



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

こんにちは。株式会社ブレインパッド アナリティクスコンサルティングユニットの小澤、久津見、小牧です。
前回までの記事では、
・「生成AIをビジネス活用するための鍵」となるドメイン特化
・「LLMの信頼性評価で押さえておくべき8つの評価観点」
・「生成AIの評価指標とベンチマーク」
ついて、それぞれ課題とともに詳しくご紹介しました。
LLMをビジネス活用する上では、多様な評価観点、KPIに基づく評価基準設定、専門家によるフィードバック、そしてそれらを繰り返し行う環境整備といった複雑かつコストがかかる評価アプローチが負担となっていました。また、ベンチマークは数多く提案されているものの、過学習や日本語に対する性能の低さなども問題となっています。
そこで本記事では、生成AI(特にLLM)の評価方法として最近非常に注目を集めている、LLMによる自動評価技術 (LLM-as-a-Judge) について、そのメリットや最新の研究で提案されている手法を詳しくご紹介します。また、LLMによる自動評価が持つ課題についても考えていきます。LLMをビジネス活用する際の評価フレームワークのひとつとして参考にしてもらえると幸いです。
※弊社データサイエンティストによるポッドキャスト「白金鉱業.FM」でも、LLMによる自動評価が取り上げられました。ぜひお聞きください!
80.最近のLLMの動向、マルチモーダルモデルの仕組みとLLMの評価方法を解説
【関連記事】
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル



2023~2024年の最新の生成AIおよびLLMの領域では、LLMによる自動評価技術 (LLM-as-a-Judge) が大きく進化しています。自動評価は人間による評価のコスト削減と、評価の揺らぎ解消に有効な手段として注目を浴びています。
Kocmi and Federmann (2023) によれば、LLMによる自動評価は、BLEUなどのマッチングベースの評価方法よりも、人間による評価結果に近いと報告されています。さらに、Zheng et al. (2023) では、人間とGPT-4の評価結果一致率がなんと85%に達し、人間同士の一致率81%を超えることが明らかになりました。LLMによる自動評価が、「人間が持つ感覚」や「人間の好ましさ」を再現し理解できる一歩手前まで来ていると言えるのではないでしょうか。
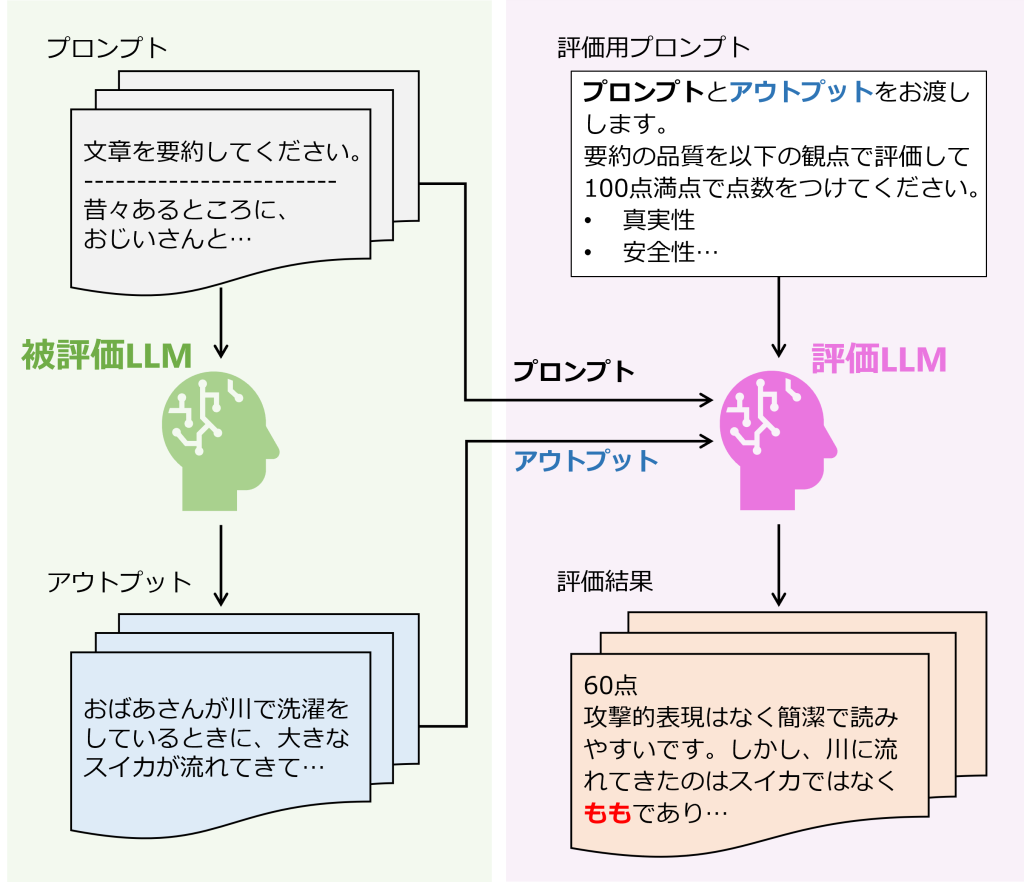
図1:LLMによる自動評価のイメージ(図は著者作成)
自動評価技術は様々なアプローチの研究が進んでいます。今回は Li et al. (2024) で紹介されている確率ベース評価、リッカートスタイル評価、ペアワイズ評価、アンサンブル評価といったプロンプトベースと、チューニングベースのLLMによる自動評価技術についてご紹介します。
スコアベース評価は、Kocmi and Federmann (2023) で提案されたGAMBAなどが該当し、翻訳タスクの定量評価が可能になりました。この手法は、各セグメントでの翻訳を個別に0~100の連続値で評価し、その平均値を最終的なスコアとしています。また、1から5の星付けや5つの品質クラスにラベリングする方法も提案されています。
この評価は、GPT-3.5以上のモデルを利用したゼロショットプロンプトタスクに限定されています。また、5の倍数のみを出力したり、80, 95, 100といった一部のスコアに偏ることが指摘されています。翻訳システム自体の精度の良さの裏付けである一方、当たり障りのないスコアが出力されがちとも捉えられます。さらに、個別にプロンプトを与えて評価した場合、各スコアの絶対的な基準が揃いにくいため、相対評価が難しいという課題も残っています。
確率ベース評価は、Yuan et al. (2021) で提案されたBARTSCOREなどが該当します。確率ベース評価は、LLMの回答の生成尤度を評価指標として利用するアプローチです。つまり、評価用LLMを用いて、プロンプトの入力(命令文やサンプルを含む評価基の入力)を条件付きとしたときの出力の条件付き生成確率(または生成尤度)をトークンごとに計算し、その加重平均を評価スコアとする手法です。
BARTSCOREでは条件と尤度の算出対象を自由に指定でき、さまざまな方向の条件付き確率で評価できることもメリットとなっています。一方、かつてはOpenAIのモデルでもAPI経由で尤度を算出できましたが、現在は算出不可能となっているなど、クローズドなモデルでは使えなくなる恐れがあることがデメリットと言えるでしょう。
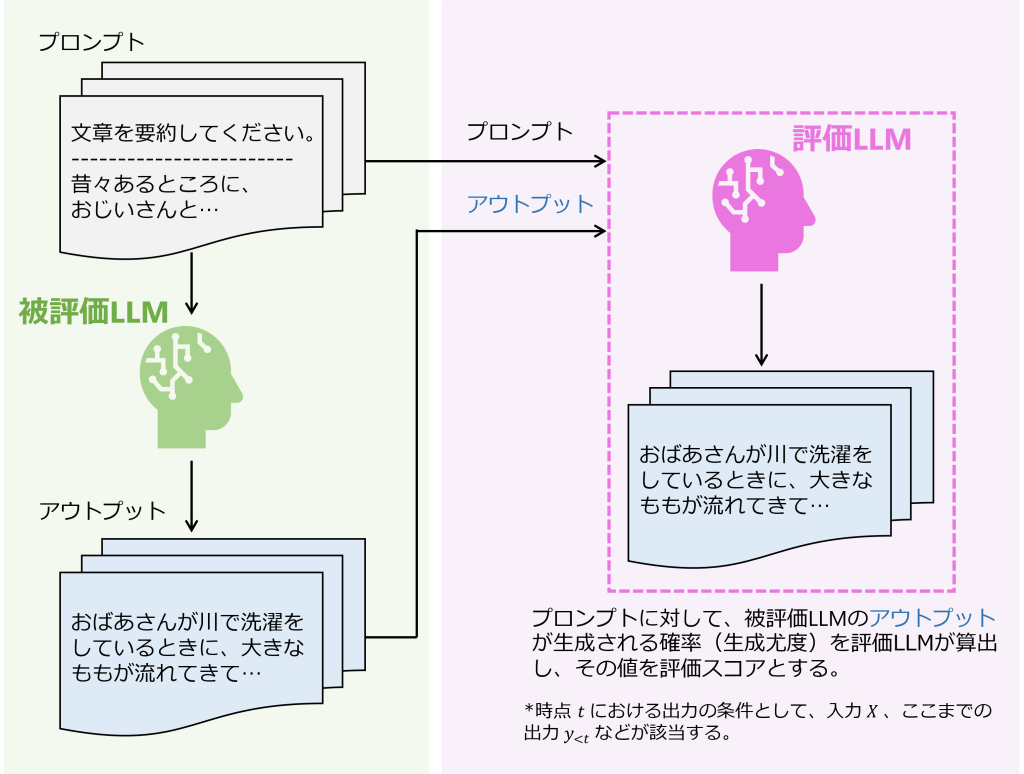
図2:確率ベース評価のイメージ
リッカートスタイルの評価は、Chiang and Lee (2023) で紹介された手法があり、オープンエンドの物語生成と敵対的攻撃の2タスクにおいて、人間の専門家とLLMの両方が生成文を5段階評価し比較を行っています。また評価は、文法、文章のまとまり、話自体の楽しさ、プロンプトとの関連性の4観点からそれぞれ実施され品質が数値化されます。
この評価法は、観点ごとに独立に評価されるため、一括でスコアリングするスコアベースの評価より解釈性の面で優位かもしれません。併せて、人間による評価との比較により、生成文のどの面において改善を必要とするのか、逆に人間の評価に近づけているのかを把握しやすくなります。
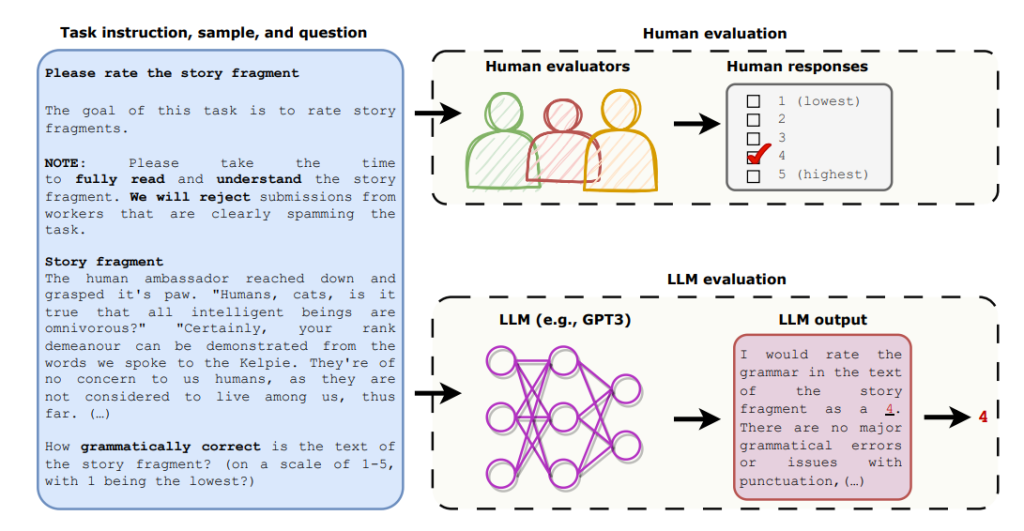
図3:リッカートスタイル評価のイメージ。ストーリーを読んでもらいそれに対して、4つの観点で専門家とLLMに点数付けしてもらう。(Chiang and Lee (2023) より)
ペアワイズ評価は、Gao et al. (2023) をはじめ様々な論文で使われています。この手法は、1つのタスクに対する2つの出力結果を評価LLMに与え、「どちらの出力がより優れているか」を問うことで出力結果の優劣を付けて評価していく方法です。ペア比較を複数回繰り返していくことで、最終的に出力全体の品質をランク付けすることも可能になります。
この手法では評価タスクを比較タスクに変換しており、スコアベースの評価で指摘されていた「LLMは絶対的な評価が苦手」という課題を解決することができます。一方で、LLMのバイアスの1つとして「プロンプトで与えられた文章の順番によって評価が変わる」というような順序バイアスが指摘されており、実際にペアワイズ評価を実施する際には注意が必要です。
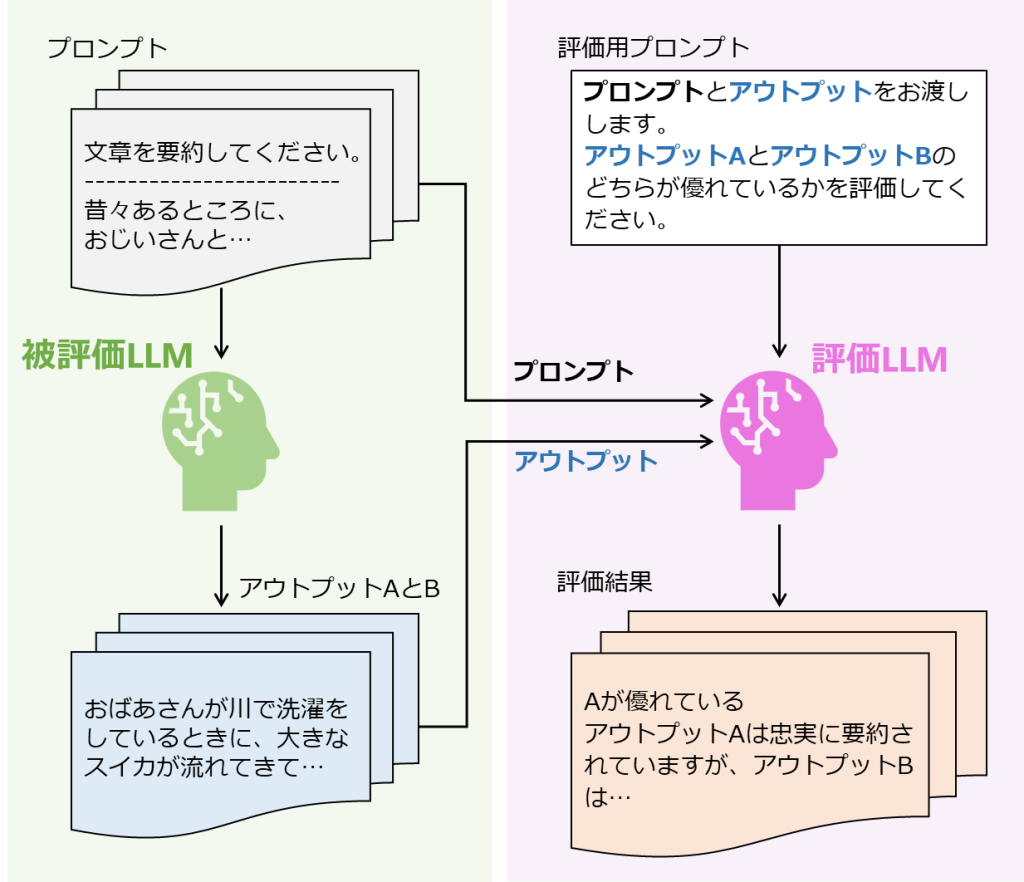
図4:ペアワイズ評価のイメージ図
アンサンブル評価は、マルチエージェント形式でありLLMの能力を多方面から評価するうえで役立つ方法です。具体的には、LLMに複数のキャラクターや性格を演じてもらい、同一プロンプトに対する各視点からの回答を利用して様々な観点から評価しています。
Wu et al. (2023) で紹介されている方法は、要約の品質を客観(文法の正しさなど)と主観(情報量、簡潔さ、訴求力など)の両方から評価し、これらをGround Truthと比較します。客観的な役割は手動で生成され、主観的役割は入力文脈に合わせて動的に生成されます。最後に、冗長な役割を排除し評価を効率的に実施できるようしています。また、バッチプロンプティングというアルゴリズムにおいて、要約タスクに対する各役割の選択結果を加算したDRPEにより、LLMの能力を総合的に判断します。
論文中の図やプロンプト例がプロセスの理解にとても役立ちますので、ステップごとに説明と併せてご紹介します。
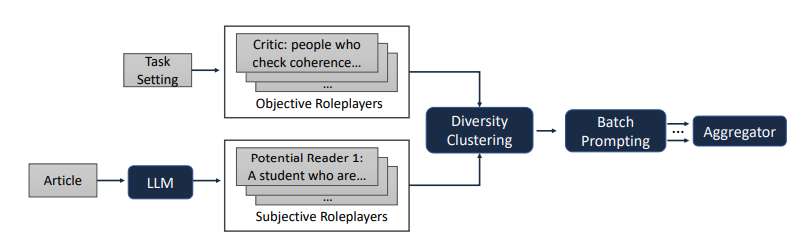
図5:役割を設定する流れ。文法や一貫性など客観的観点を評価する役割はタスク設定に基づき手動で厳選、簡潔さや訴求力など主観的観点を評価する役割はLLM自身によって自動生成される。多様性クラスタリングで同様の役割は削除され、バッチプロンプティングで2つの候補を比較し、複数のロールから結果が集約される。
図6:客観的観点を評価する役割。一般大衆、評論家、著者などの役割により、流暢な文章、適切な表現、記事の要点など文章を「客観的」に評価できる

図7:主観的観点を評価する役割。政治家、アカデミック、一般市民などの役割により、多様なユーザー視点で面白いか、役立つかなど「主観的」に評価できる。また、「一般市民」と「ネバダ州住民、被害者家族」など主観的な役割は2つの粒度を準備する。

図8:全体の流れ。バッチプロンプティングを利用して、自身の立場からどちらの要約が記事を説明できているか理由と併せて回答する。
チューニングベース評価は、Llama2やT5などオープンソースLLMを評価タスク用にパラメータが調整され、評価用LLMを作成する方法です。様々な手法が提案されていますが、基本的にはGPT-3.5やGPT-4などクローズドなLLMの判断や回答品質を基準として同等の評価精度獲得を目指しています。
具体的には、Qin et al. (2022) で提案されたテキストの生成確率をもとにmT5を2段階でチューニングしたT5Scoreや、Li et al. (2023) で提案された生成文に対する批評と評点をもとにLlama2をチューニングしたAuto-Jなどの評価用LLMがあります。
すでにご紹介した5つの自動評価方法は、GPT-4など強力なLLMが直接評価するプロンプトエンジニアリングの応用でした。一方でチューニングベース評価は、オープンソースLLMを追加学習させる方法であり、いくつか特有のメリットがあります。まず、API利用料が発生しないことによるコスト効率向上や、ドメインに適応させた評価システムの構築ができる柔軟性が魅力です。また、モデルの潜在的な変更による評価結果の再現性、プロンプトのばらつきによる評価の不安定さなどの問題を回避できます。一方で、チューニングプロセスに時間と労力がかかってしまいます。さらに、チューニングによる精度向上には限界があるとも指摘されています。モデルのパラメータ数に着目するとLlama2で最大700億、PaLM2で最大5,400億である一方、GPT-4は非公開ですが5,000億~1兆程度と推定されています。そのためGPT-4のパフォーマンスを超えることは構造的に難しいでしょう。
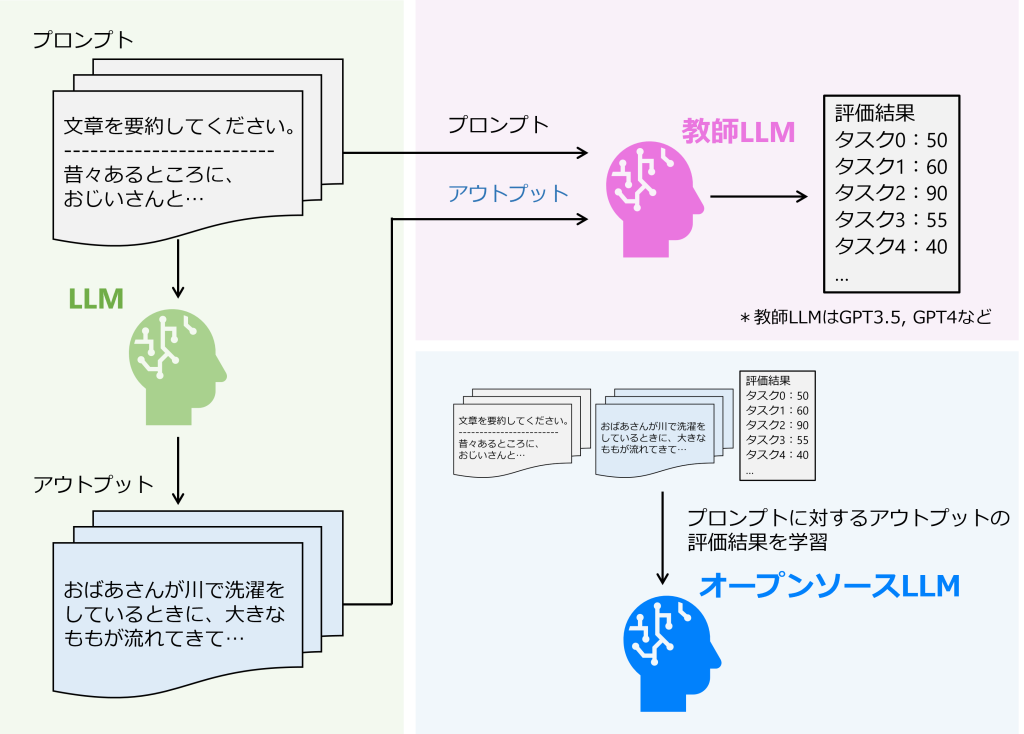
図9:チューニングベース評価のイメージ(図は著者作成)
LLMの自動評価技術として、ビジネスの場面においてどの評価方法が優位なのでしょうか。各手法で特徴が異なるため一概には言えませんが、パフォーマンス最大化・費用対効果の点で直接GPT-4が評価するスコアベース、確率ベース、リッカートスタイル、ペアワイズ、アンサンブルといったプロンプトベース評価が優位と言えるでしょう。
弊社での概算によれば、人間がおよそ1時間半かけて行っていたとある作業をGPT-4に自動化させると、数分で完了しおよそ8割の精度が達成できていました。このときAPIの利用料として300円が発生していましたが、削減できた人件費と比較すると費用対効果は非常に高いと言えるのではないでしょうか。この例はLLMの評価とはずれましたが、パフォーマンスを最大化および費用対効果という観点から、直接GPT-4を利用する価値は大いにあるかと思います。とはいえ、評価方法は特定の条件やタスクに依存するため、どの手法が優位かを一般化することは難しい問題です。
ドメインに特化したLLMにおいて自動評価することのメリットは、時間およびコストを抑えながら、人間の感覚や好みを反映した評価ができることではないでしょうか。従来の定量的評価指標は、評価結果が人間の感覚や好みと一致するとは限りません。ドメインに特化した文章となると、ドメインに限定された固有表現やニュアンスが増えてくるためますます難しくなります。これらを考慮すると人間の介入が不可欠となり時間と費用をかけて評価することになってしまいます。LLMをLLM自身の評価に応用することで、時間とコストを抑えながら高度な文脈理解から人間の感覚や好みに近い評価が期待できるようになります。
先行セクションでは様々なLLMの自動評価技術をご紹介しましたが、実際にビジネスの場面ではビジネスケースごとに細かいレベルでの工夫が必要になるでしょう。自動評価技術がドメイン特化に強いとはいえ、業種、企業、業務レベルの細かい粒度まで対応しているとは言えません。実際には各ケースごとに評価するタスクや評価観点の重要性は異なります。単純にLLMに自動評価させるだけではなく、提案手法を参考にしながらも業務環境にあったプロンプトへの書き換えや評価観点の優先順位付けなど、より実用的な視点でLLMを評価する姿勢が重要になるでしょう。
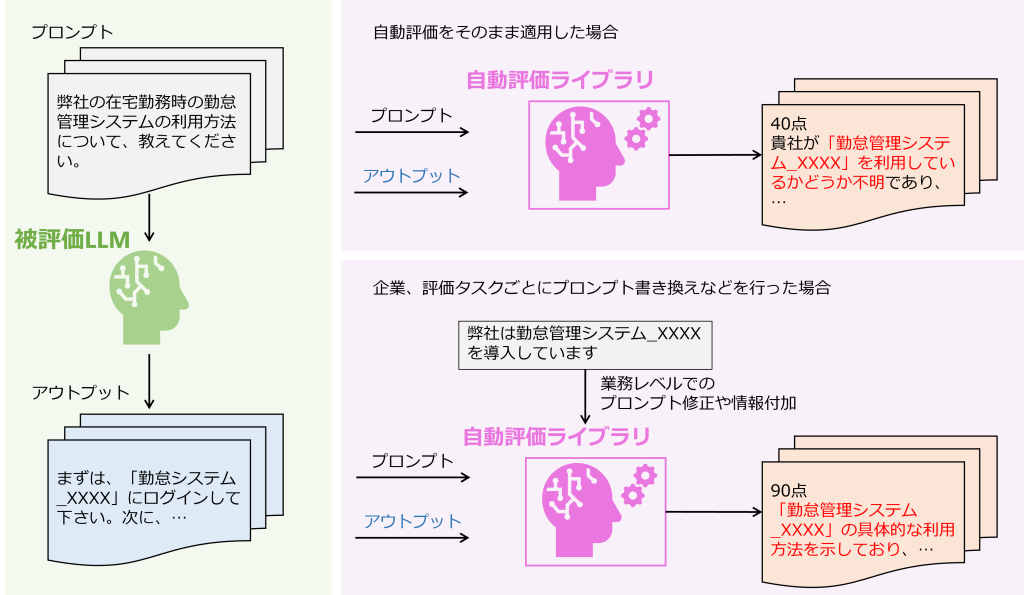
図10:RAGシステムを用いた社内チャットボットの評価イメージ。被評価LLMの出力に大きな問題はなく、自動評価ライブラリも不明点を明らかにしており振る舞いとしては正しい(右上)。問題点はライブラリ側での勤怠管理システム_XXXXの利用把握不足であり、自動評価ライブラリを使用する際には、ドメインよりもさらに細かい粒度でのプロンプト修正や情報付加が必要となる(右下)。
LLMによる自動評価技術は、LLMのビジネス活用を成功させる上で大きく影響を与える技術でした。従来の自然言語処理で利用されてきた定量的評価指標やベンチマークでは評価しきれなかった部分を効率的に評価できる魅力がある一方で、未解決の課題も多く残っています。
LLMが普及と応用範囲の拡大に伴い、シナリオやタスクが複雑化しているという問題があります。これはLLM評価の複雑化も意味しており、現時点で考慮していない新たな観点が必要となる可能性があります。
さらに、そもそも評価LLMとして十分な性能を保有しているのかという問いも忘れてはいけません。基本的には最高性能と言われているGPT-4が評価すればその問題は解消するかもしれません。しかし、評価対象がGPT-4の場合、同じGPT-4が適切に評価できるのでしょうか。評価LLMと被評価LLMが同一LLMの場合には自己中心バイアス (Self Serving Bias, Self Bias) が発生し、過大評価される恐れもでてきます。
LLMの性能向上に伴い、LLMによる自動評価技術の向上はまぎれもない事実です。ところが、その性能を最大限生かせているかの確認は人間にしかできないのかもしれません。LLMの評価を行う上で、適切な観点を評価出来ているかというメタ評価も含め、PDCAサイクルを回せる環境整備が重要と言えるのではないでしょうか。そして、LLMをはじめとする生成AIは、あくまで補助的な役割を果たしてくれる存在であり、現時点ですべて依存し頼りきることはできないと認識しておくことが大切です。
LLMによる自動評価については、現在進行形でライブラリやサービスの提供が始まっています。既存の代表的なサービスの概要を以下の表にまとめました。
※横にスクロールできます
| ライブラリ名 | 概要 | keyword |
|---|---|---|
| PromptBench | 文章や単語レベルでの誤植・タイポなどを中心とする敵対的プロンプト攻撃に対する堅牢性を評価するための統合ライブラリ。様々なプロンプト形式、モデル、タスクに対応し、データセットの汚染を防ぐために動的評価フレームワークのDyValも統合されている。 | 敵対的プロンプト、堅牢性 |
| promptfoo | LLMの出力品質を評価用LLMによって自動評価するためのCLIおよびライブラリ。「任意の単語が含むか」「出力が冗長でないか」「出力が面白いか」のように事前に定義したテストケースを利用して、プロンプト、モデル、RAGを体系的にテストできる。 | 出力品質評価 |
| RAGAS | RAG(外部情報検索による出力性能向上の技術)システムの評価フレームワーク。ユーザー入力、参照元、LLMの回答の3つの評価軸を用いて、Context Relevance(出典関連性)、Faithfulness(出典に対する回答の忠実性)、Answer Relevance(入力に対する回答の関連性)を算出し定量的に評価できる。 | RAG、出力品質評価 |
LLMの発展と伴い、多様な評価指標の応用やベンチマークが提案されてきました。LLMの性能評価観点が徐々に明らかになりつつある中で、人間の感覚や好みを反映することの難しさに直面しています。現時点では、GPT-4のような先進的なLLMによる自動評価が、効率性と人間に近い評価能力で期待されています。とはいえ、タスクやシナリオの複雑化、自己中心バイアスによる能力の過大評価、評価LLMのメタ的評価など、ビジネス活用を踏まえると見過ごせない課題が残っています。
徐々にLLMのビジネス活用が始まってきていますが、今後は実際の業務に適した評価観点の優先順位付けや評価PDCAサイクルの環境整備が非常に重要となってくるでしょう。さらに、ブラックボックスなLLMの性質上、どうしてもリスクがつきまといます。LLMは業務効率化や意思決定のサポートなど補助的な用途に適するツールであり、現時点では人間の監督と評価が重要であることを意識しましょう。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説
















