



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

こんにちは。株式会社ブレインパッド アナリティクスコンサルティングユニットの小澤、久津見、小牧です。前回の記事「生成AIをビジネス活用する上で押さえるべき8つの評価観点」では、生成AI(特にLLM)をビジネス活用する際に着目すべき信頼性の評価観点についてご紹介しました。
今回は、LLMのビジネス活用を成功させるために、より具体的なLLMの評価方法に着目していきたいと思います。LLMのビジネス活用を目指す上でおさえておきたい評価指標やベンチマーク、それらに関連する問題点や限界など網羅的にご紹介します。
LLMの性能評価の重要性と難しさ、そして評価観点の多様さを踏まえると、ビジネス適用に向けてどのような方法でLLMを評価していくが重要な課題となります。ここからは、自然言語処理やLLMの発展に伴って提案されてきた評価指標やベンチマークについてご紹介します。
【関連記事】
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題


評価指標は人間の介入有無で大別され、Li et al. (2024) によると人間を介さない評価方法は、さらにマッチングベースと生成ベースに分類しています。
マッチングベースの評価には、語順や文法を無視してGround Truthと生成テキストの一致度を測定するF1スコア、ROUGE、BLEUなどの古典的アプローチや、Word2Vecなど単語埋め込みとニューラルネットワークを利用してベクトルの類似性で評価するBERTScoreなどが含まれます。これらの手法は、低コストながら評価の再現性が高いという利点があります。一方で、”I go go go go to the hospital.” のような文法的に不適切な繰り返しでスコアが高くなったり、微妙なニュアンスや複雑な文脈の意図をくみ取ることが難しかったりする問題があります。また、Liu et al. (2008) によれば、人間の好みとの相関関係は低いことが指摘されています。特にLLMの場合、Ground Truthが一意に定まらないオープンクエスチョンや要約タスクなどで評価として不十分です。
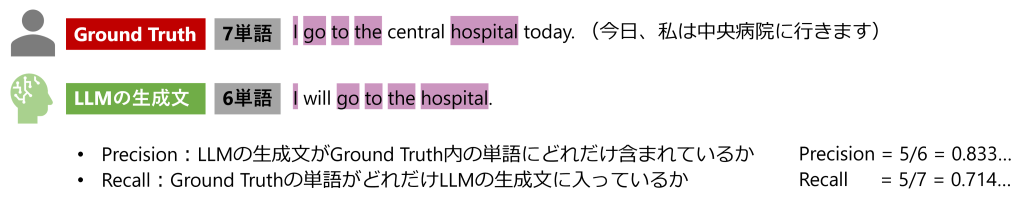
図1:マッチングベース評価のイメージ。ROUGE-1(単語単位)の場合
自然言語生成において、マッチングベースの評価結果が人間の感覚や好みを反映できていないという議論は多くなされています。特にLLMにおいては、「生成AIをビジネス活用する上で押さえるべき8つの評価観点」でご紹介したように、真実性、安全性、公平性など様々な観点からの評価が必要になるため、実際の人間による評価の価値が高まります。OpenAIの Ouyang et al. (2022) でも書かれている通り、人間からのフィードバックを用いた強化学習 (RLHF) はChatGPTのモデルにも利用されています。一方、評価する人間の社会的立場や文化的背景による個体間の揺らぎを防げないこと、人間を介さない評価に比べコストが大きく膨らむことが問題となります。一人ひとりが複雑でさまざまな背景を持つため、評価の揺らぎを完全になくすことは難しく、特定の考えを強要することも本質的ではありません。そのためLLMの開発段階から複数の立場の人間によるフィードバックを総合的に反映するなどの工夫が必要になります。
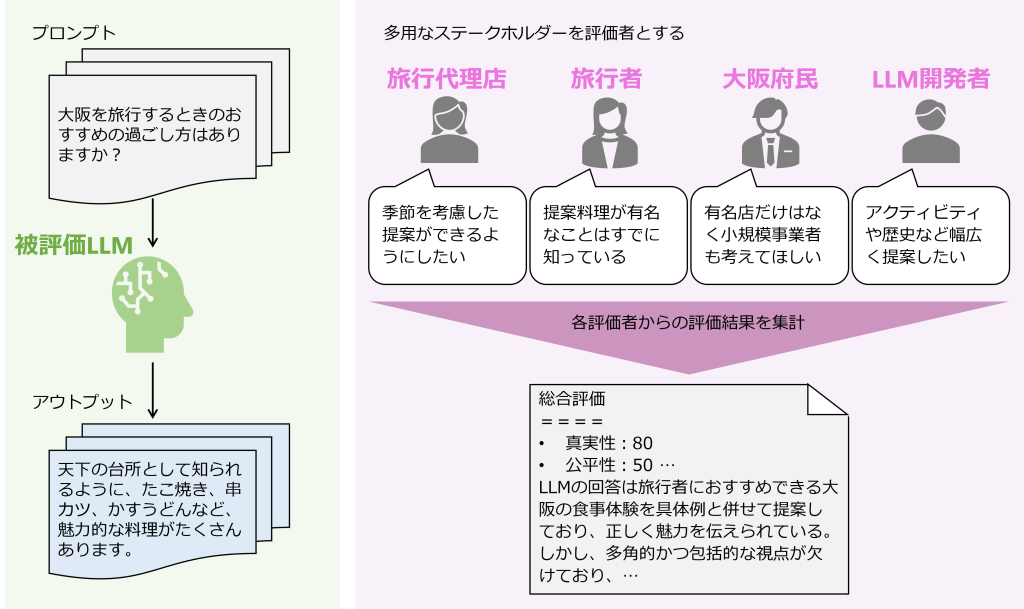
図2:人間ベース評価のイメージ
LLMの新しい評価方法として、GPT-4など強力なLLMに評価をさせる方法 (LLMによる自動評価, LLM-as-a-Judge) があります。LLMによる自動評価は人間による評価と非常に近い評価を下すという研究結果が多数出ており、新たなLLM評価方法として注目を浴びています。生成ベースの評価方法については様々な提案がされてきていますので、次回のブログでご紹介します。
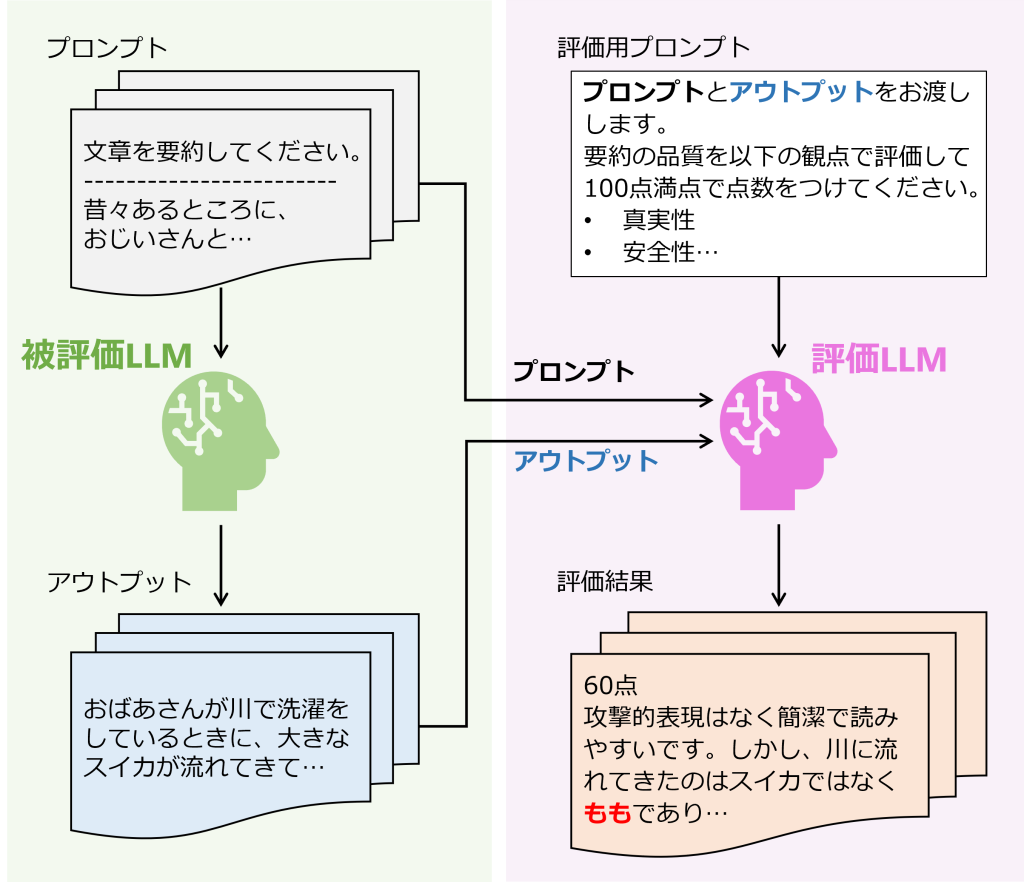
図3:生成ベース評価のイメージ
LLMの分野におけるベンチマークとは、特定のタスク、タスク遂行のためのデータセット、遂行能力を評価するメトリック(Accuracy、F1スコア、不適切発言発生率など)を含む評価の枠組みを指しています。タスクはQA、要約、翻訳など多岐にわたり、データセットもそれらに対応する自然言語データセットが準備されています。また、近年ではLLMの真実性、安全性、公平性など評価観点に焦点を当てたベンチマークも多数提案されています。これらのベンチマークは、特定のユースケースに適したモデルを選択する際の指針となります。Zheng et al. (2023) によるとベンチマークは以下の3カテゴリーに分類されます。それぞれの説明とそのベンチマークの中身の例をご紹介します。

図4:LLMにおけるベンチマークによる評価のイメージ(図は著者作成)
※上記の例では、映画レビューのデータを用いて、LLMによるレビューのポジネガ判定(2値分類)タスクの結果をF1スコアで評価している。複数のLLMによるF1スコアの比較も可能である。
Core-knowledge benchmarksは、事前学習済みLLMの基礎となる能力を測定するベンチマークのクラスターです。LLMがどれだけ汎用的な知識を保有し、ゼロショット/フューショットの条件下でどの程度タスクを遂行できるかを評価できます。難易度は低めの設計であり、ドメインに特化できていてビジネスに適用できるかの測定というよりも、その前提となるLLMの基本的な理解力の測定に適してます。
高校レベルから専門レベルまでを問う問題が多く集められています。人文科学に関するタスクでは、高校レベルの歴史・国際法・法学のデータセットが準備されており、評価は主にAccuracyが用いられています。
基本的な言語理解能力を広く測定するために設計されたベンチマークです。映画レビューデータを用いた感情の2値分類や、ニュース見出し文を用いた類似性評価など複数のタスクを含んでいます。評価はAccuracy、F1スコア、マシューズ相関係数、スピアマンの順位相関係数などタスクごとに様々な指標が用いられています。
Instruction-following benchmarksは、Instruction tuning(指示に従ってタスクを実行するように学習させる方法)済みのLLMの能力を測定するベンチマークのクラスターで、オープンエンドで多様なタスクのプロンプトが利用されています。ベンチマークの難易度は3つの中で中央に位置します。
分類、テキスト作成、シーケンスのタグ付け、文法ミス修正など76種類のタスク、55の言語、合計1,616の自然言語処理タスクをカバーし、未知タスクへの適応能力を評価するベンチマークです。評価指標としてはROUGE-Lが用いられています。
Conversational benchmarksは、チャットボットLLMの会話能力を測定するベンチマークのクラスターです。これらのベンチマークのタスクでは複雑で多様な回答を求めており、ほかのカテゴリーと比較して最高難易度です。カスタマーチャットボットの開発などではこれらのベンチマークでの検証が役立つでしょう。
80のマルチターン(複数回の会話ラリー)質問を考慮したベンチマークです。プロンプトとしては、ライティング、ロールプレイ、数学、コーディング、推論など合計8カテゴリあり、それぞれ10個のマルチターン質問から構成されています。評価は主に1-10の10段階評価が用いられています。
歴史、社会、政治、地理に関する日本語での40のオープンクエスチョンが含まれたベンチマークです。どのLLMの出力が最適かをペア比較により別の評価用LLMが評価します。評価は、モデルの相対的なランク付けで使用されるBrandley-Terry modelによるElo scoreが用いられています。
ドメイン特化LLMの性能を評価するためには、そのドメインに適用できているかどうかの判断が不可欠です。ベンチマークの利用は、一般的なLLMの能力評価に加え、ドメインのニーズへの対応力や、業務要件でのパフォーマンスなど総合的に評価できます。
例えば、先ほどご紹介したSUPER-NATURAL INSTRUCTIONSでは、33ものドメインをカバーしており、ビジネス利用のために必要な多くの要件を満たしているかの把握に役立ちます。とはいえ、ドメインごとのタスク数には大きなばらつきがあり、すべてのドメインが網羅されているわけではないため、改善の余地があると考えられます。実際に活用する際にはベンチマークがどのようなドメインのデータセットを用いて評価しているのか、ドキュメントで確認するようにしましょう。
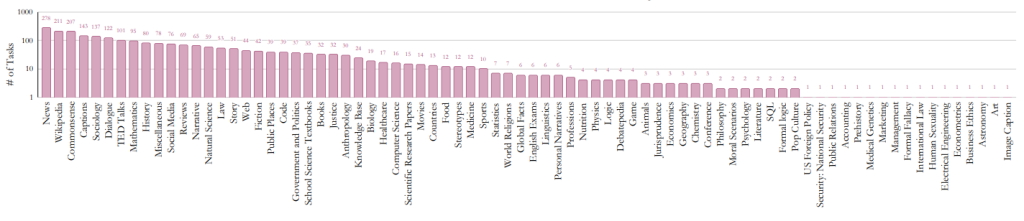
図5:SUPER-NATURAL INSTRUCTIONSのタスクでカバーされているドメイン一覧(Wang et al. (2022)より)
ベンチマークはLLMの能力を測定する方法として有効ですが、使い方によってはテストが簡略化されてしまうケースもあります。例えば、堅牢性評価のベンチマークのみを利用した場合、過度なハルシネーションや差別的な発言など別の観点で問題発生のリスクが残っています。また、単一の指標(例:Accuracy)や少数の指標に依存しているベンチマークも多く、任意の指標のみで判断してLLMの性能が過大評価されてしまうリスクもあります。ベンチマークを適用することで終わらず、ベンチマークの評価観点や評価スコアの指標についてドキュメントで確認することが大切です。評価観点の不足や指標の偏りが懸念される際には、複数のベンチマークを組み合わせるなど工夫が求められるでしょう。
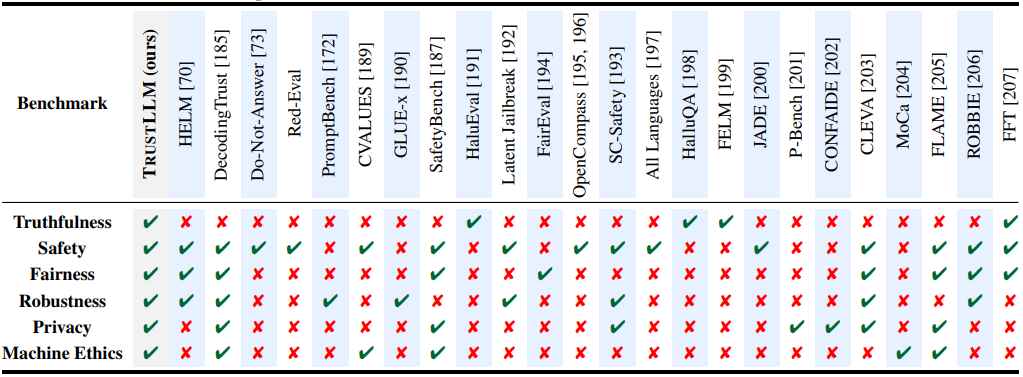
図6:主要ベンチマークごとの評価可能観点(Sun et al. (2024) より)
多くのベンチマークは既存のデータセットを利用して評価しています。これは、異なるベンチマーク間で評価タスク重複の発生リスクがあり、汎用性の過大評価に繋がります。また、アクセス可能な既存データセットは、悪意ある情報や偶発的な誤情報による汚染の可能性があり、LLMの性能評価を誤った方向に導くリスクを増加させます。さらに、固定のデータセットで評価(静的評価)しながらモデルを改善するため、過学習による汎化性能の低下につながる恐れも出てきます。
Zhu et al. (2023) では上記の問題に対処すべく、DyValという動的評価を可能とするベンチマークが提案されました。設定したパラメータに応じてレベル別の評価用サンプルを自動生成する新たなプロトコルです。これにより、LLMの動的な性能評価が現実的なものになり、過学習のリスク軽減が期待されています。DyValは一例ですが、LLMの過学習を防ぐことへの考慮も大変重要です。
現在のLLMは事前学習用データセットの大部分は英語です。Metaが Touvron et al. (2023) で公開したLlama 2の事前学習用データセットの言語割合は英語が89.70%に対し、これに次ぐドイツ語でもわずか0.17%、日本語は0.10%と学習量の差が圧倒的です。そのため、英語以外の言語におけるLLMの性能は低いとの指摘があります。日本国内でのビジネス利用を目指す場合、日本語の自然な言語生成能力や理解能力を正確に評価できるベンチマークが必要不可欠です。
ところが、日本語には他言語には見られない固有の概念や性質が存在します。例えば、ひらがな、カタカナ、漢字、ローマ字の文字種の混合、主語の省略、敬語表現などです。日本語特化のベンチマークの不足と併せて、日本語特有の概念や性質が、日本語を含むLLMの開発と改善を妨げる要因となっています。Gekhman et al. (2023) で提案された評価手法では多言語対応も検討され、日本語においても性能向上が見られました。ベンチマーク使用時には英語と日本語間の評価精度の乖離を小さくするために、日本語への対応状況も併せて確認するとよいでしょう。
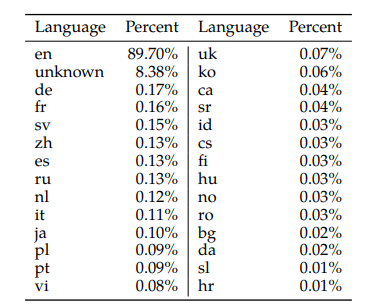
図7:Llama 2の事前学習に利用された言語割合(Touvron et al. (2023) より)
LLMの発展と伴い、多様な評価指標の応用やベンチマークが提案されてきました。LLMの性能をタスクや言語、ドメインごとに評価できるということでベンチマークは効率的な評価方法と言えるでしょう。しかし、すべてのベンチマークがLLMの評価観点を網羅できているわけではありません。さらに、データセット依存の過学習や、日本語ベンチマークの遅れといった課題が残っています。これらは粒度の細かい企業・業務レベルでLLMの評価をしようとしたときに、問題が大きくなる恐れがあります。ベンチマークの評価結果に頼り切るのではなく、「生成AIをビジネス活用するための鍵とは?」でもご紹介したように業務環境に適したプロンプト作成や評価観点の優先順位付けなど、より実用的な視点でLLMを評価する姿勢が重要です。
次回の記事では、人間の評価結果により近いことで注目を集めている評価アプローチである、LLMによる自動評価 (LLM-as-a-Judge) に着目して、最新研究内容と併せて詳しくご紹介する予定です。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説












