



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

近年、生成AIの開発競争が激化し、新たなビジネスモデルが生まれつつあります。目まぐるしく進化するテクノロジーは、私たちの社会をどのように変えようとしているのでしょうか?
この記事では、ブレインパッドの技術系執行役と同社フェローが、それぞれが注目する技術の最新動向を語り合い、AIやDXの現状や将来性を深掘りし、私たちの生活やビジネスにどのような影響を与えるのかを考察していきます。
【関連記事】
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例
DX(デジタルトランスフォーメーション)とは?その意味や今なぜ求められているか、わかりやすく解説


株式会社ブレインパッド・角谷 督(以下、角谷)私はブレインパッドのフェローとして、最新技術の動向や研究領域の社内外の情報流通を主に担っております角谷です。
シリーズでお届けしている『ビジネスを取り巻くAI・DXの現状と未来』の2回目となります。今回は、ICLR2024に参加した弊社社員とAI技術に関して議論した内容についてお話したいと思います。山崎さん、よろしくお願いします。
株式会社ブレインパッド・山崎 清仁(以下、山崎)よろしくお願いします。私はXaaSユニットを統括しております上席執行役の山崎です。私は、Rtoaster(アールトースター)を中核にしたプロダクト事業を技術面から支え、サービスの開発や安定した運営を担っております。
今回は技術トレンドを中心にお話しできればと思います。AI全体として研究の発展や流れという観点では、角谷さんはICLR2024を通じてどのようなことに気づかれましたか?
【参考】
ICLR2024:https://iclr.cc/Conferences/2024
ICLR2024 Fact sheet:https://media.iclr.cc/Conferences/ICLR2024/ICLR2024-Fact_Sheet.pdf
角谷 ICLRでは、面白い研究や応用系で考えさせられる研究も多くありました。AI研究の注目分野という観点でお話しますと、まず、研究発表数※では以下のグラフのような分布となっていました。(図1参照)
※ 研究発表数は、ICLRの口頭発表に限定した数字です。技術領域、技術課題のカテゴリ名は弊社によるものです。
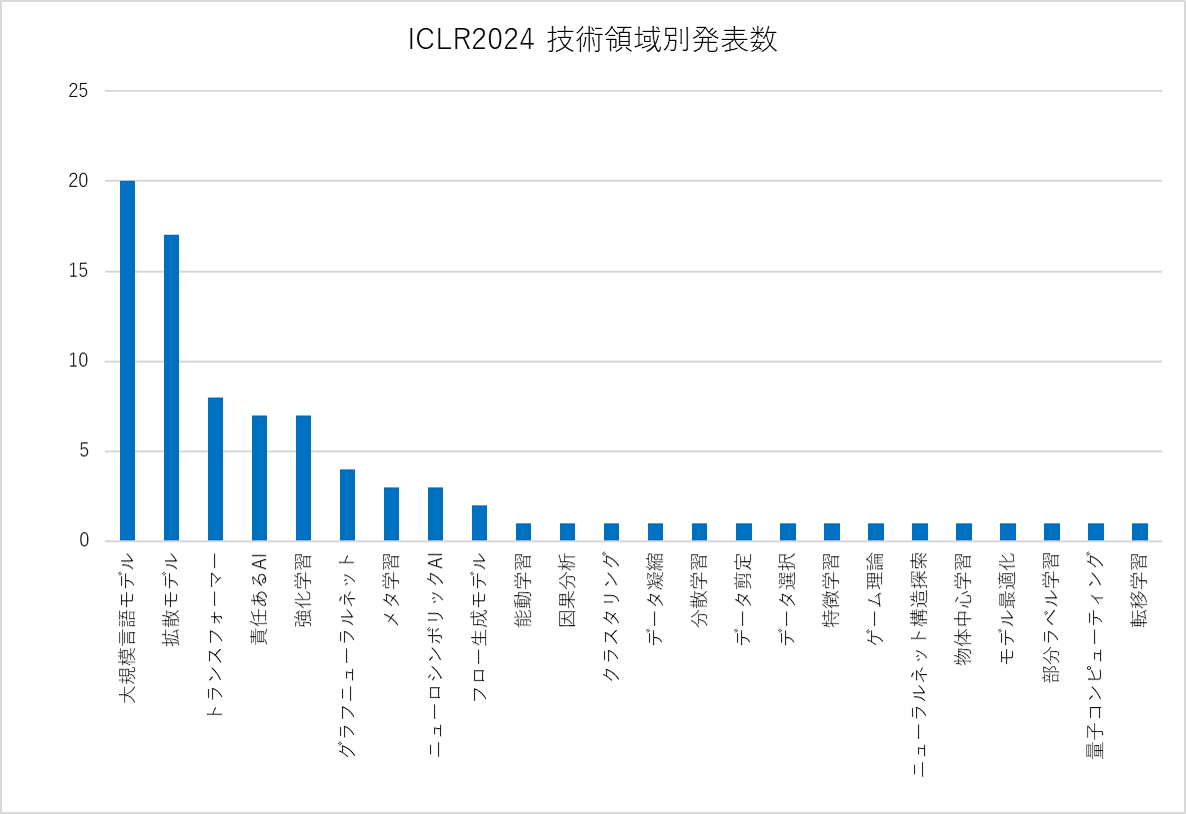
グラフが示す通り、昨今の生成AI技術の急速な進歩に応じて、「大規模言語モデル(LLM)」と「拡散モデル」の件数が群を抜いています。次に論文数の多いグループとして、「トランスフォーマー」「責任あるAI」「強化学習」が続いています。トランスフォーマーはLLMとも関係しますが、研究内容では言語モデル以外での応用が盛んになっています。
責任あるAIは、説明可能性といったユーザーにとっての分かりやすさや公平性のように実用的かつ社会的課題にこたえるために重要な技術ですので、AIが社会実装されつつある現在、今後より重要になってくると考えています。
山崎 前回のエントリで、当社が力を入れるとおっしゃっていた分野(LLM及び拡散モデル、強化学習)が上位にランキングされているということですね。
角谷 そうですね。図1の上から8番目にある「ニューロシンボリックAI」は「推論型AI」を実現する技術であり、こちらも比較的上位の研究テーマとなっています。また「責任あるAI」を実現する上でも重要な技術です。現在活用されているAIでは、取得された情報から文脈に適した回答を提案・提供するテキストを文法的に正確に返すというものです。
「責任あるAI」では高度な推論で複雑な問題を解決すること(推論型AIで実現できる)や、さらに進んでユーザーによる継続的な情報の入力やフィードバックが無くても、事前定義されたルールや経験から自律的に学習することで意思決定を行うことができることになることが求められています。
山崎 図1からも様々な技術領域があることはわかりました。では、社会実装という観点で見た場合、どのような研究が実際に使われているのでしょうか。
角谷 もちろんすべての応用例を知っているわけではないので、今のご質問に正確に答えることは難しいのですが、比較的多く使われていることが実用段階にあると考えるなら、AIの各技術領域と実用化までの年数の関係はおおよそ以下の図2にマッピングした通りだと思っています。
ここでいう実用化というのは、潜在的な需要を考慮したときに概ね利用されているという状態を考えています。これは当社の技術領域に詳しい何人かの社員と議論した結果のものとなっていますので、絶対的に正しいものでないことはご了承ください。

山崎 「責任あるAI」は比較的実用化が近く、「ニューロシンボリックAI」の実用化はかなり先に見えます。このあたりは、どのように考えていますか。
角谷 簡単な推論型のAIは多くの研究がなされており、それらはLLMで課題となっている倫理的に問題のある回答などを避ける技術としては有用だと思います。高度な推論型AIにはニューロシンボリックAIや自律型エージェントの技術が必要となってきますので、究極の「責任のあるAI」の実用化は先の話となりますが、LLMが普及しつつある現在、高度な技術が確立されていなくても、世の中の要請によって実用化に向かっていると考えています。
例えば、「機械学習やディープラーニングを解釈する技術」なども責任あるAIの1つですし、それらが倫理や公平性に反していないかどうかをその解釈から判断することもできます。一方、我々としても簡単な推論型AIに関する技術はキャッチアップしておく必要があると思っています。
山崎 公平性というのは、例えば性別など本人が変更できない属性によってサービスが異なるようなAIは倫理的に問題があるということですよね。AIや機械学習がもたらす回答が、どのようにデータを扱ってその回答を返したのかを解釈させて、それが倫理的に問題ないかを判断させるのは、ユーザーが介在して行うこともできるが、それを自律的に機械に学ばせたりすることができるのが理想ということですね。
角谷 高度な技術が確立されて広く使われていくという状態に達するのは、比較的時間が掛かります。技術領域からもう少し踏み込んで、技術課題という観点で研究発表数※を見ると、異なった景色が見えるかもしれません。
次の図3、図4が技術課題ベースで見た場合の発表件数と実用化年数の関係図になります。
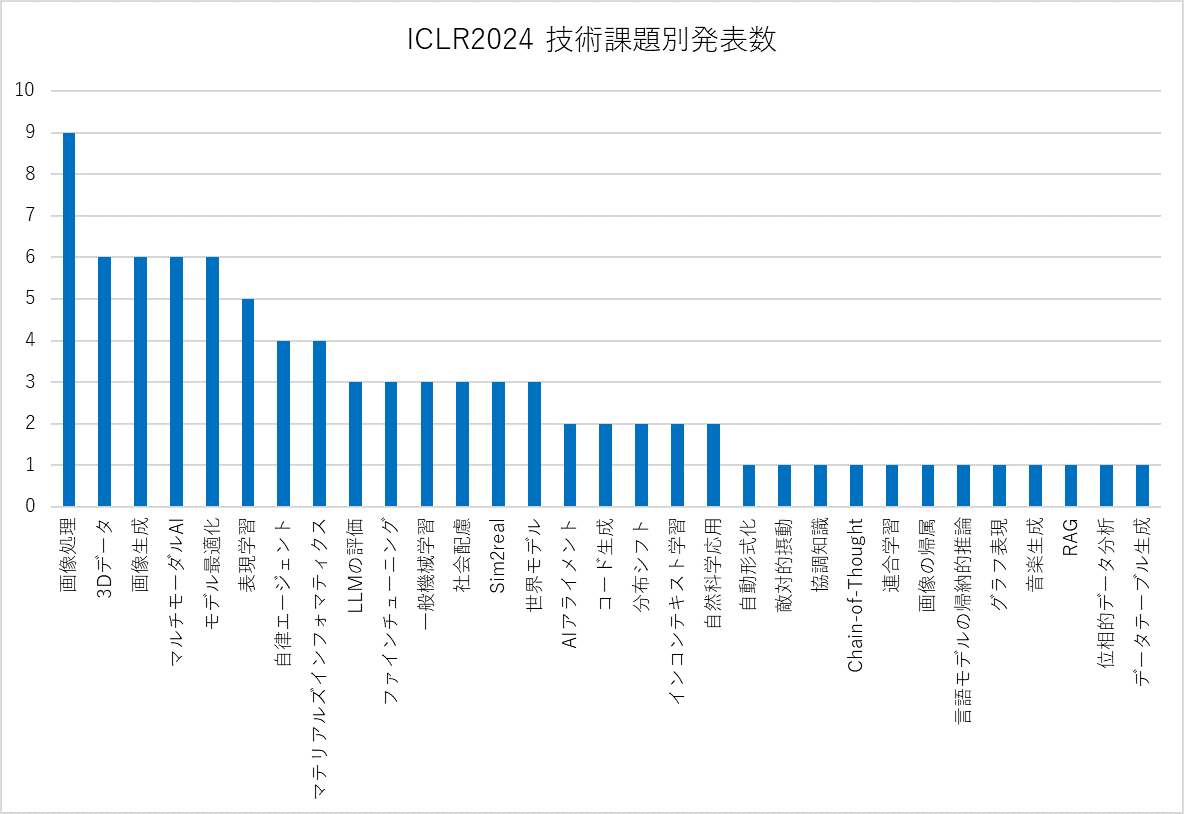

角谷 インコンテキスト学習や画像生成、マルチモーダルAIやそれに伴う表現学習などが現在盛んに研究されていて、実用化されつつあると思います。
山崎 インコンテキスト学習について説明してもらえますか?
角谷 特に大規模言語モデル(LLM)における学習方法の一つで、モデルが与えられた入力のコンテキストに基づいて新しいタスクを理解し、適応する能力を獲得することでしょうかね。これによってLLMなどでもプロンプトで回答例を幾つか与えることで、正確な答えが返ってくるようになります。
山崎 なるほど。One-shot promptingやFew-shot promptingなど、入力を工夫することでモデルの精度が上がるということですね。マルチモーダルAIとは、異なる種類の情報をまとめて扱うAIという理解ですが、そこでの表現学習にはどのようなものがあるのでしょうか。
角谷 画像、音、自然言語、時系列データなど、現在は色々なデータを取得することができます。ある分析対象に対して、画像と音、それに関わる自由記述された文章があった場合、単独で分析するよりも、それらを総合的に分析したほうが有用な情報を得られそうですよね。そのために特徴量をそれぞれの種別のデータごとに抽出・設計する必要があるのですが、これをコンピュータで自動に学習し、学習で獲得した特徴表現を使って目的のタスクを実行させるための試みが表現学習ということになります。
山崎 現代では、色々なセンサーから様々な形式のデータが取得できるようになっているから、そのような技術の研究が盛んになっているということですね。前回、出てきた生成AIの回答の妥当性に関する研究も盛んなのでしょうか。
角谷 LLMなどの生成系AIの回答の妥当性やポリティカルコレクトネスに関する正誤判断は、明確に機械的な解を与えることが難しいです。そのため、LLMの評価自体もひとつの重要な技術課題として研究されています。
また、評価以前に、誤った回答をしないことも重要なので世界モデルなども研究されており、これらの技術が独立しているわけではありません。ですから、図3の技術領域としてあらわされている「責任あるAI」における技術課題としてはLLMの評価や世界モデルなどが関係してきますし、技術領域としてプロットされた「ニューロシンボリックAI」の技術課題のひとつであるAIアライメントなども関係します。
山崎 各技術課題を解決するための技術が複雑に絡み合っているということですね。
角谷 そういうことになります。これらの様々な領域にわたる技術を少人数ですべてカバーすることは現実的ではないと思われます。そのため、多くのデータサイエンティストが自身の興味や関心、強みを活かして広く技術領域をカバーしていくことが重要となりますね。
山崎 データサイエンティストのカバー領域も広くなり、大変な時代だと感じます。比較的ホットで重要なテーマを、当社がリサーチに力を入れていく領域としたのは理解しましたが、具体的な選定基準はありますか?
角谷 はい。大きく2つの基準を設けて選定しています。1つ目は研究動向、および技術の発展性・汎用性を踏まえて、以下の4つの技術領域のいずれかを含んでいることです。
そして、2つ目が社会的ニーズ、当社の得意領域を踏まえて、以下の5つの技術課題のいずれかに関連していることです。
つまり、実際にニーズのある課題と関連する技術のクロスで研究テーマを選んでいます。
山崎 具体的な研究テーマとしてはどのようなものが候補として挙げられているのでしょうか?
角谷 具体的な研究テーマとしては強化学習になります。需要予測などのマーケティング分野、最適化問題などと関連があり、重要な技術領域だと考えています。
山崎 ありがとうございます。今回は技術動向全般についてみてきましたが、次回は「強化学習」が需要予測や最適化問題にどのように関係するのか、強化学習を用いて何を解こうと考えているのかについてお話できればいいですね。
角谷 はい。その内容でお話ししたいと思います。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説















