



メルマガ登録
-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

近年、生成AIの開発競争が激化し、新たなビジネスモデルが生まれつつあります。目まぐるしく進化するテクノロジーは、私たちの社会をどのように変えようとしているのでしょうか?
この記事では、ブレインパッドの技術系執行役と同社フェローが、それぞれが注目する技術の最新動向を語り合い、AIやDXの現状や将来性を深掘りし、私たちの生活やビジネスにどのような影響を与えるのかを考察していきます。

株式会社ブレインパッド・山崎 清仁(以下、山崎)私はXaaSユニットを統括しております上席執行役の山崎です。私は、Rtoaster(アールトースター)を中核にしたプロダクト事業を技術面から支え、サービスの開発や安定した運営を担っております。シリーズでお届けしている『ビジネスを取り巻くAI・DXの現状と未来』の3回目となります。角谷さん、よろしくお願いします。
株式会社ブレインパッド・角谷 督(以下、角谷) 私はブレインパッドのフェローとして、最新技術の動向や研究領域の社内外の情報流通を主に担っております角谷です。よろしくお願いします。今回は、強化学習の適用が考えられる領域はいろいろありますが、需要予測と最適化問題を取り上げ、そこで強化学習がどのような役割を果たすのかをお話ししましょう。
山崎 需要予測というと、多くの企業が興味を持たれている分野ですね。ビジネスでは、仕入れや生産量、安全在庫量の決定に繋げるためには予測をもとに最適化することが必要となりますが、実用面では、どのような課題が見受けられますでしょうか。
角谷 お客様は、適切な安全在庫の決定には期待値予測の精度が良ければ、十分であると考える傾向になります。しかし、実際には在庫コストや廃棄コストがかかる場合は、それぞれの発生確率やそのコストの大きさが重要になってきます。在庫コストと廃棄コストに差がある場合、利益を最大化するには需要量の予測値がと最適な仕入れ量とはならず、廃棄コストや在庫コストが大きければ、テールリスク(思わぬ大きなコストが発生するリスク)が発生してしまいます
山崎 具体的に示していただけるとわかりやすいのですが。
角谷 単純な例ですが、図1をご覧ください。上のグラフが期待需要の分布図で、中央の点線が期待需要量を表しています。機械学習やAIでは、この期待値の予測を試みるわけです。
分布図は、期待値(ここでは予測値とする)を中心に横軸に予測誤差、縦軸がその出現頻度を表しています。予測値より右側は需要量が期待値よりも大きいので在庫不足となり、左側では在庫余剰が発生していることを意味します。図1の下のグラフが損失額を表しており、在庫不足の時は機会損失、余剰の時は廃棄コスト(もしくは保管コストなど)が生じます。ここでは、グラフの右側の損失額が、左側の損失額よりも大きいので、機会損失の方が顧客にとってはリスクが大きいことがわかります。
山崎 なるほど。つまり、期待値よりも多めに商品を用意するほうが大きな損失を被らなくてもよいということになりますね。
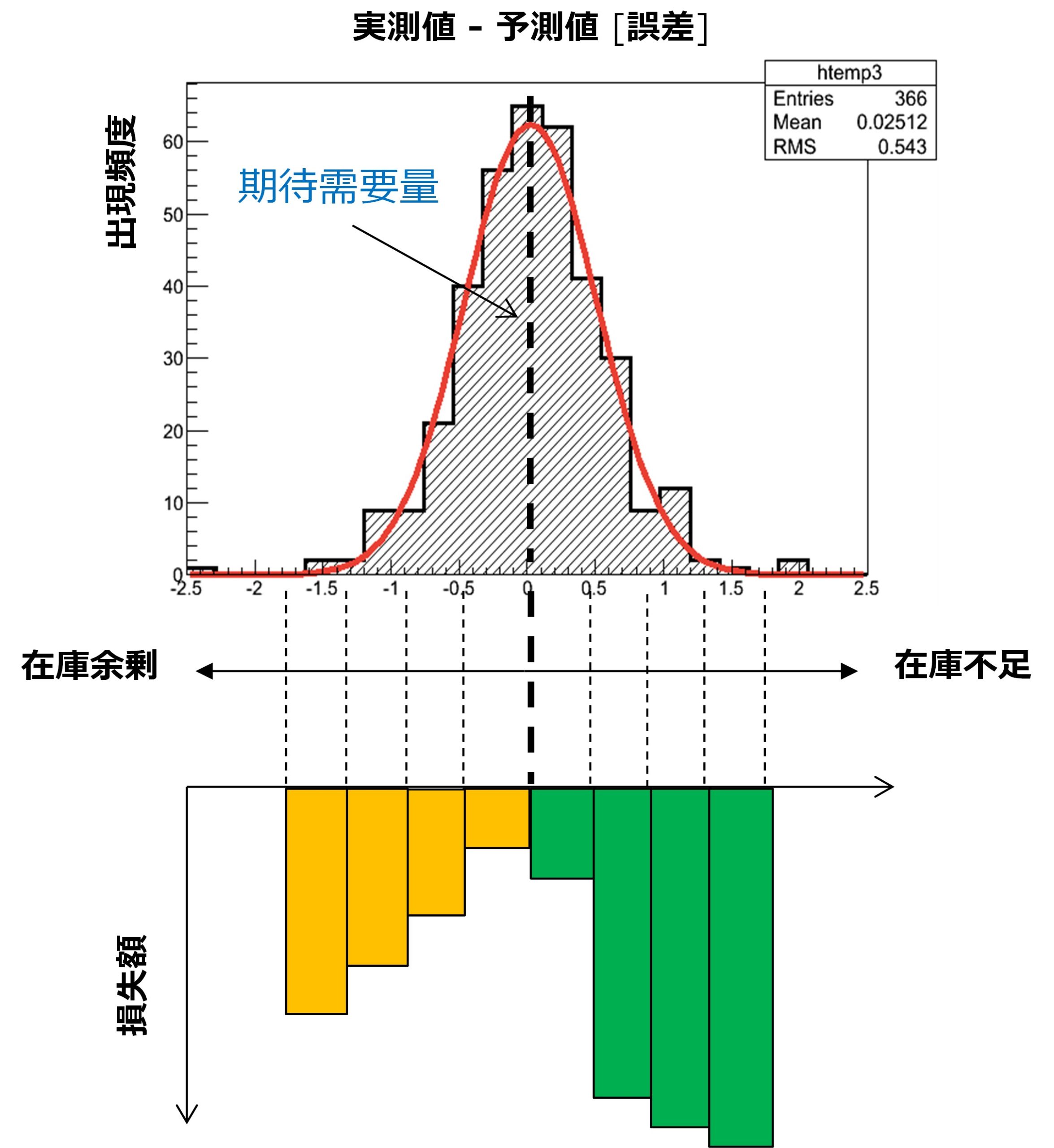
角谷 損失額の期待値を最小にするという意味での最適化では、そのようになりますね。簡単な数値例を図2で示します。

角谷 需要量の想定分布が得られれば、発生する在庫コストと機会コスト、それぞれの発生確率が計算できるので、損失額を最小化する仕入れ量を算出することができます。
ただ、実際の需要量が期待値と大きく異ならなければ、損失額はそれほど大きくはないですが、右端のような極端な需要が生じたときは、思わぬ大きな損失額を被ることになってしまいます。そうすると、意思決定者は期待値だけを意識するのではなく、テールリスク(分布のすそ野の値が実現されたときのリスク)を考える必要があるのです。
山崎 確かに、在庫不足や余剰が生じたとしても、一定量までは追加発注や返品が可能である場合など、どちらかというと分布のすそ野のリスクを考えるのが重要なケースもありそうですね。
角谷 動的な最適化ではないのですが、意思決定者の効用として、期待リスクを一定以下という条件のもとで、テールリスクを最小化するようなCVaR(特定の信頼水準(通常95%または99%)を超えた場合に発生する損失の期待値)などのテクニックも金融業界などでは活用されています。このような課題に対して、強化学習はより柔軟で、需要が徐々にシフトしてしまうような問題にも対処できるというのがメリットです。
角谷 上述した例は非常に単純ですが、実際には複数の商材が存在します。ある予算制約の中で、どの商材をどれくらい仕入れれば適切なのかということは、多くの企業が直面する課題です。前述したように、予測値が最適な仕入れ量と一致しないので、シナリオ毎に報酬を与えて効用(利益額の総和を最大とする各商材の仕入れ量)を最適化したいというニーズに加え、期待値がある確率でレジームシフト(ある状態から異なる状態への急激な構造変化)が生じたりするのが現実です。そのような遷移確率自体が変化してしまうような場合、その環境変化に応じて探索的に学習できる強化学習は、このような課題を解決する方法として適していると思います。
山崎 そのような場合に強化学習が有効な解決手段となるということですね。期待値のレジームシフトはよく見られる現象でしょうか。
角谷 GDP や短観、鉱工業生産指数、景気動向指数などは状態が非線形にジャンプすることがあり、景気の局面変化を表すための統計モデルとして、レジームスイッチングモデルが用いられたりします。
モデルの基本的な考え方としては、対象とする指標の変化率が、景気の拡張期と後退期のような局面で異なる値をもつとします。景気の局面転換が生じると、転換の都度、現実に観測される変化率は確率的に上下にジャンプします。このようなマクロ経済の変化は、商品需要などにも影響を与えると考えます。お客様の実際の需要量データを示すのはここでは難しいので、一般的な金融市場の株価収益率のデータでお見せします。
前提
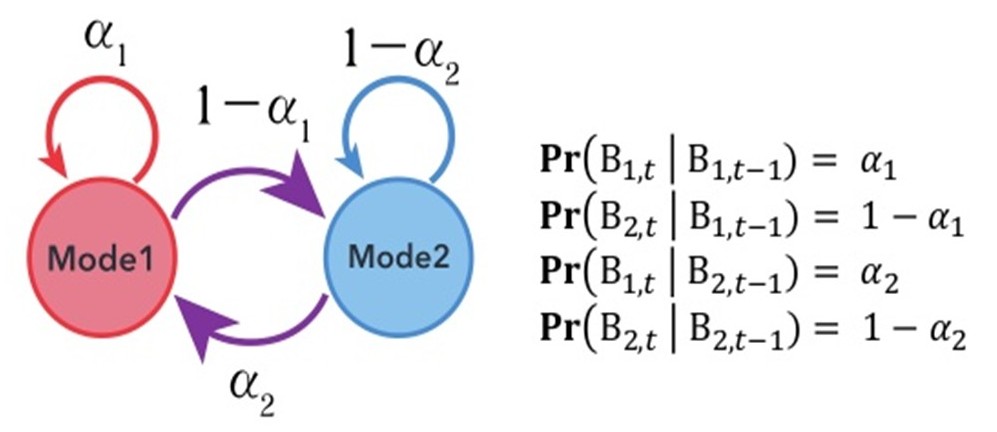
\(B_i,_t\)は\(t\)時点で\(Mode i(i=1\)または\(2)\)であることを表し、\(B_1\)から\(B_2\)、\(B_2\)から\(B_1\)にシフトする確率はそれぞれ\(1-α_1、α_2\)です。
このようなモデルを仮定して、TOPIX(東京証券取引所1部上場企業の時価総額指数)の月次収益率(1980年1月から2012年6月)のデータに関して推定すると、以下の通りとなります。

平均がシフトすると、分散の水準も異なる水準にシフトしています。また、状態がシフトする確率は低いですが、その後は一定の持続性が観察されます。株価収益率は需要量とは異なりますが、マクロ環境の変化によって、このような分布のシフトはそれなりの頻度で観察されることが多いですね。
山崎 なるほど。このようにマクロ経済に変化が起こると、商品需要のトレンド自体が変わってしまうということですね。ここで示されたような期待需要量の分布の変化に対して、最適な意思決定をする上で、強化学習のアルゴリズムが有効ということだと思いますが、強化学習のアルゴリズムを簡単に教えてもらえませんか。
角谷 強化学習のアルゴリズムを図で示すと、以下のようになります。(図5参照)

「エージェント」は強化学習を行う当事者のことです。次のループの中で、最適な行動を学んでいきます。
エージェントはポリシー(政策)を選択し、それに応じたアクション(行動)を環境に返します。結果、エージェントの状態が更新されると同時にポリシーに対して報酬が与えられます。意思決定者は様々なポリシーを選択することが出来ますが、上記のループの中で最終的に得られる報酬和が大きいポリシーが最適解と考えられます。
例えば、図4で示したレジームスイッチ構造がある株式市場において、エージェントを投資家として強化学習の枠組みを考えてみましょう。ここでは、エージェントのアクションとしては、{投資する、投資しない}の2通りが選択できるとします。報酬は、市場から得られる収益率とします。このケースでは、下記の図6のように表されます。
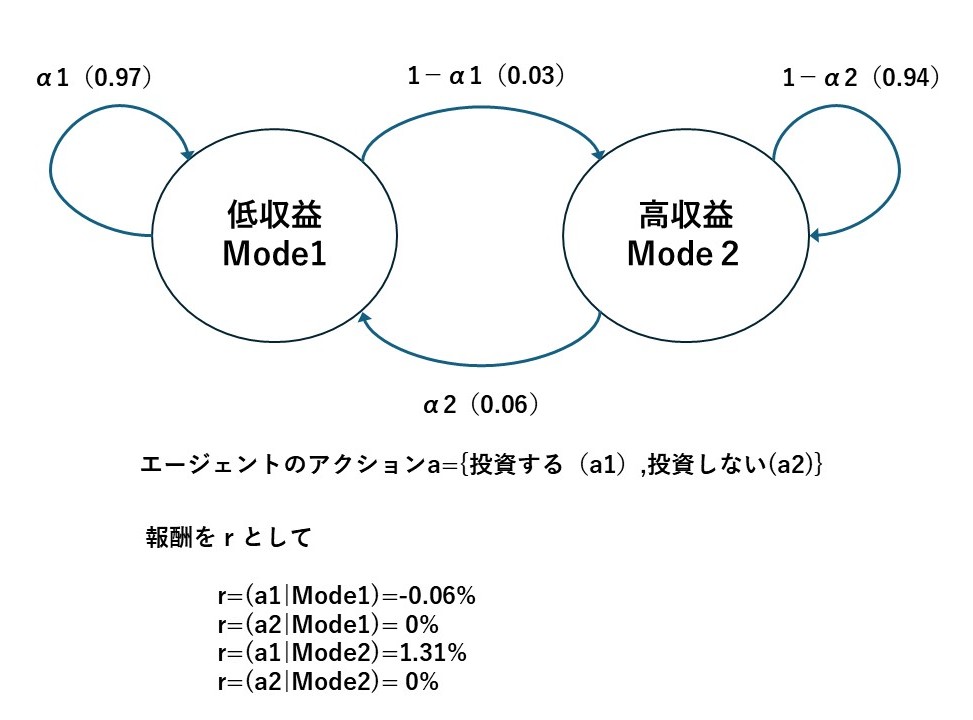
シンプルにするとこのような構造を仮定して、エージェントのアクションを最適化する(高収益なら投資して、低収益なら投資しない)方策を学ばせるのが強化学習です。
一般的には、エージェントのアクションが状態の推移に影響を与えますので、もっと複雑なモデルとなります。例えば、上記は株価収益率の例ですが、好景気、不景気の2状態を定義して、エージェントが政策金利の「上げ」、「下げ」をアクションとして選択し、アクションが景気に影響を与えるような状況を考えられます。報酬が好景気の時に多く与えられるような枠組みとすれば、強化学習は下記の図7のように表現されます。
()内の数値は(アクションが与えられた時の遷移確率、報酬)を表す。
例えば、図の左上の(0.4、+1)は好景気のときに金利を上げると0.4の確率で好景気が継続し、報酬が1であることを表す。
\(α、β\)が最適化されるポリシー。上記の場合、好景気では金利を下げた方が好景気が持続する確率が高く、不景気では金利を下げた方が、好景気に状態が移行し易い。また、好景気になる方が報酬が高いため、最適化すると\(α=0\)、\(β=1\)となる。
実際には、経済成長とトレードオフの関係となる傾向のインフレ率も考慮する必要があるでしょうし、社会科学では様々な経済活動が影響を及ぼし合うので単純なモデリングは難しいですが、強化学習のイメージはこの例でお伝え出来るかと思います。
山崎 制御するべきパラメータが多く、実現される状態によって効用が複雑に変化する場合は一般的な数理最適化問題では解くのが大変そうですが、それに対して、強化学習は複雑な環境でも柔軟に表現できそうなアルゴリズムですね。
角谷 そうですね。環境の状態とアクションを前提とした条件付き確率で、次の環境状態が与えられることになりますが、モデリングを工夫することで、この条件付き確率も定常や時変の場合も扱うことが可能です。
山崎 静的な学習だけではなく、環境の変化にも対応できるというのが特長ということですね。
角谷 また、強化学習の枠組みでモデルフリーなQ学習という手法もあり、環境に関する事前知識が無くてもエージェントが新しいデータを逐次的に学習して即座に行動を変更することも可能です。需要水準がシフトしてしまい、新たな未知の環境になったとしても現在最適と考えられるポリシーと新しい行動の探索のバランスを取りながら、未知の環境に適応できます。
山崎 単純な例で教えて頂きましたので、強化学習が非常に魅力的なツールであるということがわかりましたが、今後、どのような分野で活用されていくと考えていますか。
角谷 強化学習は、自由度が高い手法のため、非線形システムの制御に向いています。また、たくさんのパラメータを扱う大規模な組み合わせ問題に対しても進化的手法(遺伝的アルゴリズムなど)の代替として活用できると思います。現在の報酬だけでなく、将来の報酬も考慮に入れて最適化するため、多期間最適化問題にも適していますね。
具体的には、
などです。
山崎 このように具体的に挙げて頂いた適用分野をみると、応用できるテーマはたくさんありそうですね。角谷さんのチームでは、現在どのような課題を中心に研究を進めているのでしょうか。
角谷 サプライチェーンにおける中間財の数量最適化をテーマとした研究が始まっています。中間財は、前工程と後工程が存在し、それらの状況変化に影響を受けるため、環境変化が生じます。そのため、静的な最適化よりも強化学習が適していると考えています。
山崎 それは楽しみですね。今回、最適化を例に強化学習についてお話ししてきましたが、意思決定をする上で、初学者の意思決定者が注意しないといけないことについても知りたいですね。
角谷 それでは次回は、データ分析や最適化などにおけるデータの見方、分析方法などに関して、陥りがちな落とし穴となるような事例についてお話ししましょう。
あなたにオススメの記事

2023.12.01
生成AI(ジェネレーティブAI)とは?ChatGPTとの違いや仕組み・種類・活用事例

2023.09.21
DX(デジタルトランスフォーメーション)とは?今さら聞けない意味・定義を分かりやすく解説【2024年最新】

2023.11.24
【現役社員が解説】データサイエンティストとは?仕事内容やAI・DX時代に必要なスキル

2023.09.08
DX事例26選:6つの業界別に紹介~有名企業はどんなDXをやっている?~【2024年最新版】

2023.08.23
LLM(大規模言語モデル)とは?生成AIとの違いや活用事例・課題

2024.03.22
生成AIの評価指標・ベンチマークとそれらに関連する問題点や限界を解説
















