMが最近注目されるようになった理由は、「これまでのAIでは到達するのが難しいと考えられていた人間の言語能力」に匹敵する性能を示し始めたためです。
※そもそも「AI(人工知能)」の定義を明確にしたい方は、以下の記事もあわせてご確認いただければと思います。
【関連記事】
入社1年目が教わる「はじめての人工知能」 第1回:人工知能(AI)とはなにか
自然言語は極めて複雑で、人間は赤ちゃんの頃から段階的に経験を通じて習得します。対してLLMは人間の言語獲得プロセスを模倣することで、人工知能システムに高度な言語スキルを、人間が言語を習得するよりもはるかに短い時間で身に付けさせます。
これまでもAIを用いたChatBotが開発されたり多言語翻訳のためのモデルが開発されたりと、AIに関連する技術自体は着実に進歩を続けていたのですが、LLMの出現によってそこからさらに圧倒的な進歩を遂げました。
これまでのAI技術では実現が難しいとされていた「人間との自然な対話・応答」がLLMによって実現が可能になったことで、大きな注目が集まるようになったのです。
最近、AI関連の技術用語がメディアなどで頻繁に登場するようになりました。その中でも、LLMに似た用語である「生成AI」「自然言語処理」「機械学習」は、LLMとの違いがいまいちよく分からない方も多いと思います。
これらの用語は確かにLLMと関連はしていますが、意味するところは異なりますので、それぞれ簡潔に違いを説明します。
LLMは、前述した通り「膨大なテキストデータから言語のパターンを学習し、テキスト生成や要約などのテキストに関わるタスクを高い精度で行うことができる深層学習モデル」です。
一方、生成AIは、テキスト・画像・音声などを自律的に生成できるAI技術の総称であり、その生成プロセスはRNN、GAN、Diffusionなど多様に存在します。LLMは生成AIの中でも特に自然言語処理を担うモデルと位置づけられます。
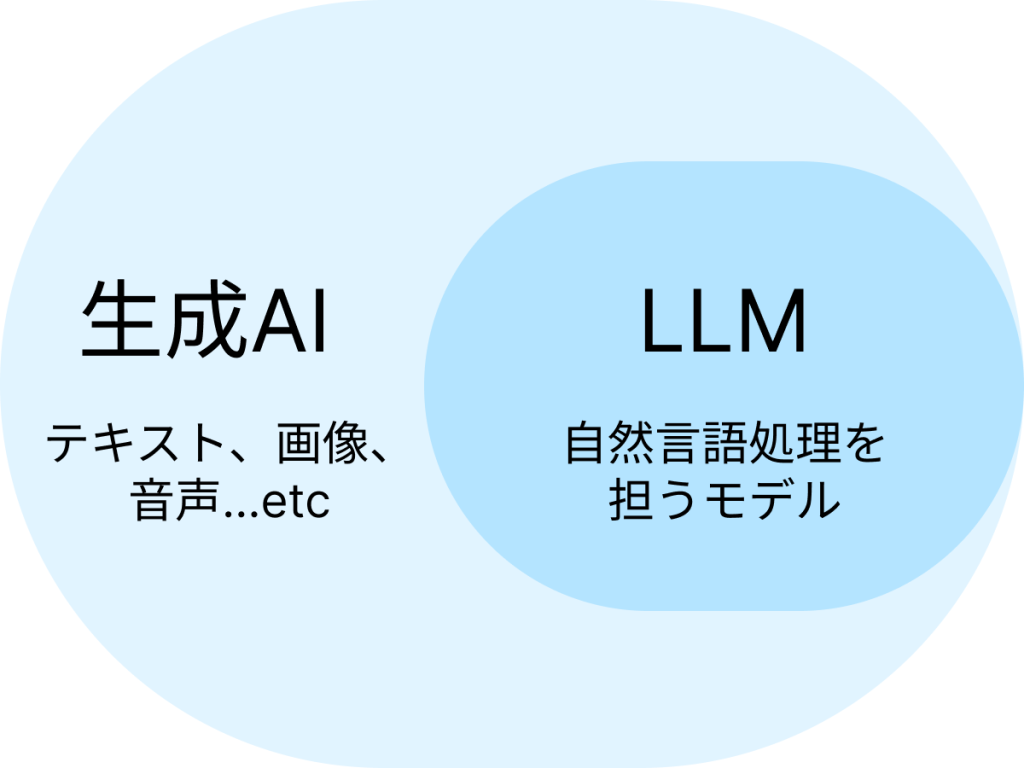
つまりLLMは、生成AIと呼ばれるモデルの中の一つなのです。
【関連記事】
生成AI(ジェネレーティブAI)とは?仕組みやChatGPTとの関連性を解説
ちなみに自然言語処理(NLP:Neuro Language Programmingとも呼ばれます)はコンピュータに人間の言語を理解・処理させる技術を指します。機械翻訳や文書要約など多岐にわたる応用があります。
LLMは自然言語処理タスクを解決する生成AIと見なすことができます。
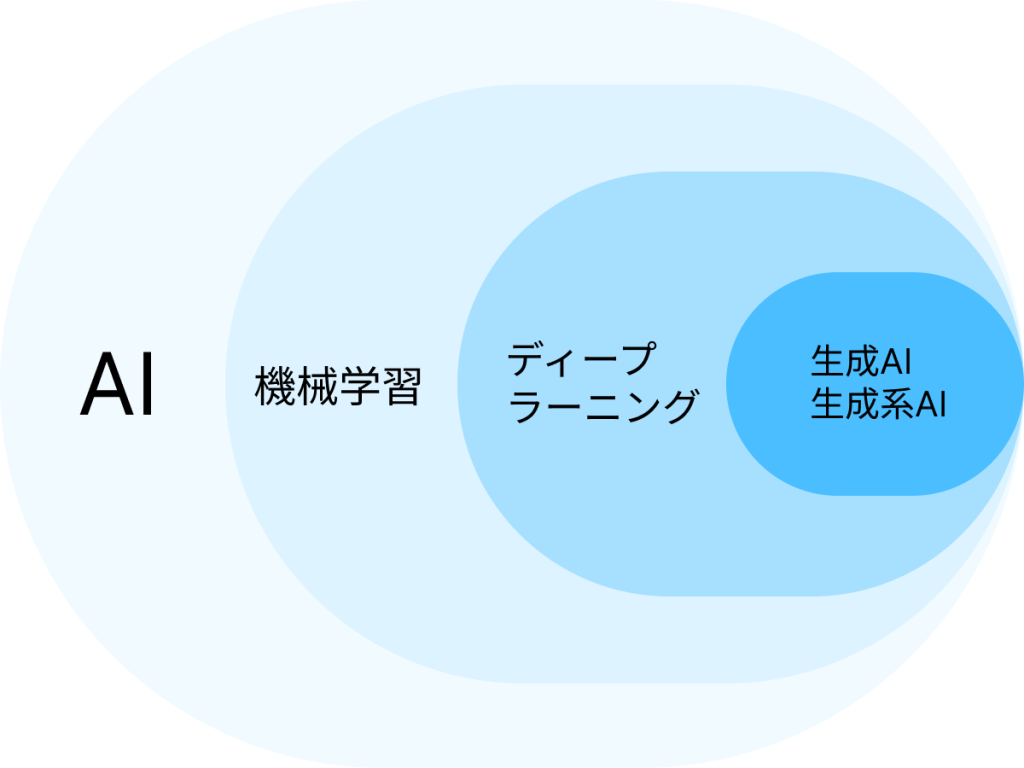
「LLM」と「機械学習」の立ち位置を簡単に説明すると、「LLM(生成AIの一種)」は「機械学習」の一種です。
機械学習は、統計学やデータマイニング手法を使ってコンピュータにデータから学習する能力を持たせ、未知のデータに対して予測や判断を行わせる技術のことです。データを入力し、そこから統計的なパターンや特徴を抽出することで、モデルを構築します。
このモデルを用いることで、新しい入力データに対する分類や回帰などのタスクを実行できるようになります。
【関連記事】
機械学習とは?3つの学習手法と知っておきたい活用事例
入社1年目が教わる「はじめての人工知能」 第5回:人工知能(AI)を支える「機械学習」の全体像
深層学習や生成AIは機械学習の応用分野の一つではあるのですが、その中でも画像認識や音声認識、会話の要約など従来の機械学習モデルではうまく対応できなかったタスクを解決できるようになってきたため、現在注目を集めています。
LLMはプロンプト(指示を送ること)によって、テキストに関わるタスクを高い精度で実行してくれます。以下はその例です。
このように、これまで人間しか行うことができないと思われていたテキストに関わるあらゆる処理が可能になってきています。
文章の要約の例を挙げると、膨大なドキュメントを短時間で読み込まなければならない場合、テキストデータをLLMに与え「この文章を要約してください」と指示を出します。すると、読み込む必要のある文章のうち重要な部分を抽出して提示してくれるため、従来よりも効率的に内容を理解できるようになります。
LLMを活用したモデルの一部をご紹介します。
| モデル名 | 開発組織 | 発表年 | 商用利用可否 |
| GPT-4 | OpenAI | 2023 | 可 |
| MPT-7B | MosaicML | 2023 | MPT-7B:可 (Apache-2.0)MPT-7B-Instruct:可(cc-by-sa-3.0)MPT-7B-Chat:不可(cc-by-nc-sa-4.0)MPT-7B-StoryWriter:可(Apach-2.0) |
| Llama | Meta | 2023 | モデル:不可コード:可(GNU General Public License v3.0) |
| Alpaca | Stanford Univ. | 2023 | モデル:不可Dataset:不可(CC BY NC 4.0)コード:可(Apach-2.0) |
| Vicuna | UC Berkeley | 2023 | モデル:不可コード:可(Apache-2.0) |
| Lit-LLaMA | Lightning-AI | 2023 | モデル:不可コード:可(Apache-2.0) |
| UL2(Flan-UL2) | 2023 | 可 | |
| Dolly-2.0 | Databrics | 2023 | モデル:可(MIT)データセット:可(CC BY SA 3.0) |
| Jurassic-2 | AI21 labs | 2023 | 可 |
例えばOpenAI社が開発した言語モデル「GPT-4」や「GPT-3」は、すでに多くの人たちに利用されている「ChatGPT」に使用されています。
ここからはLLMの具体的な活用例についてご紹介します。
従来の機械学習やAIは、生産性向上のための業務効率化や自動化を中心に展開され、RPA(Robotic Process Automation)による定型業務の自動化、需要予測、予防メンテナンスなどの具体的なタスクでの活用が主流でした。
しかし、LLMの登場によって、AIの活用領域は大きく変わりつつあります。
LLMは、従来の機械学習モデルが価値を発揮していた特定タスクの効率化・自動化という限定的な活用領域を超え、「収益機会の最大化」や「個別化された顧客体験の提供」など、より多岐に渡るビジネス価値を生み出すことが可能となっています。LLMの活用の可能性は広がりを見せており、比較的早期に導入が進むと見込まれている領域がいくつか存在します。以下、その事例と共に詳しく解説していきます。
【関連記事】
生成AI・LLMをビジネス適用するための検討ポイントおよびユースケース
ビジネスにおいて最初にLLMの恩恵を最も享受する領域は、この情報検索領域だと考えられます。
例えばミーティングで作成される「議事録」を読み返そうとしたとき、基本的には議事録ファイルを手動で開き、何が書かれているのかを都度確認する必要があります。これまではそれが当然でした。
しかしLLMを活用すると、膨大な議事録データから、その人が読み返したい必要な情報のみを取得してくれるようになります。これにより、情報検索のコストが大幅に削減されることが期待されます。
例えば、あるプロジェクトの進捗状況や課題点を第三者が把握したいと思った場合、LLMにそのプロジェクト名や関連キーワードを伝えるだけで、LLMはそのプロジェクトに関する過去の会議内容や議事録から必要な情報を抽出し、要約して提示してくれます。
海外のAIスタートアップ企業であるPineConeやOpenAI、Google CloudやAWSのようなメガプラットフォーマーなどもこのベクトル検索やEmbbeding検索と呼ばれる情報検索機能をサービスとして続々と提供し始めています。
広告や記事の作成を行う際に、LLMが今後サポートを行う可能性が大きく高まってきています。
これまでは人間の手によって、広告のコピーや画像の作成を全て実施してきました。
しかしこれからは、LLMが文章案を作成し、Stable Diffusionのような画像生成AIがイメージ案を作成することで、人間のクリエイティブ作成作業を効率化できるようになっていくと考えられます。
例えば、ある商品の広告文の作成業務にあたるとしましょう。
LLMに商品名やターゲット層、キャッチコピーなどのキーワードを与えることで、LLMはその商品コンセプトに適した広告文を生成してくれます。
そしてStable Diffusionに広告文と商品名を与えることで、その商品に合った魅力的な画像が生成されます。
※ただし、実際の活用を考えるとLLMやStable Diffusionが商品情報を正しく表現できる必要があるため、LLMに対してドメイン適応と呼ばれる工夫を加える必要があります。
また、生成AIのスタートアップ企業であるRunwayは、画像編集や動画編集に特化した生成AI技術を普及させるためのプロダクトを提供しており、その活用事例としてCBSやTopGearのようなテレビ番組、コマーシャルでの活用が進んでいます。
同社の公式サイトによると、映画監督兼編集技師が実際にRunwayのサービスを用いてフィルム、ミュージックビデオ、コマーシャルを制作しており、生成AIが新しい創作手法として注目されています。
【参考】How director and editor Evan Halleck uses Runway for films, music videos, and commercials
知識の習得には書籍や教育機関(学校など)による学習が一般的ですが、これまでの学習教材は、自分が理解できなかった部分に対して自動で補足説明してくれることはありませんでした。
また、学習を進めながら「専門的な理解をさらに深めたいと思った領域」を発見しても、その領域に関する教材に関しては自ら探しにいくか、適切な教師に聞きにいく必要がありました。
しかし、LLMは教育や新たな知識獲得のサポートを今後大きく担ってくれる可能性があります。
例えば「数学」について学びたいと思った時、LLMに数学を学びたい旨と数学の現状の理解度・興味度などを伝えるだけで、LLMはその人に最適な教材や参考資料を提供してくれます。
それだけでなく、LLMはその人が学習した内容や理解度のレベルを把握し、必要に応じて補足説明や問題演習なども行ってくれます。
さらに、LLMはそれまでの学習過程を通じて「その人が興味ありそうな関連科目」や「深掘りしたくなる可能性があるトピック」なども提示してくれるようになるので、自分のペースで好きなだけ学ぶことができます。
弊社ブレインパッドでも、プロトタイプ的に学習支援ツールを社内導入しています。
【参考】ChatGPTのAPIを使って、学習用ドキュメント生成ツール作ってみた
最後に、電話によるカスタマーサポートのオペレーション業務の事例を取り上げてみたいと思います。LLMは、カスタマーサポート体験の質を大きく向上させる可能性があります。
従来のようにカスタマーサポートへの問い合わせ手段が電話で、かつサポートの担当者が人間である場合、24時間の対応が難しかったり、サポートの質が担当者の質に大きく依存したり、顧客の問い合わせ分析を定量的に実施できないといった不都合が生じるケースが多くありました。
しかしここに、LLMが活用された24時間対応可能なカスタマーサポートチャットボットが実装されると、消費者の問い合わせ内容の分析と適切な応答・解決策の洗い出し・定型業務の効率化が実現され、過大な人件費を抑制しながらサポート業務の質を保ちつつサービスを展開できる可能性があります。
また、チャットボットの精度が上がれば上がるほど、顧客のニーズや要望に柔軟に対応できるようになるため、結果的に顧客満足度の向上にも繋がります。
このように、LLMの活用により企業は、消費者とのエンゲージメントを高めながら生産性と収益力を飛躍的に向上させることが可能になってきています。人とAIが協調しながら業務を遂行することで、企業はこれまでにないレベルの効率性と創造性を発揮できるようになっていくでしょう。
ここまではLLMの活用の可能性や有用性についてお話ししてきましたが、LLMを本格的に社会の中で浸透させていくには、乗り越えなければならない課題が存在していると考えています。
LLMは、自然言語を理解し、生成することができる革新的な技術です。これらの技術は、様々な分野で活用される可能性がありますが、同時に慎重に扱わなければならない課題も抱えています。
ここからは、LLMの活用における課題の一つである「出力の制御」について考察します。
LLMは、人間の言語を模倣することができますが、それゆえに人間が意図しない内容を出力することもあります。
例えば、不適切な言葉や偏見を含む文章を生成したり、著作権を侵害するような画像や事実と異なる情報を生成したりすることがあります。これらの出力によって、LLMを利用する企業や組織の信頼性や評判が損なわれるだけでなく、社会的な問題を引き起こす可能性もあります。
そこで、生成AIやLLMの出力を制御する方法が必要になります。
LLMの出力の制限対策である一つの方法は、コンテンツモデレーションと呼ばれる技術です。コンテンツモデレーションとは、LLMの出力を事前にチェックし、不適切な内容を検出し、削除や修正することを指します。
コンテンツモデレーションは、人間の手作業や自動化されたシステムのどちらでも行うことができますが、どちらにもメリットとデメリットがあります。
人間の手作業は、精度が高く文脈に応じた判断ができますが、コストや時間がかかります。自動化されたシステムは、コストや時間を節約できますが、精度が低く、文脈に応じた判断が難しい場合があります。
もう一つの方法は、ガードレールと呼ばれる制約です。
ガードレールとは、LLMに対して、出力すべき内容や形式をあらかじめ指定することです。例えば、「政治的な発言はしない」「暴力的な表現は使わない」「文法的に正しい文章を書く」などのルールを設定することです。
ガードレールは、LLMに対して明確な指示を与えることで、出力の品質や安全性を向上させることができます。
しかし、ガードレールも完璧ではありません。ガードレールが過剰に厳しすぎると、LLMの創造性や多様性を阻害することになります。
逆に、ガードレールが過剰に緩すぎると、LLMの出力が不適切になる可能性があります。
LLMは素晴らしい技術ですが、一方でその出力を制御する方法はまだ確立されていません。LLMの活用においては、コンテンツモデレーションやガードレールなどの技術を適切に使い分けることが重要です。
また、LLMの開発者や利用者は、その技術の可能性だけでなく「責任や倫理」も考慮することが求められます。LLMは、人間の言語を理解・生成できる技術ですが、それゆえに人間の言語を尊重し、保護することができる革新的な技術であるべきです。
LLMが今後どのような分野に対して大きなインパクトを与えるかについて、前述した活用事例と重複する部分がありますが、以下のように考察しています。
教育分野では、LLMは学習者のニーズに応じてカスタマイズされた教材やフィードバックを提供できます。先ほどの「LLMの活用事例や身近な例」の章でも言及しましたが、学習者のレベルや興味に合わせて、最適な文章や問題を生成したり、学習者の回答や作文に対して具体的なアドバイスや評価の提供が可能になります。
また、LLMは多言語に対応できるため、異なる言語や文化の学習者同士のコミュニケーションや交流を促進することも可能となるでしょう。
ビジネス分野では、LLMは様々な業務や複合的なタスクの効率化・自動化を可能にします。
例えば、LLMは顧客の要望や質問に応じて適切な回答や提案を生成したり、膨大なデータや文書から重要な情報や知識を抽出したり、新しいアイデアや戦略を創造したりすることができます。
また、LLMはビジネスパートナーや競合他社の動向・傾向を分析したり、将来の市場や需要を予測したりすることもできるようになる可能性を秘めています。
エンターテイメント分野では、LLMは個々人の趣向に合わせたサービスを提供することで生活を豊かにすることができる可能性があります。
例えば、LLMは人々の好みや感情に応じてオリジナルのストーリーや詩や歌詞を生成したり、人気のある作品やキャラクターのパロディーや続編を作成したりすることが技術的には可能になってきています。
また、LLMは人々と自然な会話やゲームを楽しんだり、ユーザーの好みに合わせた表現や情報を提供したりすることもできるようになるでしょう。
LLM、および生成AIに関する技術革新は日々進んでおり、それを取り巻く社会情勢もめまぐるしく変化しています。
これらの技術の社会実装に向けた取り組みや企業への支援を強化するため、ブレインパッドではLLM/生成AIに関する技術調査プロジェクトが進行しており、最新トレンドの継続的なキャッチアップを行っています。
ここではプロジェクトの勉強会から、ビジネスに関わりの深いLLM・生成AI最新トピックを取り上げ、AI活用の現場に携わるコンサルタントが解説した連載記事をご紹介します。
最後に、LLMがどのような進化を遂げるかについて考察を述べて、本記事を締めさせていただこうと思います。
LLMの今後の進化についてですが、私は以下の三つの点でさらなる発展が見込まれると考えています。
LLMは大量のテキストデータを学習することで、自然言語処理のさまざまなタスクに対応できるようになります。
しかし、データ量だけではなく、データの質も重要です。
例えば、多様なジャンルやドメイン、言語、文化、時代などのデータを取り入れることで、LLMはより幅広い知識や文脈を獲得できます。また、データに含まれるバイアスや誤りを排除することで、LLMはより正確かつ公平な予測や推論を行えます。
また、LLMは基本的に「WEB上で収集可能なデータ」を用いて学習を行っているため、企業の機密情報や個人間の人間関係のような「WEBからは収集できない情報」に対する適切な回答は困難です。それを克服するためには、企業や個人の固有の状況や情報を踏まえて、適切に対応できるようなデータを集めてLLMを再学習させるための工夫も必要になってきます。
この「WEBから収集できない情報を学習させる技術」について例を挙げると、「ファインチューニング」があります。ChatGPTに社内文書を学習させ、社内情報をアウトプットしてくれるような仕組みの実装が可能です。これは通常のChatGPTでは実現不可能です。
以下の記事では、ChatGPTのファインチューニング実装について具体的に解説しています。あわせてご覧ください。
【関連記事】
社内文書に特化したChatGPT ファインチューニング実践編
LLMはパラメータ数が多いほど、より複雑な言語現象を捉えられると言われています。実際に、近年では数十億から数兆個のパラメータを持つ巨大なLLMが開発されており、驚異的な性能を示しています。
しかし、モデルサイズの増加は計算コストやメモリ消費も増加させるため、効率的な学習や推論の方法が求められます。また、実際のビジネス適用を考えると「人間なら数秒で終わるような応答が、LLMでは数分かかる」ような状態になってしまえば、導入はたちまち困難になります。
サービス品質の観点でも、LLMの推論の効率化は重要なトピックと考えられています。
例えば、量子化(*1)や蒸留(*2)と呼ばれる学習や推論の効率化技術を用いることで、LLMの性能を落とさずにモデルサイズを圧縮させる技術が日々発展してきています。
*1:量子化とは、モデルのパラメータ数や計算負荷を削減する一つの技術手法です。
*2:蒸留とは、すでに学習済みのモデルを模倣する一つの技術手法です。
LLMは人間の言語や知識を反映するだけでなく、人間の価値観や判断も影響を受けます。そのため、LLMは倫理的に問題のある内容を生成したり、人間に悪影響を及ぼしたりする可能性があります。
例えば、LLMは偏見や差別、虚偽や誇張などの不適切な言葉を使ったり、人間のプライバシーやセキュリティを侵害したりする恐れがあります。
これらの問題に対処するためには、LLMの開発者や利用者は倫理性と責任性を持って行動する必要があります。どんな行動かと言いますと、LLMの目的や制限を明確にし、適切な評価や監視を行い、問題が発生した場合には迅速に対応することが挙げられます。具体的には前述したコンテンツモデレーションやガードレールといった技術をさらに発展させていく必要があります。
LLMのような生成AIのビジネス活用を検討するうえで、「何から始めればいいかわからない」という方は多いと思います。
生成AIをビジネス活用に落とし込むまでの流れはいくつかあると思いますが、ここでは、データサイエンスの専門家集団として生成AIの技術探求のみならず、実用化に向けた壁を突破するために必要な知見を蓄積してきたブレインパッドが、2023年8月に提供を開始した「生成AI/LLMスタータープラン」に沿って、説明していきます。
本プランではビジネス活用の流れを以下のように設定しています。

スタータープランは、「まず簡易に試したい」というお客様のニーズに応えるリーズナブルかつスピーディな環境構築プランです。約1か月間で生成AIの利用環境を構築し、チャット画面を用いた簡易機能を実際に操作することが可能です。
生成AIのビジネス活用を考慮する場合、まずは生成AIの活用イメージを膨らませることが重要です。
また、生成AI/LLM活用の勘所をつかんでいただいた方は、アドバンスプランを通して
といった、生成AIの本格的なビジネス活用施策を具体化する「ロードマップ策定」、もしくは施策を実行に移す「本格システム実装」いずれかのサービスを利用いただけます。

AI技術はこれまで着実に進歩を遂げてきましたが、LLMによる技術進歩は従来の発展と比べると遥かに大きく、一つのパラダイムシフトを迎えたと言っても過言ではないかもしれません。
しかしその革命的な技術の裏にはまだまだ課題も多く、ビジネス適用には数々の壁が立ちはだかることと思います。あくまでLLM活用は手段の一つであり、目的に適した活用であるかどうかの見極めは重要だと言えるでしょう。弊社ブレインパッドでも生成AIやLLMのビジネス活用は徐々に支援させていただいておりますので、ビジネス活用に際するご相談やお悩みがあればお問い合わせいただければと思います。
記事・執筆者についてのご意見・ご感想や、お問い合わせについてはこちらから
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説












