

メルマガ登録
ベストなDXへの入り口が見つかるメディア


-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
ベストなDXへの入り口が見つかるメディア
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

昨今、ChatGPTに代表される生成AI・LLM( Large Language Model:大規模言語モデル)が世界的なブレイクスルーを起こしつつあります。しかし、使い方を一歩間違えると、情報漏洩や著作権侵害、プライバシー侵害などのリスクをはらんでいます。
【関連】
そこで、本記事では実際にブレインパッド社内において、生成AI・LLMを安全かつ効果的に活用するために実施した、社内ガイドライン策定におけるプロセスとポイントを解説します。
本記事が、読者のみなさまが所属されている企業・組織、あるいは特定業務への生成AIサービスの導入、または、その利用手順についてのガイドライン策定の一助となれば幸いです。

株式会社ブレインパッド アナリティクス本部 アナリティクスサービス部の佐藤光です。現在は、データサイエンティストとして、主にデジタルマーケティング分野の分析支援や、データ利活用の業務設計に携わっています。
22年以降、OpenAI社のChatGPT,Stability AI社のStable Diffusion,Google社のBard等の大規模言語モデル(LLM;Large Language Models)に代表される生成AI(GenAI;Generative AI)が脚光を浴びています。
本稿では、生成AIの大いなるポテンシャルを安全かつ効果的にみなさんのビジネスに取り込んでいただくため、「どのようにガイドラインを策定すればよいのか?」「どのような点に留意すべきか?」に焦点を当て、社内ガイドライン策定時のポイントを解説します。
生成AIサービスでは、自然言語を用いたチャットベースのユーザーインターフェースを介して、AIに対する所望の情報処理をリクエストできます。そして、その出力結果(生成物)は、自然言語のみならず、画像や動画、プログラム・ソースコード等のマルチメディアを網羅しつつあり、私たちの生活や仕事において、利便性・生産性・創造性を大いに高めてくれるポテンシャルを有しています。
このように革新的な側面がある一方で、こちらの連載記事「【連載①】大規模言語モデル(LLM)のビジネス利用に関して注意すべき点-LLMの使用許諾条件- – Platinum Data Blog by BrainPad 」にて紹介した通り、いくつか注意を払う点があります。
例えば、利用者が、個人情報や機密情報を入力してしまうリスクにどのように対処すべきか、他者の著作物を入力/訓練データとして扱っても良いのか、などです。私たち利用者は、個人利用/法人利用であるか、また学習目的/商用目的であるかに関係なく、このような生成AIにはらむリスクを基礎知識として理解し、日頃からリスク感度を高めておく必要があります。
このような背景から、本国においても、あらゆる業界(行政・教育・民間)において、生成AI利用に関するガイドライン策定は急務となっています。同様に、当社においても「生成AIのリスクと、当社独自のポリシーを踏まえたガイドライン」を策定し、運用を開始しています。
【参考】
私たちが、生成AIのポテンシャルを安全かつ効果的に活用するためには、このような法的知識に加え、所属する会社・機関、あるいは従事する業務における独自のポリシーに即した運用が有効となります。そこで、本稿では、当社における「生成AI利用ガイドライン策定」の軌跡を踏まえ、策定プロセスとポイントをご紹介します。
私たちが所属組織において、生成AIのガイドラインを策定する目的は、「生成AIサービス・モデルを、安全かつ効果的に活用するための基礎知識と基本ルールを組織に根付かせること」です。
いかに利便性の高いサービスであっても、提供機能や利用料だけで導入可否を判断してよいわけではありません。生成AIはその性質上、法的リスクのみならず、倫理的リスク、情報セキュリティのリスクをはらんでいます。その為、私たち利用者および、組込み製品・サービスの開発者は、諸リスクを前提知識として理解したうえで、利用することが必要となります。
ChatGPT登場以降、以前にも増して、目まぐるしい勢いで新サービス・モデルがリリースされています。機能・性能をキャッチアップし、検証・応用し続けることは、私たちデータ利活用の専門組織としては、ライフワークともいえるでしょう。
ChatGPTのような生成AIサービスはWebブラウザから個人が容易に利用できてしまうほどに、利便性が高い環境ですが、その反面、潜在的なリスクに対処しなければ、意図せぬ情報漏洩等、不測の事態が発生してしまう恐れもあります。生成AIサービス・モデルの利用規約/プライバシーポリシー/ライセンス等の条文は、サービスごとに異なります。そのため、所属組織がある生成AIサービスを導入していても、同様のポリシー・判断基準で他の生成AIサービスを利用して良いわけではありません。(例えば、組織が「サービスA」を導入していた場合に、Webブラウザから容易に利用できる類似の「サービスB」を同様のポリシーで利用することは、原則認められないでしょう。)
そこで、当社ガイドラインのスコープとしては、「生成AIに関する諸リスクと注意すべき点を明文化すること」「具体的なプラクティス」に加えて、「日々リリースされる新たな生成AIサービス・モデルを研究開発・活用することを想定し、社内ルールとしての判断基準を明文化すること」を目指しました。利用目的や利用情報に応じて、社員個人の裁量で活用できる範囲を明確化しておくことが、継続的な成長を目指す組織には必要であると考えたためです。
当社では、5つのプロセスでガイドラインを策定し、運用を始めています。
なお、ガイドライン策定〜運用においては、利用部門のみならず、法務部門・情報システム部門等の関係者の協力も必要となります。ガイドライン策定プロジェクトを統括される方は、関係各所への協力依頼を仰ぐことも念頭に進めることをお勧めします。
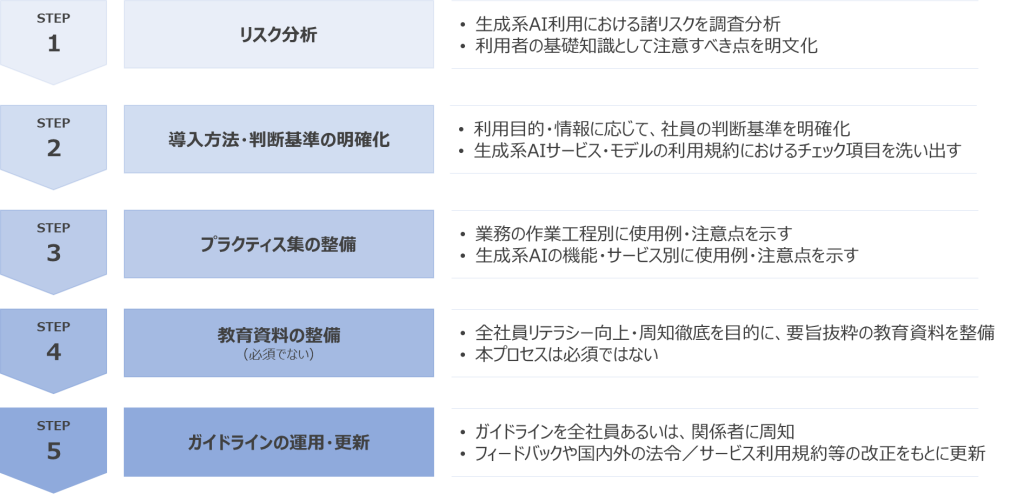
それでは、各プロセスの検討事項を概説します。
このプロセスでは、生成AIの利用時におけるリスクを調査分析し、法的罰則やブランド毀損等の損害を発生させないように、注意すべき点を基礎知識として明文化します。生成AIの利用者のみならず、生成AIを組み込んだサービス・製品を開発する開発者にとっても、生成AIにおけるリスクや留意点を理解しておくことは肝要です。
このプロセスでは、社内における生成AIサービスの導入ルール・判断基準を明確化します。生成AIのモデルや、それを組み込んだサービスは、今や同時多発的にリリースされており、Webブラウザ経由で「気軽に試せてしまう」状態となっています。そこで「どのような目的」「どのような情報」であれば、社員個人の判断に委ねて利用できるのか、あるいは、組織的判断が必要になるのか、という点を明確化しておくことは、情報セキュリティの確保及び内部統制の観点だけでなく、「成長し続ける・機動力を高めるための仕組み化」という側面からも重要です。
また、その際に、社員個人でもリスクを洗い出せるように、生成AIサービス・モデルの機能・利用規約からチェックすべき項目を洗い出すためのツール作り(利用判断を手助けするための各資料)も重要な対策です。
このプロセスでは、生成AIを業務利用するケースを想定し、より実践的な利用方法・具体例を示します。プラクティス開発は、主に2種類の進め方が考えられます。
(1)業務作業起点のプラクティス開発:業務の作業工程別に使用例・注意点を示す
(2)サービス起点のプラクティス開発:生成AIの機能・サービス別に使用例・注意点を示す
実際の業務をイメージしながら、あるいは、利用する生成AIのサービス・機能を理解しながら、代表的な使用例、その際の注意点などを、プラクティスとしてまとめていきます。業務利用における全てのケースを洗い出すことは困難であると想定されるため、利用頻度や発生リスクが高いと想定されるユースケース/シナリオから検討することを推奨します。
このプロセスでは、主に「生成AIサービス利用時のリスク」に焦点を当てて教育資料を整備します。このプロセスは必須ではありません。例えば、「1.生成AIサービスのリスク分析」で整理した情報に図解を加えることで、視覚的にも理解しやすい資料となり、全社員のリテラシー向上に役立てることができます。
このプロセスでは、作成した「ガイドライン」「教育資料」を基に、全社員に周知を行います。同時に、ガイドラインとしての磨きをかけていくために、生成AIサービスの利用者からのフィードバックをもとにアップデートしていくことも重要となるでしょう。
また、国内外の法令規制の改正の動き、利用しているサービス・モデルの利用規約等の改訂についてもキャッチアップし、ガイドラインとして情報の鮮度を高めておく必要があります。
本章では、先述したプロセスのうち、主要な3つのプロセスにおけるポイントを解説します。
生成AIサービスの利用者(生成AIを活用した製品・サービスを開発する者も含む)は、どのような法的・倫理的・情報セキュリティ的なリスクをはらんでいるのか、基礎知識を理解することが求められます。
生成AIから出力された情報は、あくまでも予測された情報であり、必ずしも正しい情報とは限りません。また、生成AIサービスは、利用者からのフィードバックをリアルタイムに収集する機能を備えていることもあるため、機密情報や個人情報を不用意に入力すると、意図せずに第三者へ情報漏洩してしまうリスクもはらんでいます。
生成AIが抱える代表的なリスクとしては、以下のような観点が挙げられます。
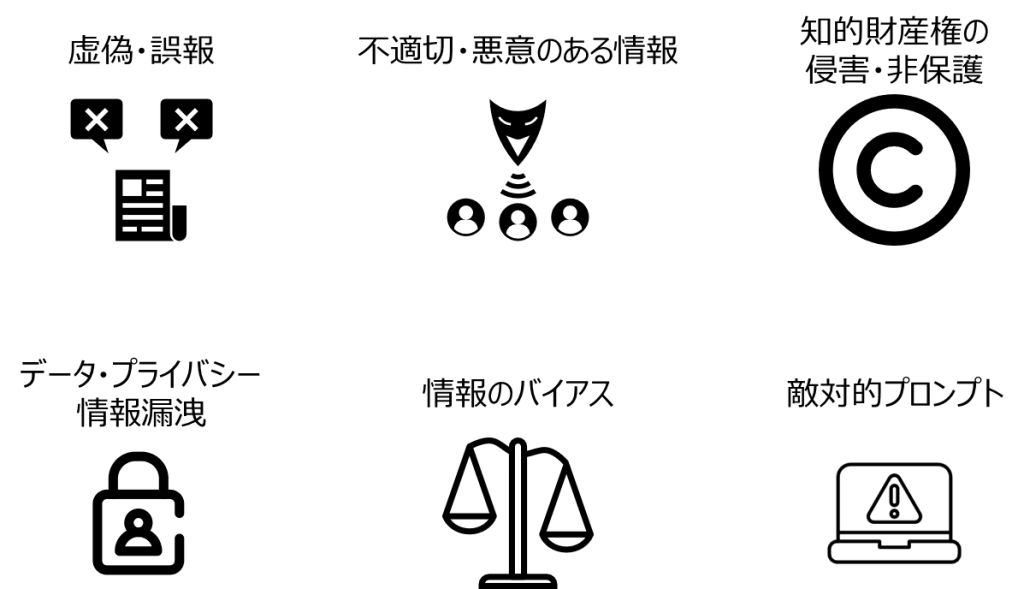
上記を含め、代表的なリスクに関する知識・法的解釈は、下記リンクも参考にしていただくことをお勧めします。
【参考】
なお、補足情報として、上記リスクへの技術的対応策について興味を持たれた方は、こちらの記事も参考にしてください。
【参考】
大前提として、生成AIを問わず、各種サービス・モデルを導入利用する際の基本原則(禁止事項)は、次の3種に集約されると考えられます。
ガイドラインでは、基本原則を前提に、「安全」かつ「効果的」に利用するための判断基準を明文化する必要があります。しかし、実際には、私たちのビジネス・業務形態は多岐にわたる為、全てのユースケースに対して、ゼロイチで判断を下せるような詳細な基準を、即座に用意することは困難です。
そこで、当社では、情報セキュリティの確保及び内部統制の観点はもちろんのこと「成長し続ける・機動力を高めるための仕組み化」を目指して、「個人判断に委ねるライン」「組織判断が必要になるライン」を明確化するために、2つの要素を組み合わせて、判断基準を設定しました。
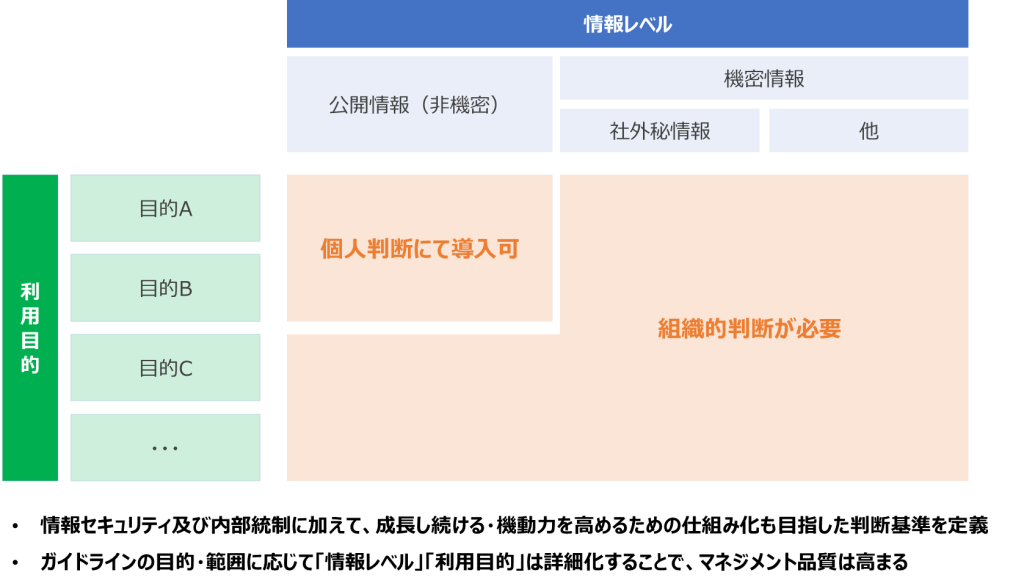
「利用目的」とは、生成AIサービス・モデルをどのような目的で利用するのか、ということです。例えば、技術検証/社内業務の効率化/対外的に公開されるサービスへの組込み等が挙げられます。また、生成物の用途として、社内利用/社外利用といった区分も考えられます。利用目的の区分は、一義的かつ容易に判断が下せるように、できる限り少ない種類で大別することが望ましいと考えられます。機動力と安全性を両立させるためには、大別された区分をもとに迅速に一次判断を下し、組織的判断が必要な要件については関連部署による承認プロセスを通す、という仕組み化が有効と考えられます。
「情報レベル」とは、JIS Q27001 附属書A.8.2に「情報分類」として定義される情報資産の管理策の一つです。情報資産の重要性に応じて、適切な保護レベルを規定します。情報セキュリティマネジメントシステム(ISMS)を運用している組織では、一般的には「公開情報」「機密情報」「社外秘情報」の3つの分類を土台に、独自に情報レベルを定義していることでしょう。そこで、生成AIサービス・モデルにおいても、入力データまたは訓練データとして情報を取り扱うことになる為、情報レベルに照らして判断基準を定める必要があります。
個人あるいは組織として、導入対象となる生成AIサービス・モデル個別の適正及びリスクについては、必ず検証し、必要に応じて承認プロセスを介す必要があります。
生成AIサービス・モデル自体の適正・リスクは、利用規約・ライセンス状況ならびに提供者のプライバシーポリシー等の文書を元に判断することになります。そこで、当社では、利用規約・ライセンスにてチェックすべき観点をまとめ上げ、社員個人が検証できるようにドキュメント・ツールを整備しました。これらの補助材料を用意することで、限定的な目的・情報に限り、社員個人が安全かつプロアクティブに技術検証を進めることが期待されます。
組織的な判断を要するケースにおいては、承認プロセスの整備が必須となります。但し、多くの組織の場合では、既存の承認プロセスに乗せることが、本件への即応性が高くなると考えられます。
例えば、クラウドサービスを利用する際の承認プロセスや、個人情報を取り扱う際の承認プロセスが挙げられます。他にも、所属組織独自の承認プロセスを設けることで、安全かつ効果的に組織導入することができると考えられます。
生成AIを業務利用するケースを想定し、主に2種類の進め方で、より実践的な利用方法・具体例を検討しました。
(1)業務作業起点のプラクティス開発
(2)サービス起点のプラクティス開発
(1)の進め方については、主に「既存業務/サービスの代替手段」に関するプラクティス開発が主要なタスクとなると考えられます。そこで、部門や職種、サービスごとに、日々の業務内容/サービス内容を想定あるいはロールプレイングし、生成AI機能の使用例や注意点を検討します。
以下に例を示します。自組織の業務内容を踏まえ、生成AIの使用例や注意点を明文化し、組織全体のリテラシーを高めておくことが重要となります。

(2)の進め方については、主に「サービス共通または固有のテクニックや機能設定」に関するプラクティス開発が主要なタスクとなると考えられます。生成AIの提供機能に関して、どのようなリクエストの仕方が有効か、どのような機能が扱えるのかを、生成AIサービス・機能の内容を理解し、使用例や注意点を検討します。
(2)については、(1)よりも技術的・発展的な理解や検討が必要と想定されるため、ガイドライン策定の初期段階では深堀しすぎず、実際に生成AIサービスを利用・検証し始めた段階で、ナレッジマネジメントの一環として明文化していくことが有効であると考えられます。また、サービス起点で検討を進めることで、テクノロジードリブンで、新たな活用方法・応用例を見い出す可能性もあると考えられます。
プラクティス開発を進める上では、以下ステップのように、検証工程を挟むなど、リスクを最小限に抑えた体制・範囲で利用開始することを推奨します。
当社では、机上検証はもちろんのこと、実際に各種生成AIサービス・モデルを検証・応用し、プラクティス開発を進めています。当社公式メディアPlatinum Data Blogにて、プラクティス・事例を紹介していますので、こちらもご参考ください。
【関連】
本稿では、生成AIの社内ガイドライン策定におけるプロセスとポイントをまとめました。 生成AIサービス・モデルが日々続々とリリースされる中、安全かつ効果的に組織導入するためには、ガイドラインとして明文化し、組織全体の共通知識とリスク感度を高めることが重要となります。
みなさんの組織全体あるいは特定業務に生成AIサービスを導入したい、あるいは、その利用手順についてガイドラインを策定したい、そういったご要望がありましたらブレインパッドにご相談ください。みなさんが安全かつ効果的に、生成AIを組織導入できるよう、当社の専門部隊がご支援いたします。
最後まで、お読みいただきありがとうございました。
記事・執筆者についてのご意見・ご感想や、お問い合わせについてはこちらから
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













