



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

データサイエンティストの魚井です。
これまでは、汎用ソルバーの進化とそれによりどういった現実問題が解けるようになったかという分析技術の話をしてきました。(前回までの記事はこちら)
しかし、いくら難しい問題が解けるようになったといっても、それによって利益が生まれるかは別の問題です。実業務を行っている方々が、数理最適化によって業務改善されたという感覚を得ていただくこと、また経営層が、その活用によって利益率が上がったと実感していただくことが重要だと思います。それは数理最適化に限らず、機械学習やデータ可視化といったあらゆるデータ分析プロジェクトにおいて重要な視点です。さらに、昨今はこれを如何に上手くやるか、すなわちコストをかけずに達成するかが非常にノウハウ化されているとも言えます。
しかし、こういったノウハウは世間的に注目されているでしょうか?
ディープラーニング、量子コンピュータといった華やかな技術ワードばかりが取り上げられ、実務利用の観点が抜け落ちてはいないでしょうか?
実際に、実務現場で分析技術に莫大な投資をしたにも関わらず、結果が使われていないという事実が多く存在します。この原因として、モデルを現場に”装着するノウハウ”が重要であるという点を多くの人が見逃していたように思います。特に、5、6年前のAIブーム時代は、データ分析に対する過度な期待からか、
データサイエンティストが開発したモデル = 操作画面付きの業務アプリケーション
と飛躍して、捉えられることがありました。噓のように思われるかもしれませんが、一般の方々にモデルというものに具体的なイメージがつかないこともあり、こういった飛躍が起きていたように思います。
「モデル」について簡単に説明させてください。モデルとは入力データを出力データに変換するだけの数値の置き換え機能です。具体的には「10、 20、 30 → 0.5」というように数値を変換するだけです。この機能をいくら複雑に作りこんだとしても、それが直接的に業務改善になるはずがありません。業務に使うには、入力データを一般ユーザーにどう入力させて、出力データをどう見せるか、そしてそれをどのタイミングで行うかといったデータの背景にある業務理解が不可欠です。
一般論として、データサイエンティストは前者(モデル作成)は得意ですが、後者(業務アプリケーション構築)は不得意な職種です。
しかし、実務現場で重要なのは(皮肉にも)後者です。いくら複雑で精度が高いモデルを作れたとしても、それが実務につながっていないのなら、それはプロジェクトの成功と言えないでしょう。
このギャップを埋めるために、様々な工夫が行われてきました。私の観測する範囲では、大きく以下の2極化が起きていたように思います。
1. 数億円の投資をしてウォーターフォール型のSIとして、エンジニアを複数名アサインして業務アプリケーションを構築する方法。
2. データサイエンティストが書いたプログラムを現場担当者に渡し、担当者にプログラムの実行方法を覚えていただく方法。
私の意見ですが、これら両方とも正解とは言えないように思います。1は開発費用と時間が莫大にかかり、現場に適用するまでの時間が長すぎますし、費用対効果が良いとも言えません。また、後者は費用こそかかりませんが、業務担当者がデータサイエンティストのプログラムコードを受け取って理解し、操作を習得できるわけがありません。そこで、最近は多くのお客様から、
3. 簡単な画面で良いから、クイックにまずは現場で使えるものをいち早く
という声を聞くようになりました。ある種の必然とも言えます。本記事の後半では、私が実際に推進した、最小限のコストで現場活用に達するための3つ目の方法、「ダッシュボード開発」について、その背景と必要性を述べ、実際に私がプロジェクトでどのようなステップを踏んで進めたかを解説したいと思います。


もう一度、なぜ分析技術が実務適用されないか、その重要な背景を1つ紹介させてください。それは、データ分析プロジェクトにおけるPOC(概念実証)の進め方に大きな落とし穴があると私は考えています。
POCとは、研究的にモデル開発をし、データ活用の取り組みが収益を生むかどうかを検証するプロジェクトで、データ分析プロジェクトの最初期に行われます。その結果を経営層といった上位層に報告し、本格活用の意思決定を行います。この取り組み自体は良いのですが、私が危惧しているのは、POC終了時点での成果物がパワーポイントの報告資料であることが大半だという点です。これにより、多くの関係者の誤解を生みます。
具体例として、ユーザーの行動データを活用し、ユーザーの優良顧客予測を行うPOCを行った状況を考えさせてください。ユーザーに対して、優良顧客度合い(スコアリング)を算出し、その数値を元に施策を行えば、年間で数千万円のコストインパクトがあると試算できたとしましょう。
POCフェーズの締めとして、経営陣や部長陣といった決裁権を持つ方々に対してこのようなプレゼンテーションを行いました。経営陣はROIが十分であることを感じ、無事プロジェクトの継続の意思決定がされました。
しかし、ここで大きな落とし穴があります。
聞き手(経営層)はこの時点ですでに業務アプリケーションのようなものが出来上がっていて、それを操作した結果を見せられていると思われるケースが多いのです。特に経営層といった上位層の方々ほど、「これでうちにAIが入った」と満足に浸ってしまいます。実態としてPOCフェーズ終了時に実態としてあるものは、データサイエンティストの雑多なプログラムであり、業務担当者がそれを操作できるものには、到底なっていません。
プレゼンテーションする側も、経営層から良い評価を受けてその場を終わりたいわけですから、雑多なプログラムが出来ただけで、現場に適用できるものは到底できていないということを、わざわざ言うメリットがありません。多くの決裁者はROI試算が載ったプレゼンテーション(=パワーポイントの資料)だけで満足してしまうのです。また、決裁者だけでなく、データサイエンティストもこの時点で自らの職務を果たしたと満足する者も多いです。すなわち、自分が作成したプログラムをどこか別の部署かシステムベンダーに渡して、あとは好きに作ってもらえば良いと考えます。
こういったPOCプロジェクトの報告資料だけを見て、一見AI導入が成功したように見えてしまうことが、モデルが現場に装着されない、リアルな実態だと私は考えます。
それでは、空想ではない真のROIを実現するにはどうすれば良いのでしょうか?
ここからはより具体的な技術要素を交えて解説していきたいと思います。
まず、ウォーターフォール開発から考えたいと思います。ウォーターフォール開発はコストが膨大となり、試算した利益が遠のいてしまう可能性が高くなります。
現代のアプリケーションは運用方法や装着方法、継続性から考えてSaas型、いわゆるWebアプリケーションです。従来の方法でWebアプリケーションをウォーターフォール開発として作るには、まず多くの職種の人材、あるいはこれらを兼ね揃えた「フルスタックエンジニア」が必要です。例を挙げると、以下のようなチーム構成になります。
これらの職能もそれぞれ1人ではなく、場合によって複数必要な場合もあるでしょう。このような人材を用意し、何カ月、あるいは何カ年で完成させることが良い選択肢なのでしょうか。果たしてそのための人件費やクラウド費用やデータベース費用といった設備投資はいくらになるのでしょうか。さらに拍車をかけるのが、ウォーターフォール開発とは設計書があって初めて成立します。POCが終わった時点では、システム設計書は一切ありませんし、モデルというのは、変数をアップデートしながら改善していくものですので、要件は刻々と変化していきます。
また、POCではデータサイエンティスト自身がプロジェクトを先導していましたが、ウォーターフォール開発の中では、データサイエンティストは一つの部品でしかありません。さらには要件が変わっていくモデル開発パートはウォーターフォール開発の中では、面倒な要素でしかありません。さらに、これら人々が連携しないといけないため、具体的に動くものが見えるまで非常に時間がかかります。
では次にプログラムをそのまま現場の方に渡して、実行方法をレクチャーする選択肢について考えてみましょう。コストはかかりませんが、現場の実担当者に、pythonの実行環境を立ち上げ、コンソールからpythonプログラムを実行していただくようにすんなりと、レクチャーできるでしょうか?
簡単に思えるかもしれませんがこの方法もハードルが高いです。例えばパラメータを変えて実行したい場合に、エンドユーザーがpythonのスクリプトを開いて、パラメータを編集できるでしょうか?さらには、実行環境は、ノートPCでいけるのでしょうか?機械学習や数理最適化は多くのメモリが必要なため、サーバーで実行する必要があるケースが大半です。そうなると、Webアプリケーションを構築する必要がありますが、ウォーターフォール開発ほどのコストはかけられません。
この2つの方法を打破するために、データサイエンティストに簡単なものを作ってもらえないかという話は以前からありました。しかし、データサイエンティストの大半がモデル開発は行えるが、アプリケーションに対して十分な知識と技術を持ち合わせていません。Webフレームワークと呼ばれるpythonを使い、Webアプリケーションを作るためのライブラリは昔から存在したのですが、データサイエンティストが扱えるものではなく、エンジニア向けでした。エンジニアもデータサイエンティストも同じpythonを使うのですが、これらの職種で目的が大きくことなるため、データサイエンティストがWebフレームワークを覚えることにはとても高いハードルがありました。さらに、Webフレームワークを覚えれば、Webアプリケーションを作れるようになれるのかと思いきや、それ以外にも、フロントエンド、クラウドといった分野の知識も必要です。意外に思うかもしれませんが、Web上で、たった一つのボタンを作り、それを押して結果が表示されるアプリケーションを作ることでさえ、大半のデータサイエンティストはできなかったのです。ここが世間の期待と大きなギャップを生んでいる要因の1つだと私は考えます。
ここからは、タイトルにもある通り、新しい現場活用方法であるアプリケーション開発の新しい手法、「ダッシュボード開発」について説明します。ダッシュボード自体は、これまでも伝統的なBIツールを用いることで誰でも作成することはできました。しかし、伝統的なBIツールには致命的な欠陥がありました。それはBIツール上にpython環境がないことです。
BIツールは、Web上に多くの可視化されたグラフを並べることができ、該当するURLを展開することによってクイックに結果を共有できます。しかし、BIツールを使うユーザーはマーケターのようないわゆるコードが書けない職種の人らを対象にしたツールでした。これが意味することは、簡単な集計可視化しかできないこと、すなわち、データサイエンティストが構築したモデルの実行環境にはなり得ないため、モデルの結果を展開することができませんでした。モデルの実行環境と、BIツールの環境は別に構築する必要があり、これは先に述べたSIに近い形になります。BIツールによって結果を共有することは簡単なのですが、データサイエンティストが作成したモデルの結果は渡すことができず、惜しいところに手が届いていないと感じていました。
こういった、一般ユーザーとデータサイエンティストのモデルの結果受け渡しの実現について、それに答えるツールがここ数年いくつか登場しました。ツールの機能を一言で表現するのは難しいのですが、あえてまとめるとデータサイエンティスト向けWebフレームワークの登場とBI機能の融合です。
これにより、データサイエンティストでも簡単にボタンやフォームといったインターフェースの作成とモデルの構築をツール上でできるようになり、ダッシュボードを展開でき、現場担当者にWebのURLを送るだけで結果の共有ができるようになりました。これは、非常に画期的な進化だと思いました。これにより、従来のアプリケーション開発の常識自体が、根本的に変わっていくような空気さえ感じます。データサイエンティストの複雑な分析の結果を直接的にエンドユーザーに渡すことができるようになりました。そこには、集計可視化、機械学習、数理最適化と技術を問わず可能です。データサイエンティストのプログラムコードが直接的にビジネス貢献できるとても良い時代が来たと思っています。
ここでは、実際にデータサイエンティストの私が材料探索の最適化プロジェクトで上記ダッシュボード開発を行い、フルスタックエンジニアの支援も、大規模SI開発も一切行わず、実務現場にモデルの結果を装着した例とその進め方を解説します。
※材料探索のプロジェクトの進め方や具体的な分析手法はこちらにまとめてあります。
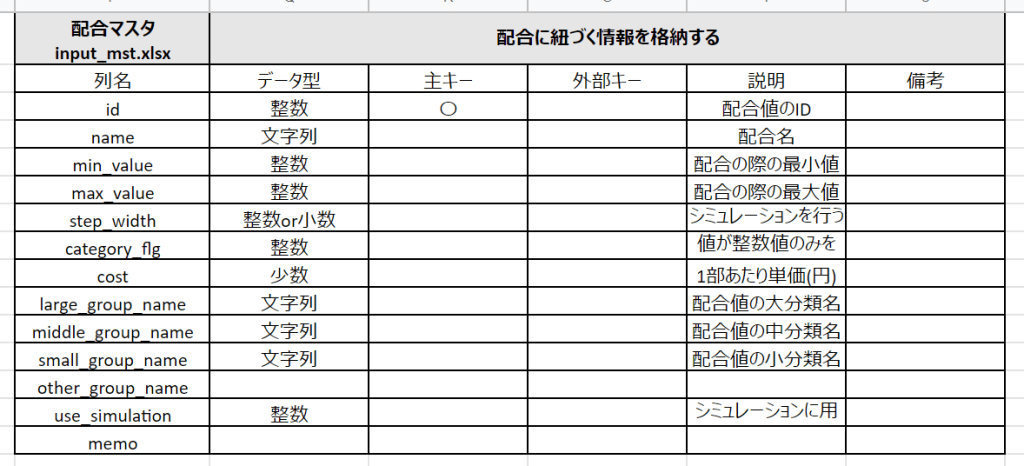
まずは、データの定義書を決めます。すなわちどういった項目をアプリケーションのインプットとするかです。これには慣れが必要ですが、大切なことは、基幹システムとアプリケーションの入力データ形式を一致させないことです。基幹システムの多くは正規化が多く施されているため、人間にとって非常にわかりづらい形式になっています。そこで、人間が理解できるような観測データ形式のフォーマットをデザインし、それをアプリケーションの入力データとします。
さらにポイントが、このアプリケーションへの入力段階では、機械学習用の特徴量を作らないことです。業務の担当者に負荷がかからない形で、データを整備することが使いやすくなるコツと言えます。
そして、次に、ボタンを押しても何も反応しない画面(モック)を作ります。これはあくまでディスカッション用であって、完成形ではありません。これをプロジェクト開始時に作成します。これによって顧客がこれを使って業務をするというイメージを先に持っていただきます。そこで、足りない点に対してフィードバックをいただきます。
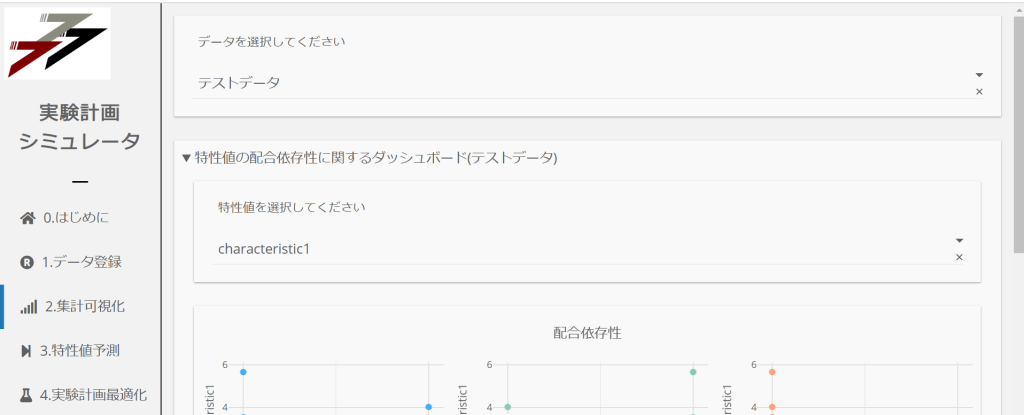
次は、データサイエンティストお得意のモデル開発です。入力データの形式に沿って、自由にコードを書きます。そしてそのスクリプトを画面のボタンをトリガーに実行できるようにします。伝統的なアプリケーション開発では、こういった処理をする際に、APIサーバーを経由して行いますが、その必要はありません。APIを用いずともWebアプリケーションを作れることが、新しいwebフレームワークの大きな特徴と言えます。また、リリースタイミングも1次リリース、2次リリースといったようにSI工程を意識したような進め方はしません。ツールがアップデートしたタイミングでいつでもリリースします。事実、毎日リリースしていました。POCフェーズのため、細かいデザインには、注力せず、結果の出力機能をスピードを優先して取り組むことが大切だと思います。
POC終了時の上位層向けの報告ですが、報告資料だけでなく、その場でアプリケーションを操作し、結果が出力されることを実演しました。経営層向け報告は紙の資料で十分と述べましたが、それは単に発注側から、そのような形式の報告しか経験していないだけかもしれません。経営層とはいえ、実際にデモンストレーションを行うことでより興味を持っていただけたようにも思います。もちろん、アプリケーションは完成ではなく、まだまだ改善を続けているのですが、今現在でも実際に使われており、経営層と現場層の両者にとって有益となるプロジェクトを達成できたと感じています。私自身、今後も重要な分析報告において、紙の資料だけでプレゼンテーションするのではなく、デモンストレーションを交えて再現性のある報告をしたいと思っています。
いかがでしたでしょうか?本記事では、データサイエンティストがモデルを開発しても、それが現場で使われるためには様々なノウハウが必要という話から始め、POCプロジェクトのアウトプットが紙の資料でしかないため、周囲の誤解を生むこと、さらに、その先に進むために、ウォーターフォール開発とプログラム納品という両極端な手法の2極化があることを紹介しました。それらの欠点を解決するべく、第3の打ち手としてダッシュボードによりデータサイエンティストのスキルセットで、短期間でモデルを現場適用する方法について解説しました。データサイエンティストが実務に直接貢献できる良い時代が来たように感じています。ただ、もちろんこれがベストプラクティスで、全ての開発をこれで行えば良いというわけではありません。特に基幹システムと連携し、数百万人が利用するようなミッションクリティカルな開発の場合は、この手段では耐えられないようにも思います。ただ、それもウォーターフォール開発として1から作り直すのではなく、ダッシュボード開発の延長線上に実現し得ないか検討中です。この領域に到達してはじめてフルスタックエンジニアと連携し、SI工程に進むのが良いと思います。これまでのソフトウェア開発の常識に捉われない、柔軟な発想を持ったプロジェクトリーダーが求められています。
また、ダッシュボードはいわゆるテストが全て通った検証済みのシステムではないため、外注する場合には、それによる契約形態の整備といった法的な整備も必要なようにも思います。この記事が、DX推進が机上のシミュレーションとプレゼンテーションだけで終わり、現場に接続されないことに対してお悩みの方々、あるいはそもそもどうのように進めるべきかお悩みの方々の一助となれば幸いです。
私は、データサイエンティストとしてキャリアをスタートしましたが、データサイエンティストは時代の流れとともに、評価が非常に揺らいでいる職種と言えます。
日本全土にモデルの現場装着が進み、データサイエンティストがプレゼンテーションのレポート屋でもなく、ウォーターフォール開発の部品でもなく、データサイエンティストのアウトプットが直接的にビジネス貢献できる時代を作っていきたいと思っています。
これからもこういったリアルな実態と、改善の工夫をお伝えしていきたいと思います。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













