

メルマガ登録
ベストなDXへの入り口が見つかるメディア


-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
ベストなDXへの入り口が見つかるメディア
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

こんにちは、生成AIタスクフォースの辻です。
前回の記事では、限界費用がゼロに近づくナレッジワーカーとしての生成AIのビジネスへの影響について考察しました。本稿を含めて数回にわたって実務的な視点から、生成AIサービスの市場構造とその競争力学について分析を深めていきます。
【関連記事】

急速な発展を遂げている生成AIサービス市場の構造を理解する上で特に注目すべき要素として、次の二点が考えられます。一つは生成AIの出力の品質を誰が保証するのかという問題であり、もう一つは既存の業務システムやワークフローにどこまで組み込めるかという問題です。
前者は、AIが出力した内容に誤りや問題があった場合の責任と対応コストに関わる重要な課題です。後者は、従業員が実際に業務で生成AIサービスを使う際の使いやすさや効率性を決定づける要素と言えます。これらの要素は、市場における各プレイヤーの位置づけと競争優位性を規定する重要な軸となると考えられます。
なお、本分析では、主にビジネスの生産性向上を目的とした生成AIサービス(BtoB)に焦点を当てます。個人消費者向けの娯楽目的の生成AIサービスについては、異なる市場力学が働くため、別途考察する予定です。
皆さんは、ChatGPTやGeminiなどの生成AIサービスを利用する際、利用規約や免責事項をじっくりと読まれたことはあるでしょうか。日々何気なく利用しているこれらのサービスには、実は興味深い共通点が隠されています。
生成AIモデルを開発・提供する企業は、一般消費者向けのチャットサービスであれ、企業向けのAPIサービスであれ、共通して明確な免責規定を設けています。その内容は、出力内容の正確性や完全性に関する保証の否認、生成された情報の利用に起因する損害への責任制限、そして知的財産権侵害に関するリスクの明示など、広範に及びます。
生成AIは高度な知的作業を実現する一方で、その出力の品質保証が困難であるという、一見矛盾した状況が存在します。この矛盾は生成AIの本質的な特徴から生じており、それは生成AIサービスの市場構造を理解する重要な鍵となっています。
生成AIは、大規模な学習データから統計的に抽出されたパターンに基づいて、新しい情報を生成する仕組みを持っています。この仕組みは、人間の創造的な思考に似た柔軟な対話や提案を可能にする一方で、出力を完全に制御することを困難にしています。
【参考】生成AIとは?AI、ChatGPTとの違いや仕組み・種類・ビジネス活用事例
生成AIモデルの開発企業はアライメント1やコンテンツフィルタリング2のような様々な制御手法を実装することで人間にとって有害な出力を抑制できるように努めていますが、学習データから抽出されたパターンの新しい組み合わせによって、意図しない出力が生成される可能性は常に存在します。この出力の予測不可能性は、生成AIの基本的な設計思想に根ざした本質的な課題と言えます。
1 生成AIの出力を人間の意図や倫理的価値観を適合させるアプローチ
2 生成された内容のうち不適切・有害な出力を検知し除外する機能
医療相談を例に考えてみましょう。生成AIを活用したチャットボットは、「頭痛がする」という相談に対して、一般的な健康アドバイスを提供するよう設計されています。しかし、学習データに含まれる医療情報が予期せぬ形で組み合わさることで、具体的な診断や処方を示唆してしまう不適切な回答が生成されることがあります。 このような出力は、単なるプログラミングの不具合ではなく、生成AIの仕組みそのものから生じる課題です。入力と出力の組み合わせは無限に存在し、それぞれの文脈も異なるため、すべての場合について不適切な出力を事前に防ぐことは技術的に困難です。
また、事実関係の正確性についても同様の課題があります。
例えば、企業の歴史について質問された場合、モデルは学習データから得た情報を組み合わせて回答を生成します。この過程で、実際の創業年と異なる年を述べたり、実在しない製品について言及したりするハルシネーションが発生する可能性があります。
ハルシネーションとは、実在しない情報や誤った事実関係を、あたかも真実であるかのように出力してしまう現象です。この問題は、特に事実に基づく正確な情報提供が求められるビジネスシーンにおいて深刻な影響をもたらす可能性があります。
生成AI出力の「正しさ」は単純に事実との整合性だけでは判断できません。技術的な正確性は重要な要素ですが、それは「正しさ」を構成する一側面に過ぎません。特に企業活動において、情報の適切性は状況や文脈(コンテキスト)に強く依存します。
例えば、ある企業の四半期決算に関する分析を考えてみましょう。生成AIは財務諸表から技術的に正確な数値を抽出し、的確な分析を行うかもしれません。しかし、その情報がインサイダー取引規制に抵触する時期に開示されたり、機密情報を含む形で共有されたりすれば、それは明らかに「不適切」な出力となります。
また、企業の人事施策に関する質問に対して、生成AIが与えられた情報を理解し正確な分析を提示したとしても、それが特定の従業員層に対する配慮を欠いていたり、労働法規に抵触する提案を含んでいたりする可能性もあります。このように、技術的な正確性と社会的な適切性は、必ずしも一致しないことに注意が必要です。
さらに、出力の適切性は文化や時代によっても大きく変化します。例えば、ダイバーシティに関する提言において、ある地域や時代では適切とされる表現が、別の文脈では不適切とされることがあります。こうした微妙な価値観の違いを完全に把握し管理することはきわめて困難です。
このような予測不可能性と多面的な「正しさ」の存在は、生成AIサービスを提供している企業のスタンスをより抑制的なものにします。技術的に正確な情報であっても、予期せぬ有害な出力が生成される可能性や、事実と異なる情報が出力されるリスクは避けられません。そのため、生成AIサービスを提供している企業は出力内容が必ずしも企業の公式見解を表すものではないことを明確にし、免責事項を明記した上でチャットインターフェイス上に常に「情報が正しいかを確認してください」と表示しているわけです。
生成AIのこの予測不可能な出力という性質は、法的責任の観点からも重要な課題を提起しています。従来型のITシステムや予測AIとは異なり、生成AIの出力は開発者の意図を超えて多様な可能性を持つため、その法的責任の所在をめぐって新たな検討が必要となっています。
生成AIが社会に普及していくにつれて、生成AIの出力が社会に与える影響は、次第に大きくなってきています。
例えば、企業が顧客対応に生成AIを導入した場合、生成AIが予期せぬ回答をすることで取引上の約束と解釈される可能性があります。また、製品の設計支援に生成AIを活用した際、その出力に基づいて設計した製品に不具合が生じた場合の責任の所在も問題となります。
しかし、我々はここで大きな問題に直面することになります。生成AIには人間のような法的責任能力を認めることができないという問題です。これは単なる技術的な制約ではなく、法制度の根幹に関わる重大な問題と考えます。
むしろ、先ほど述べたようなハルシネーションの課題のようなものは完全に防ぐことはできないとしても、徐々に技術の発展や活用方法を限定することで抑制できる見込みがたちますが、生成AIに責任担当能力がないという問題は技術では解決できない問題であるためより深刻です。
生成AIは、人類がこれまで直面したことのない特異な存在です。従来の道具や機械とは異なり、自律的な判断と意思決定が可能でありながら、その決定の主体となる自己が存在しないという矛盾を持っています。
法的責任能力の核心は、自己の行為の結果を認識し、その善悪を判断できる能力にありますが、生成AIは高度な判断を行えるものの、これらの能力を真の意味では持ち合わせていません。生成AIは与えられたデータから確率的な出力を生成し、学習した規則に従って判断を行い、モデルの更新によって性能を向上させることはできます。しかし、これらは全て外部から与えられた枠組みの中での動作であり、真に自律的な主体としての判断や改善を行っているわけではありません。
生成AIがもたらす法的責任の問題は、民事責任と刑事責任でその対応が大きく異なります。民事責任は損害の填補を目的とするため金銭的解決が可能である一方、刑事責任は行為者の主観的責任を問う性質上、生成AIへの適用は本質的に困難であると考えられます。それぞれの領域における課題と対応について見ていきましょう。
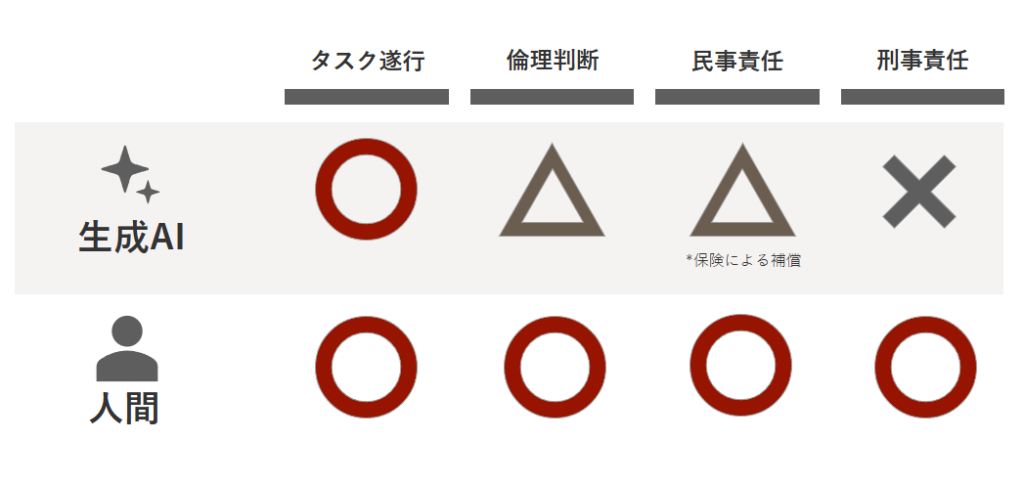
民事責任の領域では、金銭的な賠償制度を通じた対応が一定程度可能です。
具体的には、生成AIの利用に伴うリスクについては、損害保険や業界での共済制度などによる対応が考えられます。例えば、AIによる判断ミスや予期せぬ出力がもたらす第三者への損害を補償する仕組みを整備することが可能です。
一方、刑事責任の問題は、より根本的な課題を提起します。刑事責任の本質は違法行為への社会的非難と行為者の更生にあり、行為者の主観面(故意・過失)が重要な要素となります。しかし、前述の通り生成AIには真の意味での主体を認めることができず、これらの概念を適用することは困難です。
企業活動において生成AIの利用が刑事責任に関わる場面としては、例えば機密情報の漏洩や不正取引への関与などが考えられます。このような場合、最終的な判断と責任は必ず人間側が負うという認識を組織内で共有することが重要です。システムの設計・運用に関わる開発者や、システムの使用を決定する経営者などが責任主体となり得ます。
この責任の所在の明確化は、人間による適切な管理の必要性と人間の監督能力や賠償能力を超える自律性をAIシステムに付与すべきでないという示唆を含んでいます。これは法的責任を通じた社会システムの安定性維持のためには欠かせない視点になると考えています。
現在は、上記の問題を解決する生成AIに関する新たな法的枠組みは確立されていないため、生成AIがもたらした結果については、必然的に人間側がその責任を負うことになります。具体的には、その責任は以下のいずれかに帰属することになると考えられます。
この責任の所在をどちらに置くかという選択は、生成AIサービスの市場構造を規定する重要な要因となります。事業者が責任を負う場合、サービスの自由度は制限されますが、利用者は安心してシステムを活用できます。一方、利用者が責任を負う場合、より大きな自由度が得られる代わりに、出力の検証や管理を自ら行う必要が生じます。
このように、品質責任の担保には相応の負荷が発生するため、ビジネスコンテキストに応じてその負荷を軽減する仕組みが求められることになると考えられます。その結果、現在のような汎用的なチャットサービスやAPIサービスの提供形態に加えて、特定の用途や業務に特化した形でのコンテキスト統合型のサービスが展開されていくことが予想されます。
上記のように、法的責任の分配の問題は、生成AIサービス市場における競争構造を理解する上で核心的な要素となってくると考えられます。
生成AIサービスがなぜ免責されるのか、生成AIの出力の法的責任はどこに帰属するのかを議論する中で、二つの本質的な軸が浮かび上がってきました。それは、「品質責任の所在」と「コンテキストの統合度」です。
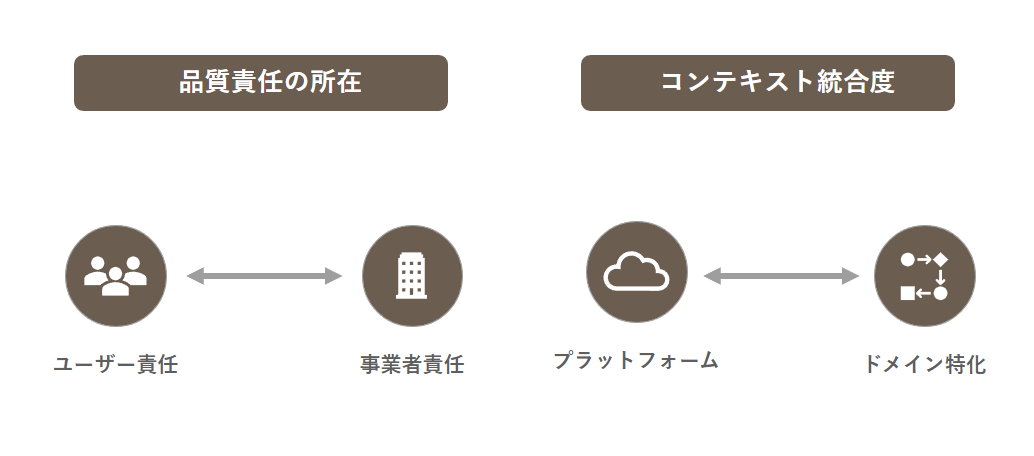
品質責任の所在という軸は、生成AIの予測不可能な出力に対する品質担保のコストを誰が負担するかを示しています。この責任を担うためには、生成AIの確率的な振る舞いを深く理解し、適切な制御を行うためのデータサイエンスの知見が求められます。
コンテキストの統合度は、生成AIを実際の業務プロセスに組み込み、効率的に運用するための実装負担を誰が担うかを示しています。この統合を実現するためには、システムやプロセスを設計・構築するエンジニアリングの知見が求められます。
品質責任の軸では、ユーザー責任型と事業者責任型という二つのタイプに分けることができます。先ほども言及しましたが、ユーザー責任型では、出力の品質担保はユーザー側で行う必要があり、より大きな自由度と引き換えに、出力の検証や管理の責任をユーザーが負うことになります。
一方、事業者責任型では、サービス提供者が品質を保証します。自由度は制限されますが、出力の信頼性に対する責任を事業者が引き受けます。
| 特性 | ユーザー責任型 | 事業者責任型 |
|---|---|---|
| 品質担保のアプローチ | ユーザー自身による検証と管理 | 事業者による品質保証と管理体制 |
| コスト構造 | 低コスト(APIコスト中心) | 高コスト(品質管理コストを含む) |
| スケーラビリティ | 極めて高い(技術的制約のみ) | 品質管理能力による制約あり |
| 参入障壁 | 低い(技術的参入が容易) | 高い(品質管理能力が必要) |
| 利用の自由度 | 高い(制約が少ない) | 限定的(品質管理のための制約あり) |
| 競争優位の源泉 | 価格と利便性 | 品質と専門性 |
実際の生成AIサービス市場では、これら二つのタイプの間で、用途や顧客ニーズに応じてさまざまな中間的な形態をとってサービスが投入されると考えられます。
この軸では、プラットフォーム型とドメイン特化型という二つのタイプに分けることができます。プラットフォーム型は汎用的な機能を提供し、どのように活用するかはユーザー側で自由に設定できます。広範な用途に適用可能である一方、特定用途における出力の制御は難しくなります。
これに対してドメイン特化型は、特定のコンテキストに深く組み込まれ、出力が特定の用途に最適化されています。適用範囲は限定的になりますが、その領域における制御性と価値提供の深さは極めて高いものとなります。
| 特性 | プラットフォーム型 | ドメイン特化型 |
|---|---|---|
| コンテキストの範囲 | 汎用的で幅広い文脈に対応 | 特定領域の深い文脈理解 |
| コスト構造 | スケールメリットが働きやすい | 専門性に応じたコスト構造 |
| カスタマイズ性 | ユーザー側で実施が必要 | システムに組み込み済み |
| 導入の容易さ | 容易 | 複雑 |
| 進化の方向性 | 汎用性の向上と基本性能の改善 | 特定領域における専門性の深化 |
| 競争優位の源泉 | 利便性と豊富な利用事例 | 専門的な知見と実装経験 |
実際の生成AIサービス市場では、産業に特化したサービスや機能を統合したサービス、業務プロセスを統合したサービスなど複数の観点でドメイン特化したサービスが投入されると考えられます。
では次に、「品質責任の所在」、「コンテキスト統合度」の二つの軸を用いて生成AIサービス市場を4つの異なる市場に分割し、それぞれの市場の競争構造を分析していきたいと思います。なお、今回は象限ごとの市場の概要について触れるにとどめ、詳細な内容については次回以降、それぞれの市場を取り上げながら深く考察していきたいと考えています。

この象限は、生成AIモデルの推論能力を最も純粋な形で提供する市場です。技術的な制約が少なく、生成AIの柔軟な推論能力を最大限に引き出すことができる一方で、その予測不可能性により品質担保が原理的に困難という特徴を持ちます。
SaaS型のAIアシスタントを中心とした市場です。業務プロセスやUXとの統合により、業務や業界固有のコンテキストに配慮しユーザーが効率的に作業できるように支援します。また、入力や出力の形式を固定化することでユーザーの品質確認のための負荷を下げるような機能統合を行うことで価値を訴求する場合もあります。最終的な品質の確認をユーザーに委ねることになるため、ユーザー毎の課金形態になることが一般的な市場です。
生成AI利用のための品質管理プラットフォームを提供する市場です。生成AIの予測不可能性に対して、プラットフォーム側で包括的な管理機能を提供することが特徴です。
特定業務向けに最適化された生成AI機能を、品質保証付きで提供するドメイン特化型ソリューションの市場です。固有の業務に根ざしたコンテキストによる制御と事業者による品質保証の両方を備えることで、生成AIの予測不可能性を最も強く制御します。
最終的な出力を人間が確認しなくても業務プロセスを遂行できるように品質管理を行うため、AIエージェントによる知的労働の水平展開が可能となります。
本稿では、生成AIサービスがなぜ免責されるのかについて解説を行った上で、品質責任の所在とコンテキスト統合度という二つの軸の特徴を整理し、その二つの軸によって分割される4つの市場の概要について解説しました。次回以降は、それぞれの市場についてより詳細な考察を行なっていきますのでご期待ください。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説

















