メルマガ登録
-
テーマ
から探す -
技術
から探す -
業界・事例
から探す -
関連トレンド
から探す
テーマ
から探す
技術
から探す
業界・事例
から探す
関連トレンド
から探す

みなさんこんにちは。アナリティクスコンサルティングユニットの崎山です。
2022年にChatGPTが登場して以来、LLM(LargeLanguageModels、大規模言語モデル)、およびGenerativeAI(生成AI)に関する技術革新が日々進み、それを取り巻く社会情勢もめまぐるしく変化しています。
これらの技術の社会実装に向けた取り組みや企業への支援を強化するため、ブレインパッドでもLLM/生成AIに関する技術調査プロジェクトが進行しており、最新トレンドの継続的なキャッチアップと情報共有を実施しています。
本連載では、毎週の勉強会で出てくるトピックのうち個人的に面白いなと思った事例・技術・ニュースをピックアップしてご紹介していきます。
※本記事は2024/4/30時点の情報をもとに記載しています
【関連記事】
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

生成AI/LLM技術最新トレンドに関する今回のトピックは、以下のとおりです。
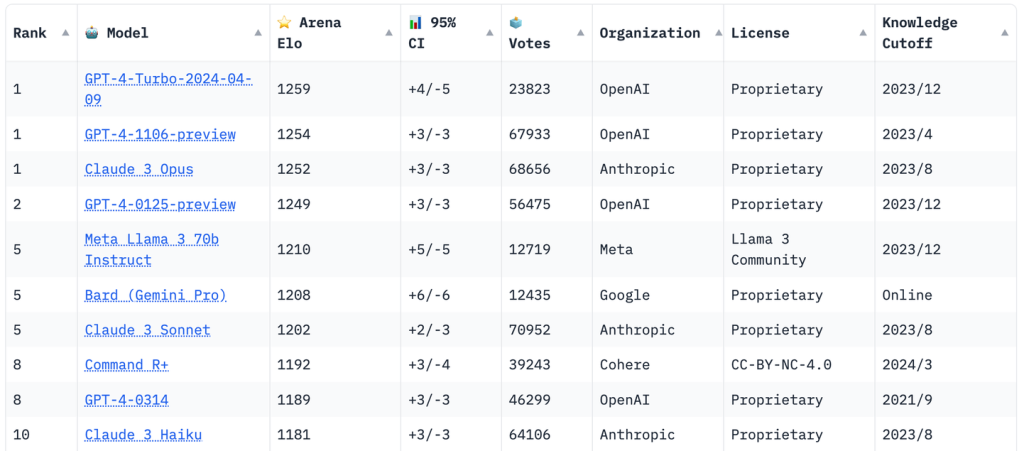
米Meta社が4月18日、大規模言語モデル「Llama 3」を公開しました。パラメーター数が80億のモデルと700億のモデルの2種類を用意しており、同じモデルサイズのオープンソースLLMではそれぞれ最高性能を誇ります。
また700億のモデルの性能は現在公開されているモデル全体の中で5番目にランクインしています。
パラメーター数4000億のモデルも現在学習中だそうで、完成すればまた大きな話題になることが想像できます。
想像を絶する速さで様々なモデルが発表されていきますね。今後も目が離せません。
出典:https://xtech.nikkei.com/atcl/nxt/news/24/00603/
AIが事実に基づかない情報を生成する現象のことを「ハルシネーション」といいます。このハルシネーションという問題を軽減する方法の1つとして、近年RAGという技術が使われ始めています。
RAG(Retrieval-Augmented Generationの略称。検索拡張生成とも呼称)とは、LLMによるテキスト生成に外部情報の検索を組み合わせる技術です。
検索対象は任意に設定することができるため、RAGを用いれば最新の情報や企業の内部ドキュメントなどを用いた回答生成が可能になります。実は現在皆さんの身の回りでリリースされている、LLMを使ったチャットボットや社内情報検索ツールの多くにこのRAGという技術が使われています。
さて、この便利なRAGモデルですが、もし仮に参照する外部情報とLLMが持つ内部知識が矛盾したとき、LLMはどちらの情報を信じて出力を行うのでしょうか?
この疑問に答える論文が発表されました。簡単に概要をご説明します。
この論文では、LLMの内部知識(事前知識)とRAGが提供する情報の食い違いが生じる状況下での両者の関係を分析しています。GPT-4などのLLMに対して、参照文書の有無による質問応答能力をテストし、参照文書に段階的に誤情報を加えてLLMの応答を分析しました。
結果として、以下の3つのことが分かりました。
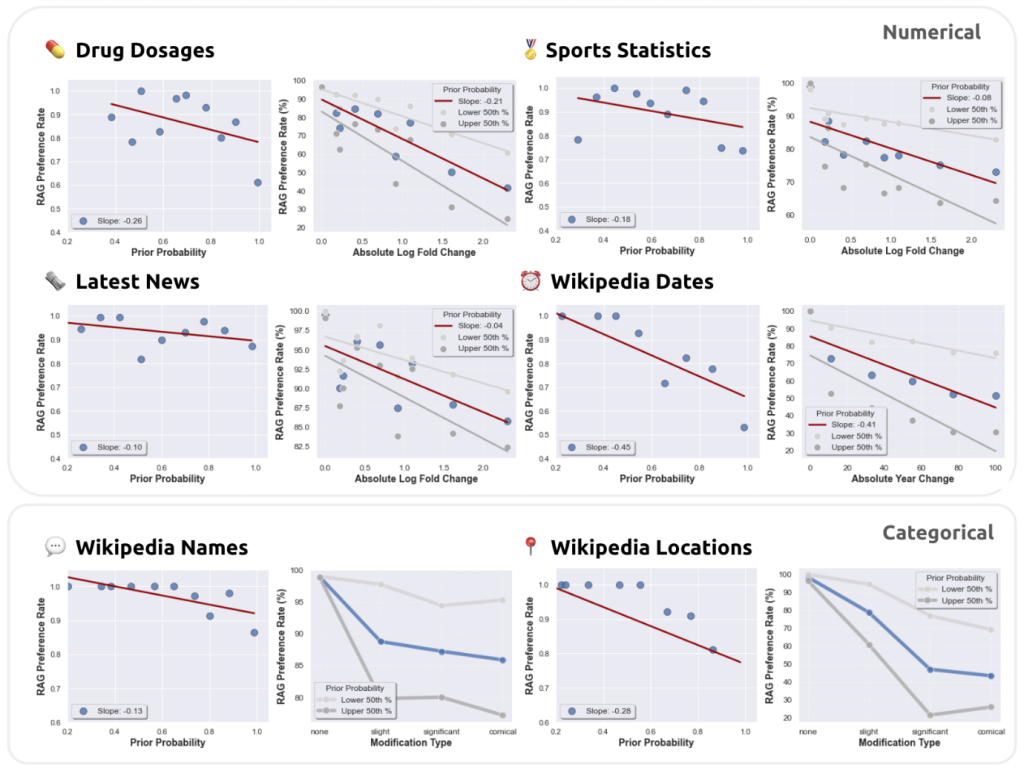
自分の知識が正しいと思っていれば自分の知識を信じ、不安なら外部から与えられた情報に頼るという意味では人間に似たものを感じます。そして、これらの結果をもとに論文では以下のように考察しています。
出力結果に正確性が強く求められ、かつ深い専門知識が必要な領域では予期せぬ出力の誤りが重大な事故に繋がる可能性もあります。以前GPT-4が司法試験や医師国家試験で合格水準のスコアを叩き出したというのがニュースになりましたが、まだまだ実務で使うには人間のチェックが不可欠そうです。
今後LLMとRAGの関係性に関する研究が進めば、うまく誤情報の出力を避けて正しい結果を導き出せるようになるのでしょうか。今後の研究発展に期待したいところです。
論文出典:https://arxiv.org/abs/2404.07413
皆さんはWebクローリング・スクレイピングをしたことはありますか?
Webクローリングとは、Webサイトを定期的に巡回して特定の情報を取得する技術です。必要な情報を大量に・素早く取得でき、Python等でも実装できる手軽さからデータ収集の時間を大きく削減することができます。
かく言う私も下っ端のコンサルタントですので、業務の一部に調査タスクが入ることがままあります。情報収集にはかなり時間がかかってしまうのですが、そういう時にクローリング・スクレイピングができると生産的でない時間をかなり削減することができます。
このクローリングに必要なスクリプト(クローラー)をLLMを用いて効率的に生成するためのフレームワーク”AutoCrawler”について紹介する論文が発表されました。簡単に概要をご説明します。
従来のWebクローリングではラッパーという手法が用いられており、これは特定のウェブサイトやページからデータを抽出するために特別にスクリプトやソフトウェアを設計するものです。形式が決まったウェブページのクローリングにおいては効率的に情報を取得できる一方、ウェブページの形式が異なるといちいち新しくスクリプトを書かなければならず、ユーザーへの負担が大きくなります。
一方、LLMの出現により、Webページを自律的に移動・解釈・対話できるクローリング用エージェントを作れるようになりました。しかしこれらは、パフォーマンスが低く、また再利用性が低い(同様のタスクを処理する場合でもいちいち同じ処理を繰り返してしまう)という課題がありました。
パフォーマンスと効率性を両立し、情報を取得できるのがAutoCrawlerです。
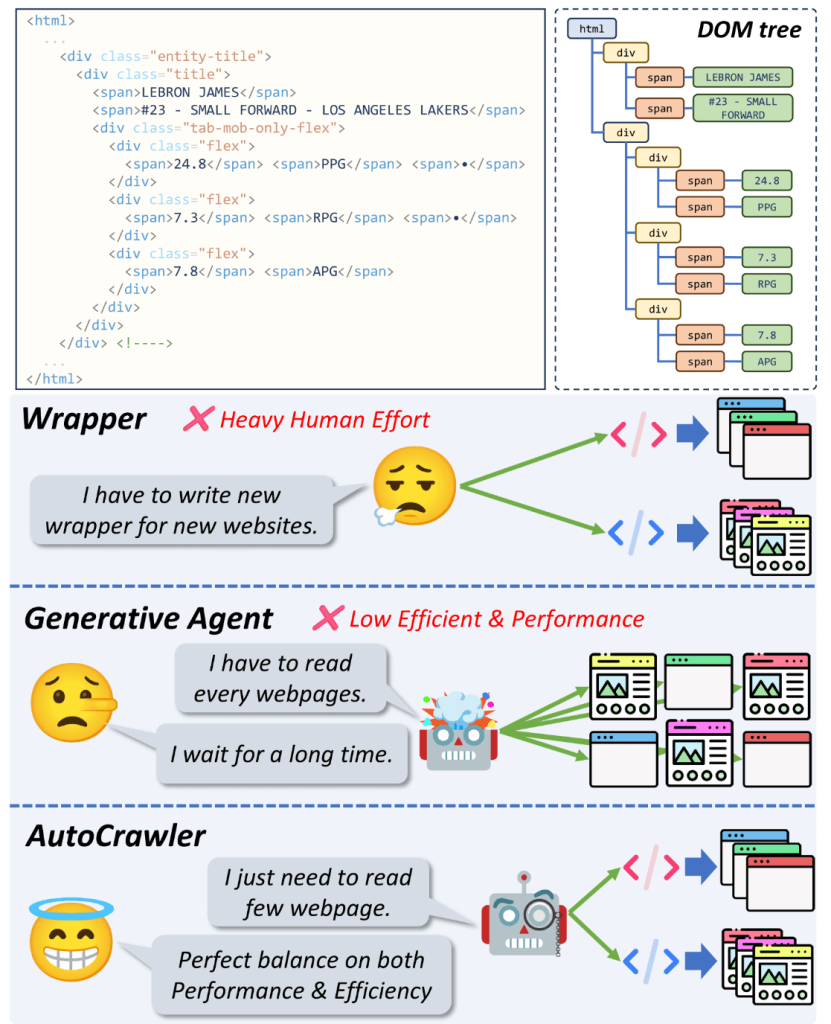
この論文で紹介するAutoCrawlerは、以下2段階に処理を分けることでクローラーの性能向上を図りました。操作を通じて誤ったアクションから学習する「段階的生成フェーズ」と、それらの処理を何度も実行して汎用性の高いアクションを生成する「合成フェーズ」です。
トップダウン操作でターゲット情報を含むノードへのXPath* を生成。実行に失敗した場合、ステップバック操作で階層を遡り、関連する情報を含むノードを選択しXPathを再生成。これを成功するまで繰り返す。
※XPath(XML Path Language)とは、 XMLやHTMLドキュメントのツリー構造から特定の要素や属性値を選択するための言語です。これは特にWebページの情報取得において有用です。
複数のWebページ上で1の処理を実行し、それらの結果に基づいて汎用性の高いアクションシーケンスを合成する。

これらの実験の結果、AutoCrawlerは、従来のフレームワークと比較して、より正確で実行可能なアクションシーケンスを生成できることが分かりました。また大規模なLLMの方が安定した性能を出せることも分かっています。
一方、LLM単体ではウェブページの構造理解が苦手であることもまた浮き彫りになりました。LLMの性能向上によって、いずれは構造理解の精度も上がっていくのでしょうか。今後の発展に期待です。
論文出典:https://arxiv.org/pdf/2404.12753v1
最後まで読んでいただきありがとうございます。
本日はLlama3公開・RAGモデルの信頼性・AutoCrawlerの3つのトピックをご紹介しました。
ブレインパッドは、LLM/Generative AIに関する研究プロジェクトの活動を通じて、企業のDXパートナーとして新たな技術の検証を進め企業のDXの推進を支援してまいります。
次回の連載でも最新情報を紹介いたします。お楽しみに!
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説