



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

某総合商社の「食品サプライチェーンDXプロジェクト」でプロジェクトマネージャーを務める、データサイエンティストの原真一郎です。
私は現在、総合商社のグループ会社である食品卸企業における「DXプロジェクト」の一環として、出荷先から来る需要の予測をベースとした、メーカーへの自動発注システムを開発しています。
本記事では、自動発注システムの根幹をなす需要予測とはどういうものか、それを利用することで、どう業務改革につなげるのか、そして川中である食品卸企業が需要予測に取り組むことで、サプライチェーン全体にどのようなメリットがあるのかについて述べていきたいと思います。
【需要予測、サプライチェーンDXの関連記事】
【前編】DXに必要なのはデータを「蒸留」させるプロセス~巨大流通企業の「サプライチェーンDX」を成功に導く勘所~
「2024年問題」で日本の物流になにが起きるのか、より深く知りたい方はこちらもご覧ください。
運送業界の「2024年問題」とは?業界の現状から考える解決法


まず初めに、需要予測とは何かを簡単に説明します。
需要予測は、一言でいえば「製品やサービスが、将来どのくらい利用されるかを予測すること」です。過去の販売データなどから製品やサービスの利用傾向を把握し、現在の状況を踏まえて未来の需要を予測する技術です。
需要予測でよく使われる分析手法は、大きく分けると2種類存在します。
1つは統計モデルで、線形回帰、ロジスティック回帰、階層ベイズモデルなどのアルゴリズムを使用する、確率分布をベースとしたモデルです。
もう1つが機械学習モデルで、ランダムフォレスト、決定木、サポートベクターマシンなどのアルゴリズムが使われます。最近では、ディープラーニングも使われるようになりました。これらの分析手法は、それぞれ利用されるシチュエーションが異なります。
過去データが少ない場合は、「統計モデル」が採用されます。また統計モデルは解釈性に優れているため、どんな要素が結果に大きく影響しているのかを明確に説明したい時にも使われます。一方で、仮定した確率分布に精度が左右されるという欠点があります。
過去データが多く取得できる場合は、「機械学習モデル」が用いられます。機械学習モデルは、より複雑な状況に対して高い精度を出すことができます。ただ解釈性が低いモデルになりがちなので、どのデータが結果に影響を与えているのかを明確に説明できないことが多いです。
統計モデルにも機械学習モデルにもそれぞれメリット・デメリットがあるため、どちらを採用するかはケースバイケースです。ただサプライチェーンに関わる需要予測の場合は、データを大量に持っている企業が取り組むケースが多く、また精度が高いほど業務へのインパクト(効果)が大きいため、機械学習モデルが主流になってきています。
私が担当する食品卸企業のDXプロジェクトでは、メーカーへの自動発注システムを開発していると先に述べました。では自動発注システムにおいて、需要予測は具体的にどう利用されているのでしょうか。
需要予測の利用ポイント1つ目は、そのものずばり、「メーカーへの発注量を決める」ためです。
卸企業は、配送先である小売業者から受注があった際にすぐ配送できるよう、予めメーカーから商品を仕入れ、在庫を蓄えておく必要があります。そのため、小売業者から将来どの程度の受注が来るのかを予測し、メーカーへの発注量に反映しています。
発注量の具体的な算出方法を説明する前に、考慮しなければならない要素を2つ紹介しましょう。
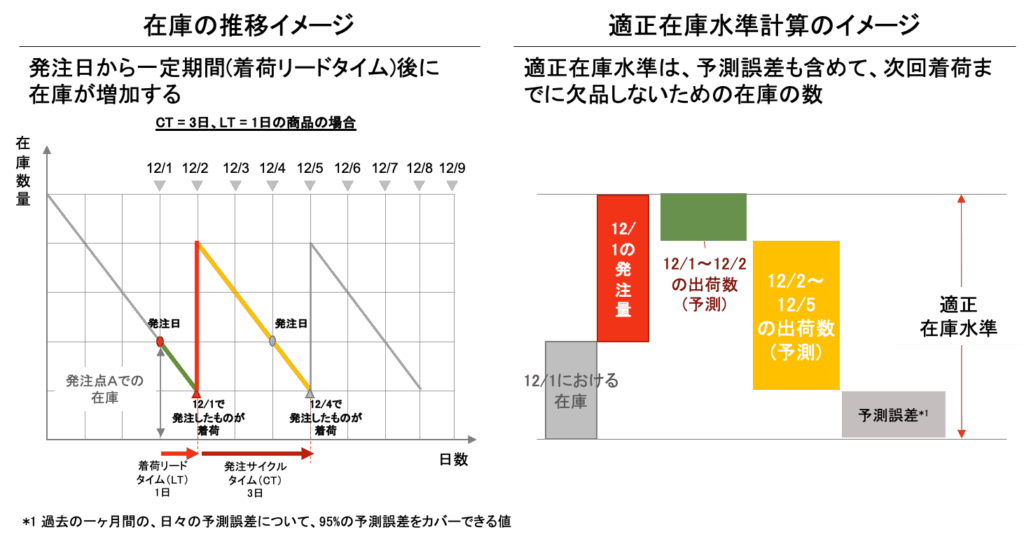
1つめはリードタイム(LT)で、発注してから入荷するまでの日数を表します。
例えば、ある商品Aは、メーカー側で配送準備をするのに1日必要だとします。すると、発注してから入荷するまでに1日かかり、LT=1となります。
2つめはサイクルタイム(CT)で、メーカー側で発注を受け付けられるタイミングを表します。
例えば、先ほど出てきた商品Aが、3日おきにしか発注できない場合、CT=3となります。
では商品Aを例に、ある日の発注量を考えてみましょう。商品AのLTは1なので、入荷日は翌日になります。では翌日時点でどの程度の在庫を確保する必要があるでしょうか。それは、“次回発注分が入荷するまでに必要とされる量”となります。次回発注日はCT=3なので3日後、その入荷がLT=1日後なので、LT+CT=4日後となります。よって、発注するべきは、今日から4日先までに小売業者から受注する総量となります。
この未来の受注量を正確に予測することは、在庫量の最適化および欠品の抑制を実現する上で重要です。これまでは、需要予測値を「過去平均の4日分」というように平均を使った日数基準で出していましたが、私たちは機械学習モデルを作成し、日々の予測値をより正確に算出することに成功しました。
需要予測の利用ポイント2つ目は、「安全在庫の計算」です。
安全在庫とは、予想外の受注が発生しても対応できるよう、多めに積んでおく在庫のことです。予測のブレを吸収するための余剰在庫です。
安全在庫を多く確保すれば欠品する確率は下がりますが、在庫量は当然多くなります。安全在庫を減らすと在庫削減に繋がりますが、欠品率が高くなる可能性があります。
このように、在庫量の削減と欠品率の低下はトレードオフの関係にあるため、両方のバランスが取れた安全在庫量を見つけだすことが、卸業者の売上増加とコスト削減に直結します。しかし適切な安全在庫量を計算することは至難の業です。
そこで私たちは、適正な安全在庫量を求めるために、需要予測モデルが算出した受注予測値と受注実績値との誤差を算出し、その95%をカバーできる量を当てることにしました。
これまで、担当者の経験と勘に基づいてなされてきた発注を、機械学習モデルによる精度の高い受注予測値を用いて精緻化することで、欠品を実績と同等レベルに抑えながら、在庫を最大30%減らすことに成功しました。また、発注業務を自動化することで、工数を約半分に削減することもできました。
需要予測を利用することで、自動化・省力化による生産性向上という、DXが目指す世界を実現できたのです。
後編では、機械学習による需要予測モデル作りについて解説します。
この記事の続きはこちら
【後編】川中での「需要予測」が川上・川下にもメリットをもたらす時代が目前に!
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













