



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

機械学習モデルが業務にも適用されるようになり、「MLOps」という言葉が脚光を浴びつつあります。大手パブリッククラウドでもMLOps向けのサービスを次々と提供しており、これらを活用すれば機械学習モデルの保守・運用が簡単に自動化できると考えている方も多いのではないでしょうか。
ところが実際には、MLOpsの適用事例はまだまだ少なく、成功事例は数えるほどしかありません。そもそもMLOpsの定義や範囲が曖昧なので、何をもって成功と言えるのか実ははっきりしていないのです。
そこで、MLOps開発および保守・運用の3年に渡る経験を持つ、株式会社ブレインパッド アナリティクス本部 AIプラクティス部の千葉紀之と、同データエンジニアリング本部 アナリティクスアプリケーション開発部の中村優作に、様々な課題があるMLOpsの現状と将来の展望について聞きました。
■登場者紹介
画像処理に関する多くの案件に従事。近年は機械学習・深層学習の導入支援に積極的に取り組む。
その他、需要予測や広告効果の最適化等にも従事。
分析システム開発エンジニアとしてブレインパッドに新卒入社。入社後は、書類作成業務効率化や配送最適化のプロジェクトに従事し、Webアプリケーション開発や機械学習モデルの運用に携わる。


DOORS そもそもMLOpsとは、何を指しているのでしょうか。
株式会社ブレインパッド・千葉紀之(以下、千葉) 機械学習(Machine Learning)とDevOps(開発と運用の連携)を組み合わせた造語です。DevOpsは、ソフトウェアにおける開発と運用・保守のワークフローを連携し効率化を目指すものですが、そこに機械学習モデルの開発および保守・運用が組み合わさることを指します。
通常のシステム開発であれば、要件が決まっていますので、ローンチの段階でトップレベルの品質で運用が始まり、あとはそれを保守・運用していく形になります。それに対して、機械学習モデルの場合には、運用しながらさらに学習データを蓄積し、それを使用して再学習することで精度の向上、あるいは維持に努めることになります。したがってモデルの精度としては未熟な段階でローンチするケースもありえます。
今回、事例として紹介するシステムは、まさに未熟な段階のモデルでローンチしました。これは、当初の計画として、最初から精度の高いモデルを構築するためにはデータ数が少なく、十分なデータを揃えようとするとローンチするまでに時間がかかりすぎることから、ローンチして使ってもらうことを優先したためです。現状存在しているデータでモデルを作成し、同時に開発したWebアプリケーションを運用することで、蓄積されるデータを用いて再学習して精度を高める方式を採用したのです。
DOORS 機械学習モデルの精度向上・維持とそのUI/UXの部分を司るシステムと同期を取りながら、双方の品質を向上していく取り組みと考えてよいでしょうか。
千葉 まさにおっしゃる通りです。最終的な目標・目的はお客様の作業効率の向上だったり、そこからビジネス価値を生み出したりすることです。機械学習モデルの精度向上・維持だけではなく、UI/UXも重要です。特に今回のシステムでは、使っていただくことで初めて再学習用のデータが蓄積されるわけですから、使い勝手の部分は特に重要でした。
MLOpsというと、一般的に機械学習モデルの精度向上・維持にフォーカスされることが多いのですが、再学習データの蓄積のためにはUI/UXを伴うシステムが必要になる場合が多く、その際には機械学習モデル開発だけ取り出して考えてしまうといろいろと問題が生じることになります。したがってモデルとUI/UXをワンセットで考えることが大切です。とはいえ実際にはなかなか難しいと痛感しています。
DOORS 教科書的な定義はわかりました。では、具体的なケースをお聞きしてもよいでしょうか。
株式会社ブレインパッド・中村優作(以下、中村) 今回紹介するケースは、大まかに言うと、銀行で作成した書類をある会社様でExcelシートに転記する業務があり、それを機械学習モデルとルールベースのAIモデルで半自動化するシステムです。最終チェックは人間がする必要があるものの、人手での作業を大幅に削減することを狙っています。
業務内容を説明します。ある取引を行うことを銀行に申請すると、銀行員が必要な書類(以下、「銀行作成書類」)を作成し、送られてきます。それを元に実際に取引で使う書類(以下、「取引用書類」)を作成します。「取引用書類」には定められたフォーマットがあり、それをExcelシート化しています。今までは担当者が「銀行作成書類」から必要事項を抜き出して、Excelシートに手で打ち込んでいました。「銀行作成書類」の中には、ただ書き写せばいい項目と、文章の中から必要箇所だけを抜き出し、体裁を整えた上で記載する項目があります。今回開発したシステムでは、「銀行作成書類(PDFまたはスキャン画像)」をOCRで読み込み、機械学習モデルおよびルールベースのAIモデルがテキストデータから抜き出す内容を判断して、Excelシートに埋め込むようにしました。なお最終的にExcelシートに埋め込みますが、担当者は直接Excelを操作するのではなく、専用のWebアプリケーションを新規開発し、その上で作業をしてもらうようにしました。ただ100%の精度はありえないため、人間が最終チェックします。
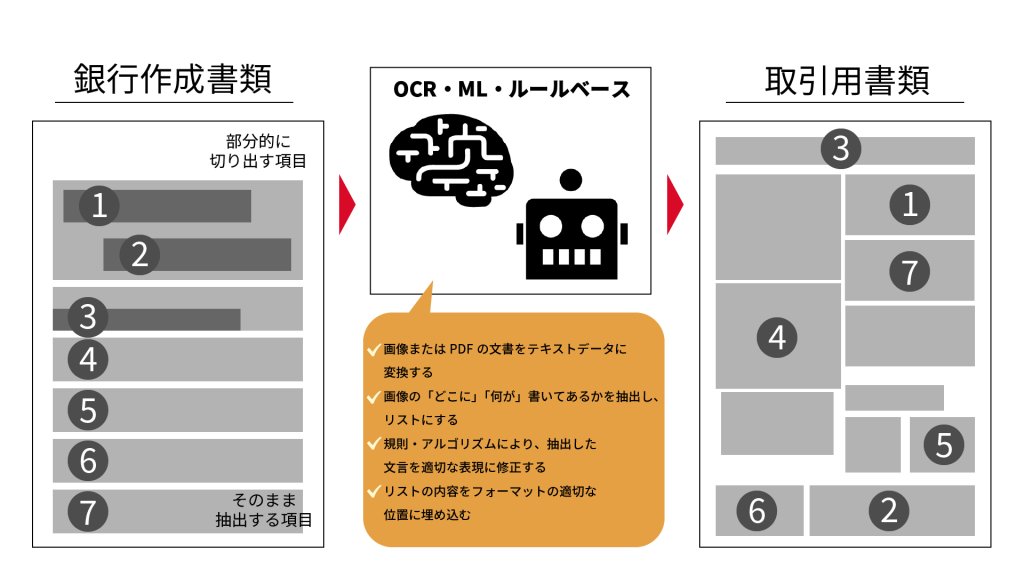
この転記業務を完結させるには、転記対象項目を検出する「ヒモ付け」、対象項目の形式を整える「整形」、対象項目中の単語を実際の値に置き換える「置き換え」の3つの処理が必要ですが、現時点では「ヒモ付け」と一部の項目での「整形」までしかできていません。
DOORS 「転記」と聞いて、単純に写せばよいと思っていたのですが、かなり人の判断が必要な業務なのですね。
中村 はい。「銀行作成書類」については国際的な規格があり、記載する項目も決まっていますし、箇条書きなど書き方の決まりもあります。したがって、ルールベースで判断できるところも多いのですが、長い文章を書く項目などでは銀行員による個人差が大きく、機械学習モデルによる判定が必要になります。
DOORS 開発内容は理解できました。運用方針について教えてください。
中村 ヒアリングの段階で、転記に関しては標準的なルールと例外的なルールがあることがわかりました。たとえば国によって特有のルールがあるのですが、対象となる書類が少ないため学習用データがなかなか蓄積できません。そこで当初は、例外的なルールに関しては機械学習の対象にしないことにしました。
千葉 今「当初」とありましたが、当初は「MLOpsの教科書」通りの運用を考えていたんですね。「システムが使われれば、再学習用のデータが蓄積されるので、それを用いて徐々に精度を向上させていきましょう」という方針をお客様に説明し、同意を得ていました。
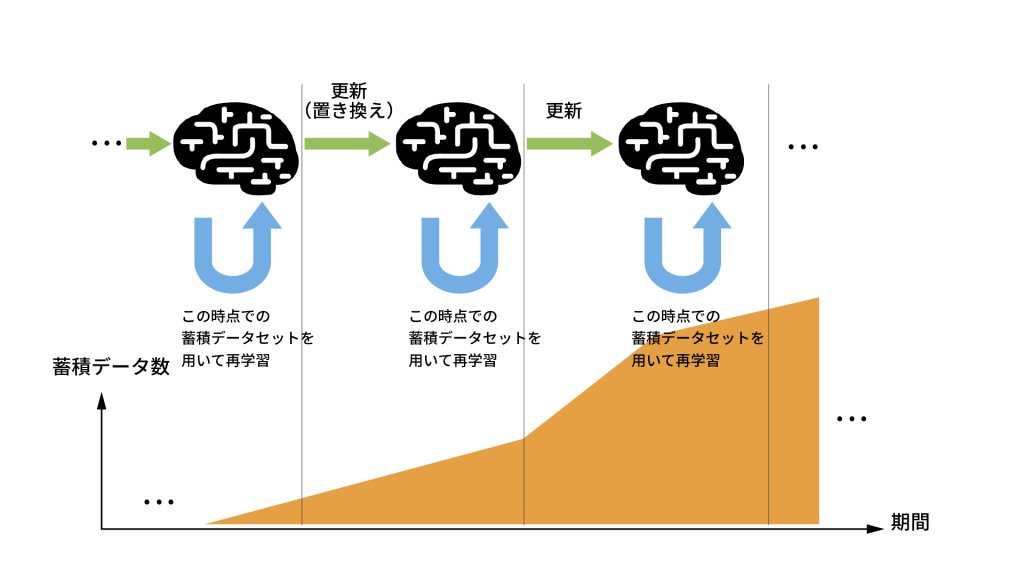
また初期は学習データがほとんどないので、ルールベースモデル中心で運用し、データがある程度蓄積されたら機械学習モデルに切り替えていきましょうという話もしていました。これも教科書的な進め方になります。
またこれも重要ですが、学習データが蓄積されたとしても、品質が悪いと再学習の結果精度が落ちてしまうことがあります。そこで再学習したら単純にモデルを更新するのではなく、いったん精度を評価してから更新するのか据え置くのかを判断するワークフローにしました。据え置く場合には、なぜ精度が落ちたのか原因調査することも含めています。
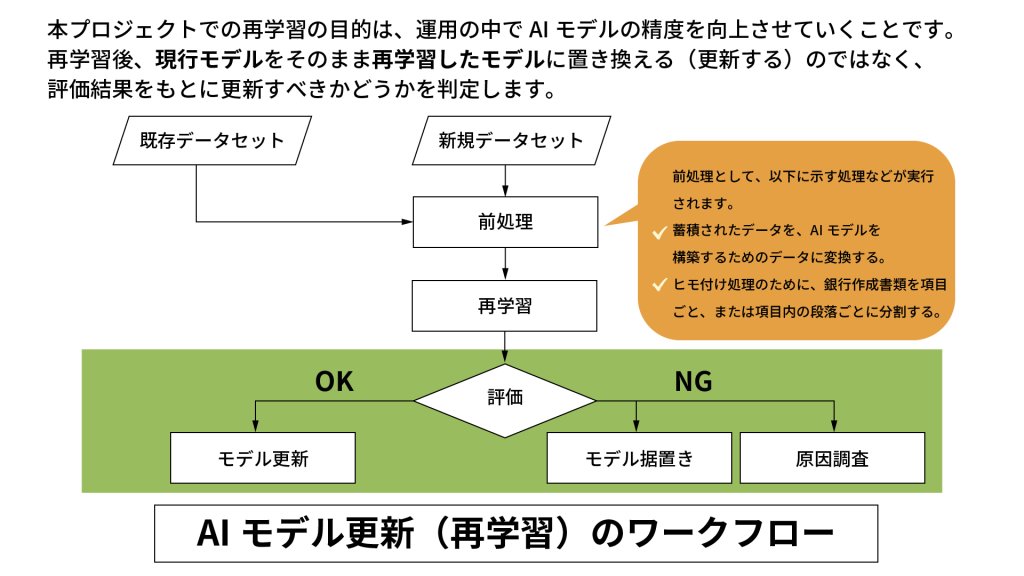
DOORS モデルの精度はどのように評価するのですか。
千葉 OCR読み込み、ヒモ付け、整形のそれぞれに評価指標があります。置き換えについては未実装なので、現時点では評価指標はありません。OCR読み込みに関しては、「NG数/総文字数」、ヒモ付けについては「NG数/評価した項目数」を指標としています。
整形に関しては、不必要な転記をどれだけ消したかと、転記されなかった内容をどれだけ足したかのそれぞれを評価します。消す作業に関してはアプリケーション内で文字を消すだけなので作業量は大したことはありません。足す作業については転記元の「銀行作成書類」を参照することになり、1文字足すだけでも作業量が大きくなります。したがって「足す作業が少ない=精度が高い」となるような調整をしています。
なお、転記内容を確認・修正するためのWebアプリケーションも提供しているため、モデルの精度だけではなく、作業効率の向上も評価項目に挙げています。
DOORS 「教科書的な運用方針」だったことを強調されていましたが、それではうまくいかなかったということでしょうか。
千葉 そうです。使ってもらうことで再学習用のデータを蓄積し、モデルの精度を向上しようという方針だったわけですが、そもそも使ってもらえなかったのです。
DOORS なぜ使ってもらえなかったのでしょうか。
千葉 リリース当初のアプリケーションは初期のものだったので、使い勝手があまり良くありませんでした。「手作業で転記するより余計に時間がかかるので使いたくない」と現場から言われてしまったのです。手作業といってもアシストツールが存在していて、プロジェクトを企画した部門から、アプリケーションがローンチされればツールと置き換えることができると言われていました。しかし、現場としては従来のツールのほうが使い勝手がよいということでした。
企画した部門も、どうにか現場で使ってもらおうということで、新入社員に研修の一環で、既にできあがっている書類をもう一度作成してもらってデータを作ったのですが、それだと学習データとしては数が少なく、精度が上がりませんでした。
結局1年ぐらい頭を悩ませた結果、お客様はグローバルな企業でしたので、入力アシストツールなどを持たない海外法人で使ってもらって、ようやくデータを蓄積することができたのです。
DOORS そのような状況になってしまった原因は何なのでしょう。
千葉 これは私たちの考慮不足だと反省していますが、私たちがヒアリングしたのは本社の企画部門と現場のリーダーが中心でした。実際に入力している現場部門と意識の違いがあったのです。また現場部門では作業時間がかかるとはいえExcelを使った作業には慣れており、大幅な修正処理があるなら別ですが、少ししか修正しないのであればExcelのほうがずっと簡単にできるといった事情もありました。これらは、ヒアリングの段階では聞き取り切れていませんでした。
中村 私たちには転記処理用のテンプレートが提供されて、それに基づいて開発したのですが、それが実はある個人が作った固有のテンプレートでした。作業担当者ごとに、それぞれで作成した固有のテンプレートを使っていることがわかったのです。それでは属人性が強いため、今回のシステム開発をきっかけに標準化されることになりました。ここは、システムを作って良かったと評価されている点です。
千葉 ただ逆にいえば、標準化がされていなかったことを認識していなかったといえども、業務標準化を行わずにAI導入を進めてしまったということです。これは良くありません。
モデルやシステムを作っても実際に運用されなければ目的は果たせない、だから使われるシステムを作ろう――これは私たちがいつも最重要だと考えることなのですが、いろいろと事情があって徹底できなかったことがつまずきの原因だったと思います。
DOORS 学習のためには何件ぐらいのデータが必要なのでしょうか。
千葉 ローンチ後、最初のモデルの再学習に新規データとして数百件程度必要だと想定していました。その後も、定期的に新規データを追加してモデルを再学習していく予定です。現在では月に百件前後のデータが蓄積されるようになり、何とか学習ができるようになりました。意外と少ない件数と思われるかもしれませんが、今は少ないデータ数でも効率的に学習できる手法が発達したので、いわゆるビッグデータでなくても精度の高いモデルが作れます。
DOORS 現時点での評価を聞かせてください。
中村 運用に乗るまで苦労はありましたが、モデルの精度もUI/UXも徐々に改善され、トータルで見たら作業時間が短縮されたという状態になりました。しかし、ゼロから「取引用書類」を作成する場合は作業時間が短縮されるものの、以前作成した書類の一部を変更するだけの場合も多く、その場合はExcelで直接修正するほうが早い点は変わっていません。
また、アプリケーションで「取引用書類」を作成し印刷する際、アプリケーションからExcelファイルにExport(ダウンロード)して、そのExcelファイルを印刷する必要があるのですが、レイアウトが崩れることがあります。これはアプリケーションではなくExcelの問題ですが、その際にレイアウトを手作業で直すのがけっこう大変だと言われています。こればかりは機械学習でどうにかなる話ではないので、将来的には別の手段を考えないといけないかもしれません。
ユーザーの使い勝手という面では、まだまだ細かいところまで突き詰められていないとは思います。ただ正確性は向上しています。AIによる自動転記の導入により、タイプミスによる差し戻しが大幅に減ったという報告をいただいています。
千葉 使い勝手が向上すれば一気に使われるようになり、精度も向上する――という地点の一歩手前まで来ており、MLOpsの事例としてはある程度成功しているのではないかと思います。ただシステム全体を考えるとまだまだ改善の余地があるというのが総括的な評価です。今回の様な機械学習を用いたアプリケーションの開発では、どうしても機械学習部分に注力してしまいがちです。しかし、UI/UXの部分も同じかそれ以上に突き詰めて考えなければ、そもそもシステム全体としてうまく回らない、というのが大きな反省点です。当たり前のように思えますが、この視点が抜けてしまっていないかを常に意識しながら開発を進めることが肝要です。
DOORS 他に当初考えていたこととのギャップはありましたか。
千葉 アプリケーションを使ってもらうことで正しいデータ、すなわち機械学習でいう「正解データ」が蓄積される想定だったのですが、出力されたExcelシートで間違いを見つけたときに、アプリケーションまで戻らずExcelシートだけを修正する人がけっこういました。実際の転記業務としては、Excelシートから印刷してしまえば完了してしまうので、わざわざアプリケーション上のデータを直そうとする人はなかなかいないのです。しかしそうされるとアプリケーション上のデータは正解データでなくなるので、学習には使えないことになります。
要するに利用者は、自分にとって楽な方法を選択するわけで、そこに関する考察が足りていませんでした。これらを踏まえて現在は、モデルの精度向上よりもUI/UXの改善が先だという議論になっています。
中村 機械学習モデルの再学習についてはもっと自動化できる想定だったのですが、実際には、いま千葉さんが話されていた正解データの問題があって、学習後の検証以外に、学習前にデータのチェックもする必要が出てきました。これについてはExcel上で間違いを見つけた場合でも、修正自体は必ずアプリケーション上で行うというオペレーションを徹底していただくしかありません。とはいえ、それが徹底されているかどうかはデータをチェックするまで分からないので、新しいオペレーションが浸透するまで、当面は学習前のデータチェックが必要と考えています。この点は、うまく自動化できないかを模索している最中です。。
千葉 思ったよりも運用に工数を割かれるということも、当初の想定との大きなギャップでした。正解データを作らないといけないので、私たちも「取引用書類」が作れるようになるまでドメイン知識が深まりましたが、これも想定外のことでした。
DOORS ドメイン知識が深まったのは、怪我の功名でもありましたね。他にはいかがでしょうか。
中村 月次の定例報告会で「前回と比べて精度が向上しました」という報告が毎回できていないのも、当初とはギャップがあると言えます。アプリでは正常に処理できない例外的なケースがどうしても月数件は存在するのですが、蓄積されるデータが現状では月百件ぐらいなので、数件の例外的な処理でもかなり大きなノイズになってしまいます。全体的な処理件数が少ないため、例外的な処理に失敗していると、統計的に精度が向上しているように見えないという課題があります。本来は例外的な処理を除いた部分での精度向上を優先したいところではあるのですが、お客様は例外的な処理をどのように減らせるかというところに目がいきがちです。この問題は、毎月の処理件数が増えていけば数件の例外によるノイズは十分吸収されるので、解決する問題です。
「銀行作成書類」のフォーマットが変更されていたり、ユーザーが使い方を変えたりすることがあるので、結局毎回全部のデータを確認しないと学習に入れないのはなかなか変わらないところです。
ダッシュボード的な管理ツールがあって、ユーザー側でどのデータに問題があるとか、誰の処理に問題が多いなどがわかるようになると理想的なのですが、結局私たちがデータを見ないとデータ品質が判定できないこともギャップと言えばギャップですね。
運用・保守に想定以上に工数がかかっており、これが一番大きなギャップだと捉えています。
DOORS 今回のケースを通じてこれからMLOpsに取り組む、あるいは既に取り組んでいるがなかなかうまくいっていないといった企業へ伝えたいメッセージはありますか。
中村 MLOpsというと一般的には、CI/CD(Continuous Integration/Continuous Delivery:継続的インティグレーション/継続的デリバリー)の環境構築をしたり、モデル管理のためにモデルレジストリ(機械学習モデルのライフサイクル全体を管理するための一元化されたリポジトリ)を作成したりといったモダンなイメージが先行します。しかし実際には、結局は人が使ってくれるかといったアナログな部分が意外と大事で、それに尽きる気がします。
今回のプロジェクトで良かったと思う点は、お客様の窓口の方が企画から運用まで一貫して、毎月の運用報告に出る課題解決に関して一緒に動いてくれたことです。そのおかげで当初の大きな目的からずれることなく進められました。
人の労力を減らすという目標については道半ばでも、転記の正確性が向上したことなどを評価してもらえているのも大きいと思います。そのおかげで、MLOpsの対象となるようなシステムにおいては、不確実性の高い機能であるため、初期に目標となるゴールを具体的に設定をすることが難しく、フィードバックループによる改善の中で効果測定をすることが望ましいと考えるようになりました。機械学習モデルは、AというインプットがあったらBというアウトプットが出力されるという性質のものではないので、使いながらフィードバックをもらって、それから次を考えるのが向いているのです。
千葉 今回はAI案件ということで承ったところがあり、AIの精度向上をどうするかという観点で提案し、進めてきました。しかし作業効率を良くしようとすると、想定以上にUI/UXの部分に左右されるとわかりました。場合によっては、UI/UXの良いシステムを作るほうがAIを導入するよりもてっとり早く作業効率を向上できたのかもしれません。だとすればAIを導入しない案も含めて検討するほうがよいと思います。またAIを導入するにしても、AIの精度以外のところで結果が出ない場合にどう評価するかを事前に決めておくことが大切です。
前述した通り、現場とのギャップを事前に埋めようという努力を私たちはいつもしているのですが、企画部門に聞くだけではやはり足りません。現場の方々へのヒアリングや実際の業務の見学をもっとやっておくべきだったと反省しています。 当時も現場の方々へのヒアリングは実施しましたが、立場としては現場の方々よりも上にあたる企画部門の方々も同席されてのヒアリングだったため、本音まで言い難かったのかもしれません。
正解データが蓄積されるだろうと安直に考えることも禁物です。そうならない想定外の阻害要因がいくらでもあるのです。いくら考慮しても足りないぐらいの心構えが必要です。
ただ考えるポイントはあります。現場は楽な方法と面倒な方法があれば楽なほうを選ぶこと、慣れ親しんだやり方をなかなか変えようとはしないということ、この2つを押さえておくとよいでしょう。これらについては、意識が変わるまで時間がかかるので、長期的な目線で考えるべきです。短期間に成果を出そうとすると結局成果が出ないことになり、その時点で終了となってしまいます。
中村 一気に切り替えるのは大変なので、最初は一部の方々から使ってもらい、徐々に広げるやり方が割と一般的です。このケースでもそうしたのですが、一部で始めるということはなかなかデータが蓄積されないということで、これも考慮に入れておく必要があると思います。
千葉 一方で副次的な効果もありました。前述したテンプレートの標準化と転記のタイプミス減少です。進めていく中で、これら以外にも現行業務の問題点がかなり洗い出されたと考えています。とはいえ問題点が見つかってもそれが自然に変わることはありません。どこかで強制的に改革するタイミングが今後出てくるのだろうなと思っています。そういうことも最初から視野に入れておくほうがよいでしょう。
DOORS 最後にまとめとして、今までの振り返りと今後の展望を聞かせてください。
中村 紹介したケースを始めてから、既に3年ぐらいになります。始めた当時は機械学習モデルを業務に組み込もうという会社はほとんどなく、MLOpsという考え方も全然普及していませんでした。データ分析の結果を経営ダッシュボードにレポートするというケースは既にいくつもありましたが、AIを現場の業務に組み込むケースはあまりなかったのです。
その後いくつかのケースを経て、機械学習が現場の業務で使えるケースと使えないケースがだんだんわかってきました。こうした知見を参考にして、MLOps自体に取り組むのかどうかを判断することがまず必要だと思います。
その上で取り組むにしても、先ほども申しましたが、目標を限定しないほうがよいでしょう。作業時間短縮だけでなく、ミスを減らすとか、属人性を排するとか、複数の目標を掲げたほうがよいのです。そうしないとなかなか進みませんし、失敗とみなされて途中で打ち切られることも多くなるでしょう。
千葉 このケースに関しては、ゼロからスクラッチで作り始めており、パッケージやSaaSと比べると費用がかかっています。したがって現状の効果ではROIという観点では見合っていないのが正直なところです。実を言うと当初はうまくいったら外販しようという話もあったのですが、それは現状では難しいかなと思います。
それでも汎用化できる部分はできるだけ横展開しようとは考えています。いずれにしても目標を複数持つ他に、外販や汎用部品の横展開といったストーリーを企画段階から考えておかないと、MLOpsの対象になるようなシステムのROIを向上するのは難しいと思われます。
DOORS どういうシステムならMLOpsに向くのでしょうか。
千葉 異常検知、配送最適化など完全自動化がある程度目指せるケースでないと今のところ難しいでしょう。逆に予測系で人の感覚がとても重要になるといったケースには向かないことも多いかと思います。
今回のケースのように国際的な規格があると自動化も簡単と思いがちですが、実際にはカスタマイズが必要な部分が多かったわけです。始める前にカスタマイズが少なくて済むかどうか確認し、少ないケースで取り組むほうがよいと思います。少なくともスクラッチ開発でたくさんのカスタマイズをするのは予算的には苦しいことになります。先ほどのパッケージ化の話と関連しますが、個社でスクラッチ開発するのは割に合いません。複数の会社で汎用的に使えるパッケージ化ができそうかどうかが、MLOpsに向くかどうかの1つの判断基準になるでしょう。
中村 AIを入れることで、業務がワンクッション増えるとなかなか難しいと言えそうです。今回のケースでいえば、今までは転記して終わりだった仕事に、AIを入れたことでその転記内容を確認する業務が増えたことになります。現行業務と新業務のプロセスをよく比較して確認することも大切です。機械学習の精度が100%になることはあり得ず、90%でも99%でも99.9%でも確認が入るのは同じです。業務によって精度による影響度も違うので、それも踏まえて、しっかり業務設計することが大事です。
DOORS ビジネスとしての展望はどうですか。
千葉 これからだと思います。MLOpsと呼べるようなケースがようやく出てきたように感じています。ユーザーの業務もシステム運用も可能な限り自動化することが目標になりますが、現時点ではどこが自動化できるのか洗い出すことが重要という段階です。洗い出しには経験値が必要で、私たちもまだ経験を積んでいるところです。お客様に対して、「これはかなり自動化できそうですね」とか、逆に「どうしても現段階では人手がけっこうかかりますね」といった見積もりを出せる程度の知見は蓄積できました。意外とここまで到達しているベンダーは少ないのではないかと、お客様からの引き合い状況から想像しています。
DOORS ニーズはありそうなので、技術的にも高めていきたいと考えているところでしょうか。
千葉 技術というよりは、現状では現場ユーザーにも保守・運用担当者にも工数がかかっているので、それらを減らすためにどうすればよいかがポイントだと思っています。それ以外にも副次的な要因が多く、それらをクリアしていかないとビジネス適用は難しいでしょう。
4、5年前に流行したモデルの効果を実証するためのPoCではなく、人の作業も含めた運用面での実証実験がまだ必要な段階だと考えます。実証実験といっても実際に運用しながら進めていくという意味です。MLOpsの対象になるようなシステムは、従来情報システム部門が中心になって導入してきた業務システムとは違って、「いつから受け入れテストが開始できますか?」といった問いに答えることができません。運用即テストであり、実際の運用から得られたフィードバックを受けて改善することの繰り返しになります。
ですからローンチしてすぐに完璧な実務ができるという考え方でなく、効果が出るまでは実験を繰り返すことに近いと考えるほうが、長い目で見ると良い結果をもたらす――そういう考え方で取り組むほうが最終的に得るものが大きいと思います。
とはいうものの、先ほども言いましたが、少ない学習データでも効果的な学習ができる手法も出てきています。またMLOpsの運用に載せやすい機械学習の方式も出てきています。こうしたものも実際に利用しながら、さらに知見を深めていくのが当面の活動目標です。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













