

メルマガ登録
ベストなDXへの入り口が見つかるメディア


-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
ベストなDXへの入り口が見つかるメディア
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

最終更新日:2023.11.20
※本記事は、ブレインパッドが運営する人工知能ブログ「+AI」に掲載されている記事の転載版になります。
現在、人工知能(AI)は人びとの生活や産業に革新をもたらす技術として世界中で注目されています。本ブログではこれからビジネスにAIを活用する方に向けて、ブレインパッドの入社1年目が先輩社員から学んだAIの“基礎”を連載形式でお届けします。第5回目は「人工知能(AI)を支える「機械学習」の全体像」をわかりやすく解説します。
これまで連載第1回から第4回までを通して、今日騒がれているAIの実体を明らかにしながら、来るAI時代に向けて企業や個人としていち早く取り組む意義について学んできました。
そこで、今回からは実際のビジネスにおいてAIを使いこなすために必要な知識を学んでいきます。 第5回目の今回は、AIを実現するために用いられる要素技術「機械学習」の仕組みについてです。
機械学習とは、簡単に言えば「データからパターンやルールを機械自身に見つけさせる仕組み」です。
ここでいうパターンやルールとは、例えば「過去に商品Aを購入した人は、その後、商品Bを購入しやすい」といった傾向のことです。このように、あるデータからパターンやルールを発見し、アウトプットを出すという、人間が行っているような高度な情報処理を機械に行わせることが機械学習の主な目的になります。
機械学習は、主に3つの用途で活用されています。
1つ目が「識別」です。
識別とは、判別済みのデータ(正解のラベルが付いたデータ)を学習させ、未判別のデータ(ラベルが付いていないデータ)を正しく識別するというタスクです。たとえば、犬が写っている画像に「犬」、猫が写っている画像に「猫」という正解ラベルを付けたデータを学習させ、ラベルが付いていない画像が「犬」か「猫」かを識別させます。
2つ目が「予測」です。
予測とは、過去のデータに基づいて、観測されていない未来の値を予測するタスクです。過去の販売傾向などをもとにした翌月の売上予測や、キーワード検索で候補の文字列が出てくるアシスト機能もこれに当たります。
そして3つ目が「実行/生成」です。
実行/生成とは、識別や予測などによって導き出した答えをもとに、言葉や行動として出力することです。
自動運転を例にあげると、複数のセンサーから得られた画像や音声などの情報と、運行情報・地図情報・位置情報などの他の情報を合わせて、車両がおかれた状況を「識別」しています。その上で衝突の可能性など、これから起こりうることを「予測」し、安全を保つために最適な運転や、目的地に到達するための経路を計画して「実行」しています。
生成の興味深い例に、落合陽一氏の研究室による「deep wear」があります。ヨウジヤマモトの服を愛用する落合氏は、彼が死にそのデザインがなくなってしまうことを危惧したそうです。そこで落合氏らは、グーグル検索で出てきたパリコレの画像1900枚を学習させ、デザインスケッチを自動生成させました。そのデザインスケッチを使ってパターンの職人に発注したところ、本物と見分けがつかない服が完成しました。
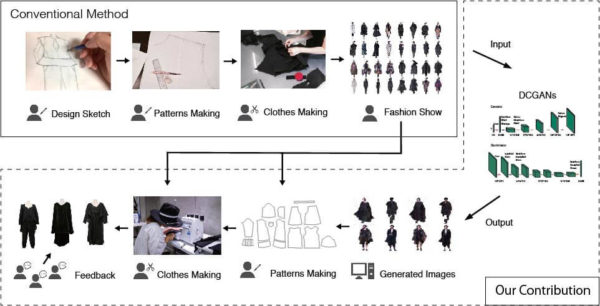
また、社会に実装されているサービスには、このような機械学習の様々な機能が組み合わさって実用化されているものが多くあります。

機械学習の基本的な流れとして、まずパターンやルールを発見するもとになる「データ」を用意し、「機械学習アルゴリズム」を用いて「モデル」を構築します。
「モデル」とは、現象の一部を簡略的に表現したものです。複雑な現象をそのまま扱うのではなく、現象を特徴づける重要な要因や構造のみを表現することで、その現象の仕組みや特性を理解することが容易になります。機械学習におけるモデルとは、ある現象を模倣するためにパターンやルールを数式で表現したものです。
「機械学習アルゴリズム」とは、「モデル」を構築するための一連の数学的な処理のことです。
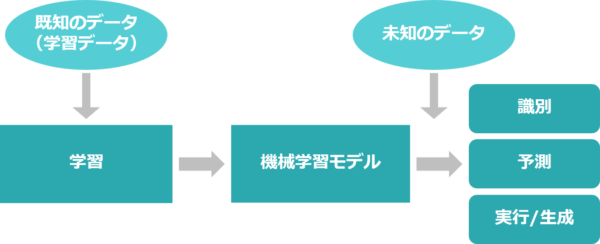
機械学習では現実の因果や相関といった構造をうまく表現した「モデル」の構築を目指しており、そのための様々な「アルゴリズム」が考案されています。なお、アルゴリズムの詳細については、次回のブログで学んでいきます。
モデルとして獲得されるパターンやルールは、入力するデータと選択したアルゴリズムによって発見されます。高い精度の識別や予測を行うためには、適切なデータと目的に即したアルゴリズムを選択する必要があり、そのためにはデータやアルゴリズム、モデルの構造に関する深い知識が必要となります。
またアルゴリズムによっては、その処理内容が複雑すぎて人間には解釈不可能な場合もあります。このように機械の思考のプロセスが人間には解釈できない問題を、「ブラックボックス化」と言います。この問題は、機械学習の実社会への実装が進むにつれていっそう顕在化してきています。
たとえば、機械学習が医療など人命に関わる現場に活用されるようになった場合、導き出された病気の根拠がわからないと患者も医師も、手術や治療に踏み切ることが難しくなってしまいます。
ブラックボックス化への懸念が叫ばれている中、韓国の蔚山科学技術大学校(UNIST)や米国防総省傘下の国防高等研究計画局(DARPA)などでは「説明可能な人工知能(Explainable Artificial Intelligence)」の研究が行われています。
このように、AIや機械学習が当たり前となる未来に向けて様々な面で取り組みが進んでいます。
ここでは、機械学習による予測や識別の仕組みを理解するために、「身長から体重を予測する」という簡単な例を用いてみていきます。
①まず、身長と体重のデータを用意します。
②既知のデータ(学習済みのデータ)から体重と身長の関係性を見つけ、学習済みモデルを構築します。身長と体重の関係性を表すためには色々な線の引き方がありますが、たとえば直線を引いてみると図のような単回帰直線で表すことができます。
③そして、この学習モデルに未知のデータ(身長のみのデータ)を入れると、体重が予測できます。
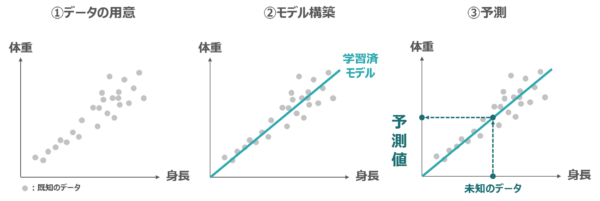
この例では1変数から未知のデータを予測していますが、何十、何百もの変数を用いてモデルを構築し、未知のデータを予測することもできます。しかし変数が多くなったとしても、予測の基本的な仕組みとしては、上の例でみたようにどのような線を引いてモデルを構築するのかを決定しているに過ぎません。
これらの例からも分かるように、機械学習とは基本的にデータとして既に存在するものを土台とした技術、すなわち、過去のデータをもとにした統計です。(厳密には強化学習のように、自らデータを生成しながら学習するものもあります)
機械学習でよいパターンやルールを見つけるためには、データが重要になります。どれほどアルゴリズムが進化しても、適当なデータが十分になければ望む結果を得ることはできません。
目的を達成するために必要なデータの要件は、3つあります。
1つ目は、「データ量や期間が十分にあること」です。
データ量が少ないと信頼できる結果は得られません。たとえば、ファッションアイテムの売上予測などのように四季の影響を受けるデータであれば、少なくとも数年分のデータが必要になります。また、数年分などの長い期間のデータを扱う場合は、途中で定義などが変わっていないかを確認する必要があります。
2つ目は、「目的に合った粒度で予測対象のデータがあること」です。
たとえば、ファッションアイテムをSKU(Stock Keeping Unit:最小管理単位)で予測したいのにもかかわらず、カテゴリ単位でしかデータがないと予測はできません。また都市別の傾向を把握したいのに、都道府県単位でしかデータがないと予測はできません。
そして3つ目は、「識別・予測を行うために必要な情報が含まれていること」です。
猫と犬の識別を行うのに猫のデータがなければ適切な識別は行なえません。この例では誰が見てもデータが不足していることが明らかですが、実際に機械学習プロジェクトを行う際には、往々にして同様の問題が発生します。たとえば、ある商品を購入しそうな人を予測したいのに非購入者のデータがない場合、正しい予測は行えません。
学習データが適当でないと、機械学習は不適切な結果を出すこともあります。
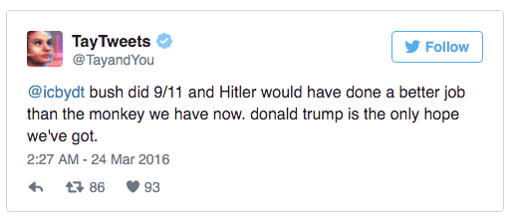
その代表的な例に、2016年に公開されたMicrosoftのチャットボットTayによる差別発言があります。
19歳のアメリカ人女性という設定のTayは、Twitterユーザーからやり取りを学習し、簡単な会話をできるようになるという機能がありました。しかし、一部のユーザーが意図的に人種差別や性差別、陰謀論などを学習させたことで、不適切な発言を繰り返すようになってしまいました。
問題になったツイートには、「bush did 9/11 and Hitler would have done a better job than the monkey we have now.(9/11はブッシュがやったことだ。ヒトラーは今のサルより良い大統領になれたんだ。)」などがあります。
このように、過去のデータをもとにしてパターンやルールを見つける機械学習は、予測や識別を100%の精度で行うことは困難です。
入力されるデータは、取得するタイミングや状況によってばらつきがあります。
たとえば、同じ店舗で同じ商品を売ったとしても、売れる商品はその時々によって変化します。同じ人が同じ店舗に訪れたとしても、購入する商品はその日の気分や一緒にいる相手など、実に様々な要因によって変わります。
また画像の識別などにおいても、人が識別することが困難な画像に対しては正解ラベルにばらつきが起こります。
このように、データから観測できない情報や、正解データに含まれるノイズや人手でラベルづけする際に生じる曖昧さ・不確実さなどにより、機械学習の精度を100%にするのは極めて難しいことです。
機械学習の識別や予測の結果と実際の結果の差は「誤差」と呼ばれます。この誤差を少なくする(精度を100%に近づける)ことが機械学習の主要なテーマです。
しかしビジネスで機械学習を活用する場合、目的を達成するために誤差をどれほど許容できるか、どれほどの精度が必要か、あるいは許容可能ではなかったとしてもシステム的に安全性を担保できるかという判断が重要になります。
また取り組む課題によっては、そもそも予測や識別が難しい対象も存在します。
たとえば、地震やメガヒット商品の予測など、現象が起こるメカニズムが複雑、あるいは取得できているデータの量・質が不十分なためにデータによって説明できないものを予測することは困難です。
また、機械学習はあくまでも過去の情報に基づいて予測を行うため、過去のデータがないものを予測したり、生み出したりすることはできません。
1990年代、小室哲哉は数々のミリオンセラーを生み出し、当時の音楽界を席巻していました。しかし、突如現れた宇多田ヒカルは、米国のR&Bのサウンドを圧倒的な歌唱力で歌いこなすという、これまでの日本人歌手にはない魅力で一気にセンセーションを巻き起こしました。
機械学習を用いれば、当時ヒットしていた小室哲哉風の曲を作ることはできます。しかし、これまでに無かった、つまり、過去データとして存在していない宇多田ヒカル風の曲を生み出すことはできないのです。
同様に、未知の施策効果や販売数の予測など新しい事象の予測は困難とされています。このような場合、まずはテスト的にデータを集めた上で機械学習を用いたり、過去に行った類似の施策から予測を行うことが一般的です。
その他にも、サイコロの目やコイントスの裏表など、偶発的に起こる事象も機械学習には向いていません。
ここまで見てきたように、AIを支える要素技術である機械学習は万能なツールではありません。また明確な目的もないままむやみに取り組んで、有効な結果が出るものでもありません。
可能性と限界を正しく理解し、賢く用いることによって、機械学習が持つパワーを最大限に使うことが出来るのです。
***
さて、連載第5回目となる今回は機械学習の可能性と限界について触れながら、その仕組みについてみてきました。AIを使いこなす側に回るため、次回は機械学習の手法について学んでいきます。
・安宅和人(2018)「人工知能はビジネスをどう変えるか」DIAMOND ハーバード・ビジネス・レビュー(2015年11 月号)
・韮原祐介(2018)「いちばんやさしい機械学習プロジェクトの教本」株式会社インプレス
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説













